Summary:
A new study shows that people’s acceptance of background noise depends largely on how much speech they think they understand, with their reactions shifting between sensory, cognitive, and emotional domains based on perceived intelligibility.
Key Takeaways:
- When listeners feel they don’t understand speech well, they mainly focus on improving speech clarity and loudness comfort; as understanding improves, annoyance and distraction become more influential.
- Hearing care strategies should address not only speech intelligibility but also emotional and cognitive reactions to noise for fuller patient satisfaction.
- Empowering users—through dedicated listening programs and fine-tuning options—can help tailor hearing aid performance to changing real-world listening needs and individual preferences.
By Francis Kuk, PhD; Christopher Slugocki, PhD; Petri Korhonen, MSc
Most people (with or without a hearing loss) find communication in noisy backgrounds challenging. Some people accept quite a bit of noise before they find it unacceptable, while others cannot tolerate the least bit of noise in the background. Furthermore, their reactions or reasons for aversion to noise seem to vary.
As hearing care professionals (HCPs), it would be beneficial for us to understand what drives listeners’ reactions in noise and how one may use this knowledge to better meet their individual needs. The results of our recent study suggest that it is the listeners’ perception of how much speech they understand that guides their reactions.1
Possible Origins of Noise Reactions
Reactions to noise may originate from different domains.2 Listeners may find that noise interferes with communication and use perceived speech understanding as the basis for their reaction. One may group this into the speech/communication domain. Listeners may find noise to be uncomfortably loud and use loudness (dis)comfort as a basis for their reaction. One may group this into loudness, a sensory domain. Listeners may find noise to be distracting and have to put in extra mental effort to communicate. One may group this reaction under the cognitive domain. Lastly, listeners may find noise to be annoying. This is an emotional reaction to noise and could be attributed to unpleasant sound quality and factors mentioned previously.
These four key or criterion domains (speech, loudness, distraction, and annoyance) are not mutually exclusive and are likely used by listeners to different degrees depending on the listening situations and the listeners.
Over the years, researchers have tried to understand which domain(s) listeners use in their reactions to noise in order to devise appropriate intervention strategies. For example, if speech is the only domain used in all listening situations, then hearing aid designs can focus just on enhancing speech intelligibility, even at the expense of other factors such as poorer sound quality. If distraction is the dominant domain, then understanding the cognitive level of the listeners prior to the hearing aid (HA) selection may help in selecting the features that complement the listeners’ profile. If there is more than one domain or if the use of these domains changes with listening conditions, one must consider those changes in the intervention for optimal listener experience. Thus, a better understanding of how people with normal hearing (NH) and people with hearing impairment (HI) react to noise could help improve clinical service and HA design.
How Was Criterion Domain Importance Studied?
Mackersie et al used the Noise Tolerance Domain Test (NTDT) to study the dominant noise reaction domains (speech, loudness, distraction, annoyance) used by young NH listeners.2 During the test, speech/noise was presented at the acceptable noise level (ANL) of the listener. Each criterion domain was paired with the others and listeners compared the domains to determine which was more important in their noise acceptance judgment. Afterward, participants rated how much their impression was affected on the specific domain using 0-100 (with “0” meaning no effect and “100” meaning large effect). The product between the proportion a particular criterion domain was selected and the rating assigned to that domain is calculated as the Weighted Noise Tolerance Domain Rating (WNTDR). The higher the WNTDR, the heavier weight or the greater importance of that domain in the overall noise reaction. Indirectly, it suggests greater need for improvement on that domain.
We conducted the NTDT on 22 NH (mean age = 64.3 yrs, SD = 8.2 yrs, 16 female) and 17 HI (mean age = 76.9 yrs, SD = 8.6 yrs, 6 female) listeners with a bilaterally symmetrical (± 10 dB) mild-to-moderately severe sensorineural hearing loss. All listeners were tested in the unaided mode. In addition, the HI listeners were also tested in the aided mode using a study hearing aid fitted to the NAL-NL2 target. In contrast to Mackersie et al’s study2, the NTDT test in our study was presented at the average noise tolerance level (TNTave) measured on the Tracking of Noise Tolerance (TNT) test at 75- and 82-dB SPL speech input levels and at signal-to-noise ratios (SNRs) of +/- 3 dB re: TNTave. The 3 SNRs by 2 speech levels were used in order to estimate how noise acceptance criterion domains change above and below this average unacceptable level in order to have a fuller understanding of the dynamics behind the changes. We also estimated the listeners’ subjective speech intelligibility at the same SNRs using the Objective and Subjective Intelligibility Difference (OSID) test.
How Do Listeners Weigh Each Domain In Noise?
The WNTDRs measured between NH and HI listeners in the unaided and aided modes were compared using a series of Linear Mixed Effects (LME) models. While there are some small differences in the WNTDR between aided and unaided modes, the trends in domain use are similar between NH and HI listeners. Thus, we simplified the display by showing in Figure 1 the relative importance for each domain as a function of subjective speech intelligibility. Interested readers can refer to Kuk et al for more details.1
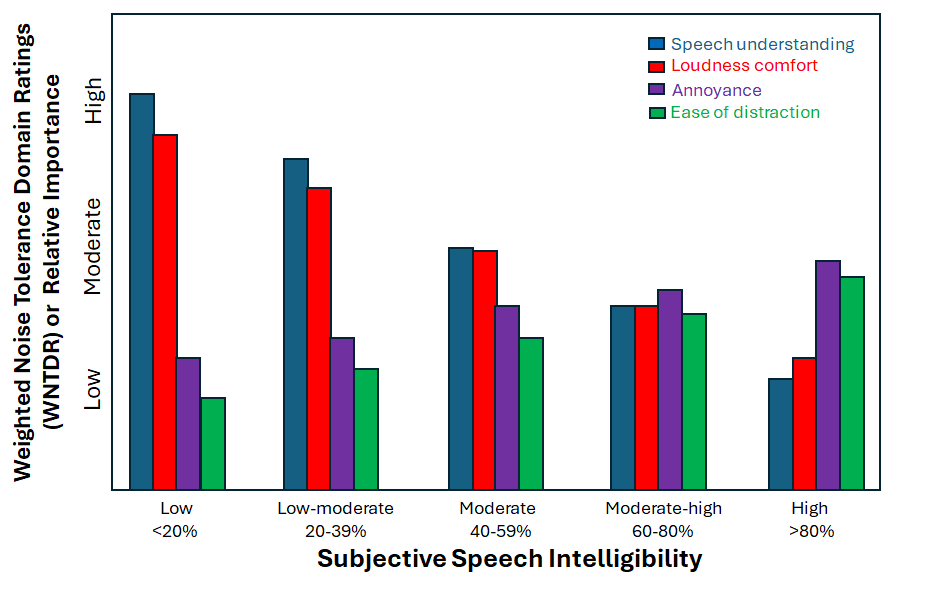
Let’s take the WNTDR for the speech domain as an illustration. When subjective speech intelligibility is “low,” WNTDR for speech is relatively “high.” This suggests that when listeners think they do not understand well, they place heavy weight (or greater importance) on poor speech understanding as the reason for noise rejection or un-acceptance. As speech intelligibility improves to “high,” WNTDR for the speech domain decreases to a relatively “low” level. As listeners think their speech understanding has improved, the importance or the need for improvement on the speech domain decreases. Figure 1 also shows that the weight placed on the loudness domain is similar to that on the speech domain, suggesting that listeners’ reactions on both domains are similarly affected by subjective speech intelligibility.
In contrast, the weights on annoyance and distraction increase from a relatively “low” level when subjective intelligibility is “low” to a “moderate” level when subjective intelligibility is high. This suggests that listeners’ reaction to noise shifts more toward a cognitive (distraction) and emotional (annoyance) basis when subjective speech intelligibility improves. This shift occurs when perceived speech understanding is at a “moderately high” level where all domains contribute about equally to the overall noise acceptance.
In addition to the general trends, Figure 1 also shows that when perceived speech understanding is “low,” the importance placed on the speech domain is higher than that placed on the loudness domain. However, when perceived speech understanding is “high,” the importance of loudness comfort exceeds that of speech understanding. This suggests that a comfortable loudness is important when speech understanding is optimal. Furthermore, one also notes that the weight placed on the annoyance (or emotional) domain is consistently higher than that on the distraction (cognition) domain.
What Do These Observations Tell Us?
The key observation from this study is that both NH and HI listeners use subjective speech intelligibility (or how much they think they understand) to drive/guide their decision on noise acceptance. However, their reactions originate from different criteria domains depending on how much they think they understand in the noise backgrounds.
When listeners think they understand less than a “moderate” level of speech, their reaction to noise is guided by the acoustic domains such as speech and loudness domains. That is, they want to understand more and at a more comfortable loudness level. On the other hand, as their perceived understanding improves to a “moderately high” level, their criteria gradually change to ones that are based more on non-acoustic factors such as ease of distraction and/or effortfulness to listen and annoyance to hear, etc. Indeed, listeners shift from a criterion of “what is heard” to “how the message is heard.” Interpreting the findings at a deeper level, listeners are never always satisfied. When their “needs” are met, they want their “wants” satisfied also.
How can HCPs satisfy people with a hearing impairment then?
Listeners’ changing criteria suggest that they will never be always satisfied if we focus just on improving speech understanding alone. We also need to provide solutions that consider the emotional/cognitive aspects of the individual’s performance, such as the cognitive capacity of the listeners, sound quality of the hearing aid, etc., in our recommendations.
One solution is to empower listeners with the option to change the goals of sound processing on their HAs, e.g. from speech understanding to ease of listening or sound quality, etc. Currently, this empowerment takes two forms. First is the use of general dedicated listening programs. The other is a wearer option to fine-tune HA settings in real-life situations. These two approaches may also be integrated to result in individualized listening programs.
Dedicated listening programs – A fixed set of HA settings yields optimal performance (speech understanding, listening comfort, etc.) for a limited range of listening environments only. Because listeners likely encounter varied listening environments in their daily lives, they likely have varying degrees of satisfaction with a fixed program/settings when encountering these varied environments. Dedicated listening programs use different combinations of HA algorithms/settings to optimize processing in order to maximize satisfaction in more listening environments.
For example, a “quiet” program will likely have a broad bandwidth without the use of aggressive noise reduction algorithms such as a directional microphone or noise reduction. A “music” program will have a broader bandwidth, fewer independent channels, minimal feedback processing, and more linear processing. A “speech-in-noise” program will likely have sophisticated adaptive directional microphone and noise reduction algorithms. These programs are specialized for the specific sound environments and can thus meet the listeners’ varied criteria.
A limitation is that current listening programs are limited in the range of environments they serve and they are not individualized to the listener’s profile. In addition, the wearer has to consciously change the program based on his or her changing criteria or risk using a sub-optimal program.
Wearer fine-tuning in real life – Rather than assuming that all listeners must use a prescribed set of HA algorithms/settings, this approach provides listeners with the option to fine-tune the settings on the hearing aids to meet their individual preference/criteria for the specific real-life environment. One approach is to let the wearers listen to two different settings at a time and make decisions on the one that meets his or her preference/criterion better. Based on the individual’s selection, the algorithm will converge to a final setting that the individual prefers for the specific listening environment.
The advantage of this approach is that it considers the individual’s preference (and thus criteria) for the specific listening environment. The practical limitation of this approach is that only a limited number of parameters may be compared currently.
What does this mean for hearing aid manufacturers?
The primary goal for signal processing in hearing aids is to ensure audibility (e.g., having sufficient gain). With technical advances over the years, these goals have been expanded to include ensuring optimal SNR (such as directional microphone or aggressive NR to improve SNR), minimizing listening effort and/or comfort only (by reducing gain at higher input), ensuring good sound quality (e.g., by having a balance of sounds at comfortable levels and minimizing avoidable distortions), or optimizing hearing in multiple listening situations. Observations from the current study suggest that all these goals should be integrated into the hearing aid so it may provide a seamless change in processing as the listener’s criteria change.
Currently, these goals are achieved to different degrees depending on the manufacturers, most typically in the form of listening programs. It is foreseeable that the use of artificial intelligence in hearing aids could help in individualizing these changes and provide a seamless transition in processing goals as the listeners’ perceived speech understanding changes.
About the Authors
Francis Kuk, PhD, is the director; Christopher Slugocki, PhD, is a senior research scientist; and Petri Korhonen, MSc, is a principal research scientist at the WS Audiology Office of Research in Clinical Amplification (ORCA) in Lisle, Ill.
References
1. Kuk F, Slugocki C, Korhonen P. Subjective Speech Intelligibility Drives Noise-Tolerance Domain Use During the Tracking of Noise-Tolerance Test. Ear Hear. 2024;45(6):1484-1495. doi: 10.1097/AUD.0000000000001536
2. Mackersie CL, Kim NK, Lockshaw SA, Nash MN. Subjective criteria underlying noise-tolerance in the presence of speech. Int J Audiol. 2021;60(2): 89–95. doi:10.1080/14992027.2020.1813909



