In recent years, sophisticated “automatic” or “adaptive” hearing aids have been developed that monitor the listening environment and adapt hearing aid parameters (eg, directionality, multi-channel compression, noise cancellation, feedback reduction) to be optimized separately for different acoustic conditions. The classification accuracy of this system has proven to be highly sensitive and specific in laboratory settings under simulated conditions.1
As these systems move from laboratory to clinic, however, it raises the issue of how to evaluate classifier performance for “real-world” conditions. One challenge, for example, relates to the importance of synchronizing the behavior of independent hearing aids worn in typical listening environments. At issue is whether it is more important to synchronize the classification environment across ears, or allow the classification of the environment to vary depending on the listening situation.
The present study evaluated the performance of independent bilateral hearing aids in various listening environments to assess:
• The sensitivity and specificity of program-switching behavior;
• The prevalence of symmetric versus asymmetric listening conditions in real-world listening environments;
• Individual preference differences reported by patients.
Before we proceed, it is useful to make a distinction between the terms acoustic scene analysis and auditory scene analysis. Specifically:
• Acoustic Scene Analysis addresses how well the machine (eg, hearing aid) can classify different sound categories.1
• Auditory Scene Analysis addresses the human interface relative to how well listeners can segregate simultaneous auditory objects.2
Acoustic Scene Analysis
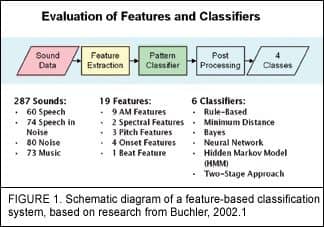
Buchler1 evaluated numerous acoustic classification strategies in an attempt to find which approaches provided the best sensitivity and specificity for hearing aid applications. Using a set of 19 different spectral and temporal features (Figure 1) that were classified using a series of 6 classification methods, he reported that a Hidden Markov Model with subsequent rule-based classification provided accurate classification of four acoustic environments—speech in quiet, speech in noise, noise alone, and music—with approximately 94% test efficiency. The evaluation was conducted using nearly 300 different sound samples, representing a variety of speech, noise, and music environments.
Human studies were then conducted analyzing the switching behavior of wearable digital hearing aids and their perceptions regarding the accuracy, frequency, and appropriateness of the switching.3
A total of 63 subjects with moderate to severe sensorineural hearing loss were fitting binaurally with custom in-the-canal (ITC, 2 subjects), in-the-ear (ITE, 33 subjects), and behind-the-ear (BTE, 28 subjects) devices. Each subject was fitted with hearing aids in the laboratory, where acoustic scene analysis demonstrations were provided to ensure that they understood and could hear the classification system in a controlled environment. Subsequently, the hearing aids were worn for a period of 2 to 3 weeks, and a questionnaire was completed that asked the following questions pertaining to switching behavior and program selection:
Process of switching:
• Do you perceive the switching between programs?
• How often does it switch?
• Does the instrument switch when you expect it?
Program selection:
• Does the selection of programs fit the respective environment?
• When is the program selection wrong?
Usefulness:
• How often was automatic switching used?
• How useful is the automatic program selection?
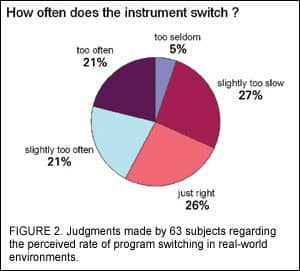
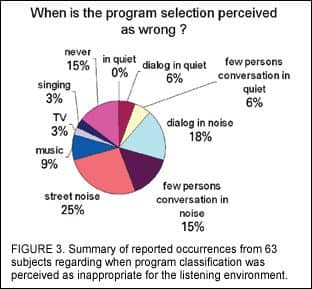
The results indicate that there was considerable variability across subjects in terms of their judgment regarding the rate of program switching (Figure 2) and switching accuracy (Figure 3). These data suggest the need for fine-tuning of classification speed and sensitivity to meet individual preferences. They also highlight the importance of both laboratory and real-world evaluation of advanced signal processing techniques.
|
|
Asymmetric Switching
One possible reason for the large inter-subject differences in Figures 2-3 may be due to large differences in the real-world environments encountered by different hearing aid users. For example, some users may spend more time in low-ambient noise environments, while others may be in symmetric, asymmetric (left/right), or diffuse listening environments. Analysis of datalogging results revealed no statistically-significant relationship between “wrong” program selection and actual hearing aid use in the four different “AutoPilot” programs (calm, speech in noise, comfort in noise, or music). Consequently, the issue of asymmetric listening environments and program switching behavior was explored.
A single subject was fitted with independent ear-level bilateral hearing instruments that served as recording microphones for different real-world listening environments. Independent outputs from each device served as output into a central processor for analysis. A total of 22 hours of various listening hours were recorded, comprising a total of 63 separate “tracks” that ranged from 2 minutes to 2 hours in duration. For each track, the output of the device was constrained to one of the four acoustic classes used in AutoPilot: speech in quiet, speech in noise, noise alone, or music. The central processor was used to analyze synchronous and asynchronous switching behavior over the 22 hours recording time.
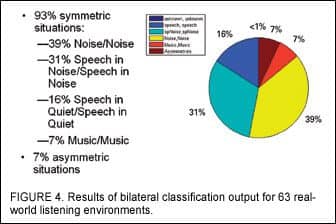
Results indicate that, across the 63 real-world tracks, symmetric program switching (output from both ears the same) was present 93% of the time (Figure 4). For this test condition, the speech-in-quiet program was classified 16% of the time in both devices, with speech in noise, noise alone, and music classified at 31%, 39%, and 7%, respectively. This ratio of quiet to noisy listening backgrounds confirmed a previous study by Walden et al4 that indicates directional microphones are preferred approximately 33% of the time for typical hearing aid users. Similar to the present study, the Walden et al study subjects also preferred omni-directional microphone settings 37% of the time and had no preference 30% of the time.4
For the 7% of the time when outputs from the left and right instruments were asymmetric, the vast majority of occurrences were when noise was present in the ambient listening environment. For 47% of these occurrences, speech in quiet was detected in one ear, indicating that the primary talker may have been proximal to one ear. Although objective speech recognition evaluation was not conducted, the data suggest an advantage over binaural synchronization. Additional experimentation is underway to explore this possibility.
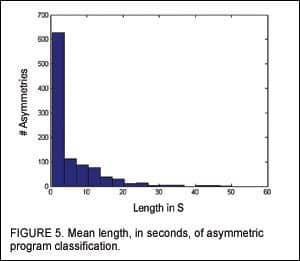
The mean length, in seconds, of program asymmetry is shown in Figure 5. The median length of program asymmetry, when present, was 1.8 seconds. Very few asymmetries in excess of 20 seconds existed, and were restricted to slightly noisy to rather noisy (60 dBSPL or greater) situations combined with a conversation with one or a few individuals situated to one side of the user (eg, whispering in the movie theater, chatting while sitting at a bar, discussing a topic when seated next to another person in an auditorium, and talking while cooking on a stove).
These data reinforce the idea that it is beneficial to allow independent switching behavior to optimize communication in these listening situations. A more important factor may be to focus on monitoring and adjusting for bilateral, situation-specific volume control adjustments made by hearing aid users across listening environments. Additional research is required to confirm these findings.
However, the bottom line is that, as hearing aid technology becomes more sophisticated, one challenge involves the combining of laboratory data with real-world experience to find the most appropriate evaluation strategies for predicting patient benefits.
References
1. Buchler MC. Algorithms for Sound Classification in Hearing Instruments. Dissertation submitted to: Swiss Federal Institute of Technology; Zurich, Switzerland. ETH No. 14498; 2002:1-136.
2. Bregman AS. Auditory Scene Analysis. Cambridge, Mass: MIT Press; 1990.
3. Allegro S, Buchler M, Launer S. Automatic Sound Classification Inspired by Auditory Scene Analysis. Paper presented at: Eurospeech. Aalborg, Denmark; 2001.
4. Walden BE, Surr RK, Cord MT, Dyrlund O. Predicting Hearing Aid Microphone Performance in Everyday Listening. J Am Acad Audiol. 2004;15: 365-396.
This article was submitted to HR by David A. Fabry, PhD, vice president of professional relations and education at Phonak Hearing Systems, Warrenville, Ill; and Stefan Launer, PhD, head of applied research, and Peter Derleth, PhD, senior audiological engineer, at Phonak AG, Stafa, Switzerland. Correspondence can be addressed to David Fabry, Phonak Hearing Systems, 4520 Weaver Parkway, Warrenville, IL 60555; e-mail: [email protected].



