
This new hearing aid technology was developed to improve the wearer’s experience in group conversations in noise.
By Niels Søgaard Jensen, MSc; Barinder Samra, MSc; Homayoun Kamkar Parsi, PhD; Sascha Bilert, MSc; and Brian Taylor, AuD
Although we have witnessed remarkable improvements in hearing aid benefits recently(1), many challenges affecting wearer satisfaction and quality of life remain unaddressed.
Using MarkeTrak 2022 data, Picou(2) tabulated the percentage of hearing aid owners and non-owners with hearing loss who were satisfied with their ability to hear in a variety of listening situations. Among hearing aid non-owners, situations involving “following conversations in the presence of noise” and “conversations with large groups” had the lowest share of satisfied respondents. Further, these specific situations were some of the places with the poorest satisfaction ratings for current hearing aid owners, too. This finding should come as no surprise to hearing care professionals who regularly encounter wearers that commonly report problems in noisy group conversations.
Nicoras et al.(3) investigated several factors related to conversation success. They found for both individuals with hearing loss and those with normal hearing that the factor “being able to listen easily” was the most important for conversation success. While it is unsurprising that the ability to hear and understand is key to any successful conversation, their research showed other factors were important. For example, “sharing information as desired”—a factor related to both information exchange as well as the conversation reaching a successful conclusion—was judged to be crucial to conversation success. Results of this study are twofold. One, it demonstrates that conversation success is directly related to an individual’s ability to hear and understand. Two, it shows that conversation success is linked to each communication partner’s ability to actively contribute to the conversation.
Further reading: Signia Introduces Hearing Aid Tech for Noisy Group Conversations
Hearing aid signal processing approaches, traditionally applied to improve speech-in-noise performance, often provide subpar benefit for wearers in group conversations. For example, while traditional directional microphone technology may provide a benefit when the wearer listens to a person directly in front of them, it will attenuate talkers from other directions.
RealTime Conversation Enhancement, introduced in the new Signia Integrated Xperience (IX) hearing aids, is based on multi-stream architecture to provide a fundamentally new approach to analyzing multi-talker conversations. Further, given the way IX analyzes and processes speech, it is designed to provide enhanced benefit when the wearer engages in both one-on-one and dynamic group conversations.
In this article, we present and discuss data from a study demonstrating wearer benefit from RealTime Conversation Enhancement (RTCE). First, however, we explain the functionality of this technology.
How it Works
The RTCE technology is developed on top of the unique Augmented Focus processing (split processing) introduced in Signia Augmented Xperience (AX) in 2021. Split processing enables separate processing of speech and noise by splitting the incoming sound into two different streams, processing sounds from the front and the back separately. In this way, the contrast between speech and noise is enhanced, which supports improved speech understanding in challenging situations.(4)
The basic principles of RTCE are shown in Figure 1. The RTCE processing follows a three-stage approach: Analyze, Augment, and Adapt. Note that the stages and their elements represent a simplified description of IX processing. In reality, IX’s split processing (shown to the left) and its three RTCE stages occur simultaneously in a highly complex, integrated manner.
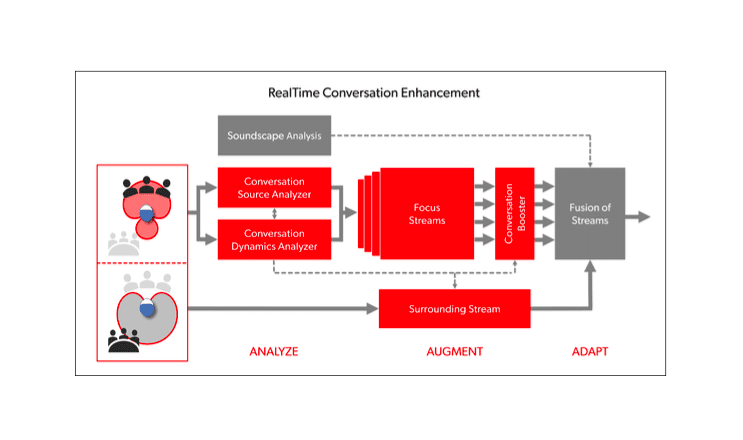
Next, with reference to Figure 1, we describe the role of each stage.
Analyze. In the first stage, the incoming sound is analyzed by the Conversation Source Analyzer and the Conversation Dynamics Analyzer. If relevant speech is detected, a detailed conversation layout is determined, including estimation of talker locations and approximation of turn-taking dynamics. This analysis involves the processing of 192,000 data points per second, which enables real-time tracking of dynamic conversations where talkers move around or where the wearer turns their head.
Augment. Three highly dynamic focus streams are created using advanced binaural processing powered by the e2e wireless system and added to the front-hemisphere focus stream provided by the split processing. The four Focus Streams work independently, and together they cover the entire front hemisphere and allow separate processing of speech coming from spatially separated conversation partners. The focus streams are integrated in the Conversation Booster, which ensures the optimal enhancement of speech within each focus stream and a perfect balance between the streams. In parallel with the focus stream processing, the Surrounding Stream is processed independently, creating a strong contrast to the focus streams.
Adapt. Adapting up to 1,000 times per second, the focus streams and the surrounding stream will fuse together to create a live auditory space where the conversation partners stand out against the background noise. The focus streams will react to any changes in the conversation layout, e.g., when talkers enter or leave the conversation, when they move around, or when the wearer turns their head. Thus, the active talkers are continuously being tracked and augmented through the focus streams.
The result of the RTCE processing is a listening experience that effectively adapts to both the conversation and the entire acoustic environment. This allows the wearer to be fully part of and contribute to the conversation while still being immersed in the surroundings. More information about the RTCE processing is provided by Jensen et al.(5)
Testing RealTime Conversation Enhancement
The perceptual benefits of RealTime Conversation Enhancement were investigated in a study conducted at Hörzentrum Oldenburg, Germany.
Methods
Twenty participants (10 female, 10 male, age range: 55-82 years, mean age: 72 years) with sensorineural sloping hearing loss participated in the study. The mean four-frequency pure tone average (PTA) hearing loss was 53 dB HL.
The participants were fitted with Signia Pure Charge&Go T IX hearing aids, according to the IX First Fit rationale. Half of the participants were fitted with closed couplings (power sleeves), and the other half were fitted with vented couplings (vented sleeves). The hearing aids were fitted with two programs. In the first program, all IX features, including RTCE, were activated. In the second program, RTCE was disabled. All other features, including split processing, were activated.
Two speech tests were conducted. In the first test, basic speech understanding was measured using a standard implementation of the German Matrix test, the Oldenburger Satztest (OLSA),(6) where target sentences were presented from a loudspeaker in front (0°) and unmodulated masking noise (at 65 dBA) was presented from the back (180°). The task of the participant was to repeat each sentence. Depending on the number of words repeated correctly, the level of the speech was changed adaptively to determine the signal-to-noise ratio (SNR) at which 80% of the words could be repeated correctly. This speech reception threshold will be referred to as SRT80.
In the second test, the OLSA test setup was modified to simulate a realistic group conversation. Most importantly, the target sentences were presented alternately from two loudspeakers positioned to the right and left of the participant (at 20° and 340°), and the masking noise was babble noise created by playing the target sentence material continuously from five loudspeakers positioned at 90°, 135°, 180°, 225°, and 270°. The total level of the babble noise was fixed at 67.5 dBA. The task of the participant and the outcome measure (SRT80) was the same as in the standard test.
Each participant performed each test with both hearing aid settings: RTCE ON and RTCE OFF, in a counterbalanced manner. In both tests, a training round was completed to familiarize the participants with the task.
Results
Standard OLSA
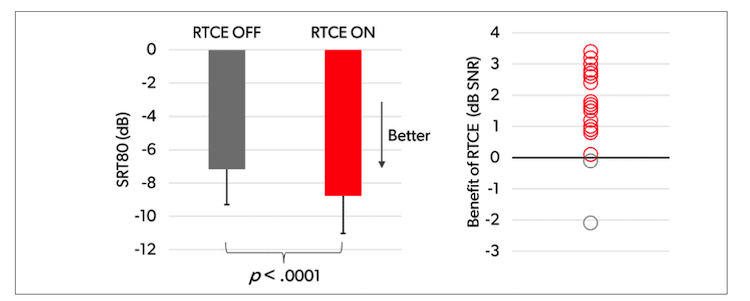
The results of the standard OLSA test are shown in Figure 2. The left plot in Figure 2 shows the mean SRT80 values across the 20 participants, while the right plot shows the individual SNR benefits of RTCE observed in the test. Please note that a lower SRT80 means better performance. That is, a lower (better) score on the SRT80 equates with greater wearer benefit.
Figure 2 shows RTCE provided a mean SRT80 benefit of 1.6 dB (improving the mean SRT80 from -7.2 dB to -8.8 dB). On an individual level, the benefit was observed for 18 out of the 20 participants (90%). The mean benefit was statistically significant (F(1, 18) = 27.76, p < .0001) according to a repeated measures ANOVA.
Modified OLSA
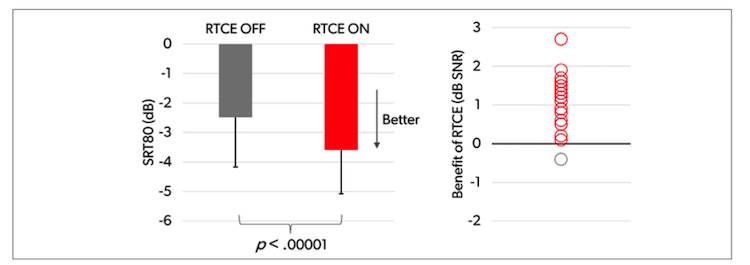
Figure 3 shows the results from the modified OLSA test, plotted in the same way as the standard OLSA results.
Figure 3 shows RTCE provided a mean SRT80 benefit of 1.1 dB (improving the mean SRT80 from -2.5 dB to -3.6 dB) in this more acoustically complex test scenario. It is worth noticing, on an individual level, 19 of the 20 participants (95%) performed better in the test with RTCE. A repeated measures ANOVA showed that the mean benefit was highly statistically significant (F(1, 18) = 43.16, p < .00001).
Discussion
In both speech tests, activating RTCE with its multi-stream processing provided a significant improvement in the participants’ ability to understand speech in the acoustically challenging test conditions.
The standard OLSA test offers a good simulation of a one-on-one conversation situation where the hearing aid wearer is facing a conversation partner with noise coming from behind. In the test, a mean SRT80 improvement of 1.6 dB was observed, which corresponds to around 25% better speech understanding (based on the slope of the underlying psychometric function(7)).
The modified OLSA test assessed a more complex group conversation scenario, and this was reflected in mean SRT80 values being around 5 dB higher than in the standard test. A key finding was that RTCE also provides a substantial benefit in this more difficult scenario. A striking observation was that 95% of the participants performed better on the test with RTCE turned on. The significant mean SNR benefit of 1.1 dB corresponds to an improvement in speech understanding of approximately 20% and should provide the wearer with a distinct benefit in group conversations.
According to the results of the study, the improvements in speech understanding offered by RTCE enable the wearer to contribute more actively—and more confidently—to any conversation. The less the wearer struggles to understand speech, the more cognitive resources can be reserved and instead spent on the task of actively participating in the conversation, empowering the wearer to contribute more to the social interaction.
Further reading: Signia’s Enhanced Hearing Platform Available for Veterans, Military Members
Summary
In this article, we have described the new RealTime Conversation Enhancement technology with its multi-stream architecture, which is introduced on the Signia Integrated Xperience (IX) platform. The main conclusions of a study investigating the perceptual benefits were:
In a simple speech test simulating a one-on-one conversation, activating RTCE provided a significant improvement in speech understanding with 90% of the participants showing better performance with RTCE.
In a more acoustically complex speech test, simulating a group conversation scenario, activating RTCE also provided a significant improvement in speech understanding with 95% of the participants showing better performance with RTCE.
In combination, the results suggest that RTCE can significantly improve the wearer’s conversational experience, making it easier to understand and contribute to a conversation.
Featured image: Figure 1. Simplified diagram showing the functionality of the RealTime Conversation Enhancement technology. Bold lines and arrows indicate the flow of the streams, while thin dotted lines and arrows indicate control paths.
About the authors: Niels Søgaard Jensen, MSc, is senior evidence and research specialist at Signia, Lynge, Denmark. Barinder Samra, MSc, is commercial audiology manager at Signia, Lynge, Denmark. Homayoun Kamkar Parsi, PhD, is head of Signal Processing Algorithmic Research & Neural Networks at Signia, Erlangen, Germany. Sascha Bilert, MSc, is research audiologist at Signia, Erlangen, Germany. Brian Taylor, AuD, is senior director, Audiology, Signia US. For author correspondence contact [email protected].
References
- Taylor B, Jensen NS. Unlocking Quality of Life Benefits Through Firmware and Apps. Hearing Review. 2023;30(5):24-26.
- Picou EM. Hearing aid benefit and satisfaction results from the MarkeTrak 2022 survey: Importance of features and hearing care professionals. Semin Hear. 2022;43(4):301-316.
- Nicoras R, Gotowiec S, Hadley LV, Smeds K, Naylor G. Conversation success in one-to-one and group conversation: a group concept mapping study of adults with normal and impaired hearing. Int. J. Audiol. 2022:1-9.
- Jensen NS, Høydal EH, Branda E, Weber J. Augmenting speech recognition with a new split-processing paradigm. Hearing Review. 2021;28(6):24-27.
- Jensen NS, Samra B, Kamkar Parsi H, Bilert S, Taylor B. Power the conversation with Signia Integrated Xperience and RealTime Conversation Enhancement. Signia White Paper. 2023. Retrieved from www.signia-library.com.
- Wagener K, Brand T, Kollmeier B. Entwicklung und Evaluation eines Satztests für die deutsche Sprache. I-III: Design, Optimierung und Evaluation des Oldenburger Satztests (Development and evaluation of a sentence test for the German language. I-III: Design, optimization and evaluation of the Oldenburg sentence test). Zeitschrift für Audiologie (Audiological Acoustics). 1999;38:4-15.
- Wagener KC, Brand T. Sentence intelligibility in noise for listeners with normal hearing and hearing impairment: influence of measurement procedure and masking parameters. Int. J. Audiol. 2005;44(3):144-56.



