
Back to Basics | March 2015 Hearing Review
By Marshall Chasin, AuD
If you look in any textbook, soft speech is generally made up of the higher frequency consonants—also called obstruents if you happen to be a linguist. Sounds such as /s/, /sh/, /f/, and /th/ are the typical culprits. Indeed, the sound level of these quieter speech sounds is on the order of 40-50 dB SPL, whereas vowels and nasals can be on the order of 75-80 dB SPL. For any given hearing loss, hearing aids typically provide less amplification for the higher level sounds, and more for the soft speech sounds.
So far so good, but what about sounds at the beginning of a sentence versus sentence final sound elements?
When we first utter a sentence, we have a lung-full of air ready to expel our wisdom to the world. However, by the end of the sentence, the sound level of our voice is quite reduced—a sentence initial vowel /a/ as in “father” is at a much higher level than that same sound at the end of a sentence.
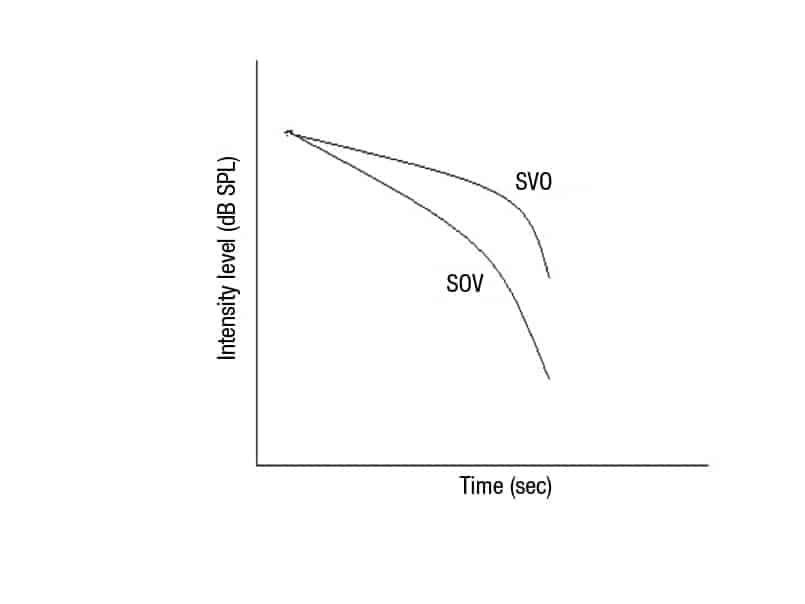
Figure 1. A stylized graph of how the speaking level naturally falls off as we utter a sentence. The right side of the graph is related to less residual lung volume commonly observed at the end of the sentence. Subject-Verb-Object (SVO) languages, such as English, have a sentence final object or important noun that contributes to an increased speaking level. In contrast, Subject-Object-Verb (SOV) languages, such as Hindi or Japanese, have no such sentence-final saving grace. In these languages, sentence final sounds should be considered to be “soft speech.” (Adapted from Chasin 2012.)
In English and many other Indo-European languages (eg, French, Spanish, Portuguese, Italian, Greek, and Russian), there is a saving grace. These are languages with a Subject-Verb-Object (SVO) word order: Mary saw Tom (Mary is the Subject; saw is the Verb; and Tom is the Object). Since objects, such as nouns and names of things, tend to be louder than verbs and other helper words such as adjectives and articles, having an object at the end of a sentence means that sentence final speech is not so quiet after all. Figure 1 shows a stylized fall-off of speech loudness in a SVO language such as English. There is some fall-off but not too bad. What we lack in lung air volume by the end of a sentence is partly made up for by the importance, and therefore increased sound level, of sentence final objects.
There are, however, many languages spoken today that have a Subject-Object-Verb (SOV) word order. In these languages, the ends of sentences are relatively quiet since there is nothing but quiet helper words, such as verbs, adjectives, and prepositions. In these languages, the ends of sentences are very quiet and should be thought of as quiet speech regardless of whether they are vowels or consonants. Some language examples of SOV languages are Hindi, Urdu, Iranian (Farsi), Korean, Japanese, and Somali. Figure 1 also shows how the speaking level of these languages significantly falls off at the end of sentences. It’s apparent that not only is there limited air left in our lungs to speak, but there are not important nouns hanging around to save the day.
Soft speech is not only restricted to the higher frequency consonant sounds, but also the entire ends of sentences in languages that have a SOV word order.
As far as fitting hearing aids on people who are bilingual, where they may speak both English (an SVO language) and perhaps Hindi (an SOV language), one program can be configured for English, and another that has more gain for soft-level (sentence final) inputs can be configured for Hindi.
And to make this even more interesting for those who have clients from a Polynesian language group (spoken just north of Australia), these languages have Verb-Subject-Object (VSO) word order with all of the important, higher sound level nouns positioned at the end of the sentence. Speakers of these languages would require less gain for soft level speech than speakers of English or any other SVO language.
Reference
-
Chasin M. Sentence final hearing aid gain requirements of some non-English languages. Can J Speech-Lang Pathol Audiol. 2012;36(3):196-203.
Marshall Chasin, AuD, is an audiologist and director of research at the Musicians’ Clinics of Canada, Toronto. He has authored five books, including Hearing Loss in Musicians, The CIC Handbook, and Noise Control—A Primer, and serves on the editorial advisory board of HR. Dr Chasin has guest-edited three special editions of HR on music and hearing loss (August 2014, March 2006, and February 2009), as well as a special edition on hearing conservation (March 2008).
Original citation for this article: Chasin, M. What Is Soft Speech and How Is It Dependent on the Language Being Spoken? Hearing Review. 2015;21(3):14.



