
Tech Topic | October 2021 Hearing Review
By Christopher Slugocki, PhD; Francis Kuk, PhD; Petri Korhonen, MSc; and Neal Ruperto, AuD
Mismatch negativity (MMN) is a well-documented brain signal that appears in the electroencephalogram (EEG) when the auditory system detects an unexpected sound. More recently, the MMN (which doesn’t require the listener’s active participation) has been used to determine if different hearing aid features support or augment a listener’s tracking of changing speech sounds from a single voice out of many. This study shows that the Signia Augmented Xperience (AX) platform and its Augmented Focus (AF) system—which splits the incoming sound into two separate signal streams—increases the contrast between sounds in a “cocktail party”-type setting and enhances listeners’ tracking of changing phonemes. Further, the results suggest the behavioral advantages are probably bottom-up in nature, meaning that AF also likely reduces the effort/fatigue experienced by the wearer when trying to communicate in noisy environments.
Our day-to-day soundscapes are crowded with sounds from different sources. Often, we wish to listen to one of these sources more than the others (eg, a friend’s voice at a cocktail party). While this may feel effortless and natural, faithfully extracting different audio sources from a mixture is a problem that even powerful computers can struggle to solve. Every day our brains work to accomplish this task by looking for patterns in the mix of sounds entering our ears and using these patterns to group sound features into meaningful “auditory objects” that represent real people and things in our environments.
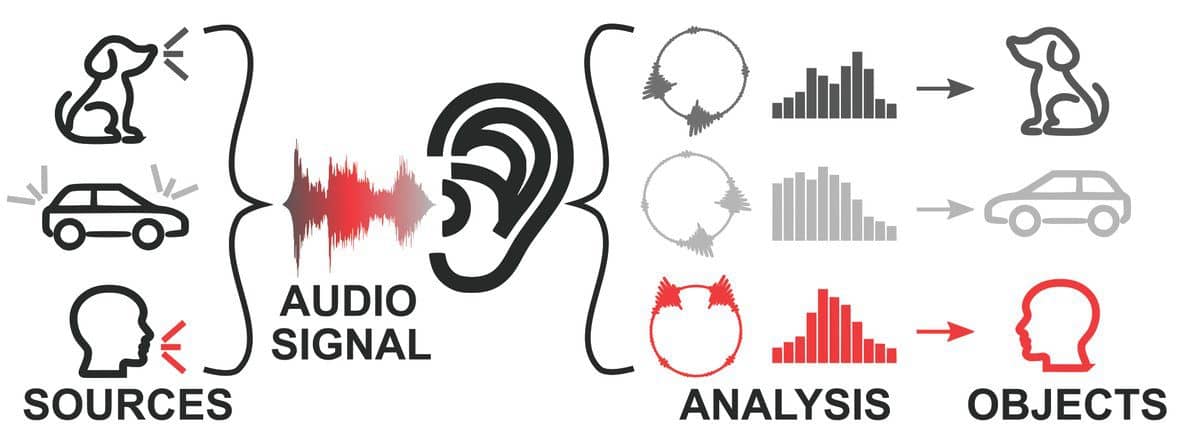
Collectively, these functions are referred to as auditory scene analysis (ASA).1 Through ASA, the brain can identify predictable spectral (eg, fundamental/formant frequencies), temporal (eg, cadence/prosody), and spatial (eg, binaural cues) features of certain voices/sounds and fuse them into a single coherent perception (ie, these sound frequencies, arriving at this rate, from this direction must belong to my friend). Maintaining a perception of separate audio sources allows us to selectively focus our attention on a single source/talker apart from other sounds in the environment (Figure 1).
Recent work like that of Friston et al2 and Winkler & Czigler3 has sparked renewed interest in exploring how predictive coding models of brain processing might help us to better understand the mechanisms behind ASA. This work proposes that our perception of the auditory world is a direct result of the brain constantly making and testing predictions about what sound features should be grouped together. When these predictions are correct, we understand the auditory world easily. Alternatively, if there is a mismatch between the expected and the perceived sound, the brain calculates this prediction error, and then adjusts and/or relearns either the predicted or the perceived sound. Thus, any signal processing that allows the brain to successfully form predictions could improve understanding in noisy environments.
We can evaluate how well the brain forms and maintains predictions about auditory objects, and if particular hearing aid (HA) processing supports the prediction process, by examining what happens when such predictions are purposefully contradicted. For this we use the mismatch negativity (MMN), a well-documented brain signal that appears in the electroencephalogram (EEG) when the auditory system detects an unexpected sound.
In a typical MMN experiment, two or more sounds are presented in an oddball sequence. One of these sounds (the standard) occurs frequently while the other (the deviant) occurs infrequently and at random. The standard sound artificially sets up the brain’s prediction about future sounds while the deviant sound contradicts that prediction. The MMN is the difference in brain activity evoked by the deviant and that of the standard. This difference grows larger when the difference between standard and deviant stimuli becomes easier to detect perceptually (for a review, please see Paavilainen4).
Consider speaking to a friend at a cocktail party. If the background noise is too loud, the brain might have difficulty finding the predictable patterns that define the friend’s voice. It may therefore have problems tracking the changing phonemes of the friend’s speech from the phonemes produced by other voices at the party.
We can simulate a similar scenario in an MMN experiment by presenting an oddball sequence of phonemes in one voice coming from the front, while simultaneously presenting other random phonemes with different voices (eg, babble) in the background. At poorer signal-to-noise ratios (SNRs), when the contrast between voices is low, we might expect the MMN evoked by deviant phonemes in the front voice to be small. On the other hand, if the contrast between the front voice and the other voices is enhanced, we might expect the MMN evoked by the deviant phonemes to be larger. In this way, we can use the MMN to evaluate if different hearing aid features support or even augment a listener’s tracking of the changing speech sounds from a single voice out of many without the listener’s active participation.
Recently, the Signia Augmented Xperience (AX) platform introduced a new and innovative signal processing paradigm called Augmented Focus (AF).5 This AF technology is enabled by Signia’s beamformer which splits the incoming sound into two separate signal streams. Thus, AF enables the hearing aid to process sounds coming from the front and the back separately, with different gains, time constants, and noise reduction (NR) settings. This split processing increases the contrast between sounds arriving from the front versus back and makes speech easier to understand in noise.6
In the following study, we used the MMN to evaluate whether AF technology could help the hearing brain make and evaluate predictions about a single talker in a cocktail party scenario. We predicted that wearers would show a larger MMN for the AF compared to non-AF conditions in response to phonetic contrasts presented in background babble.
Method
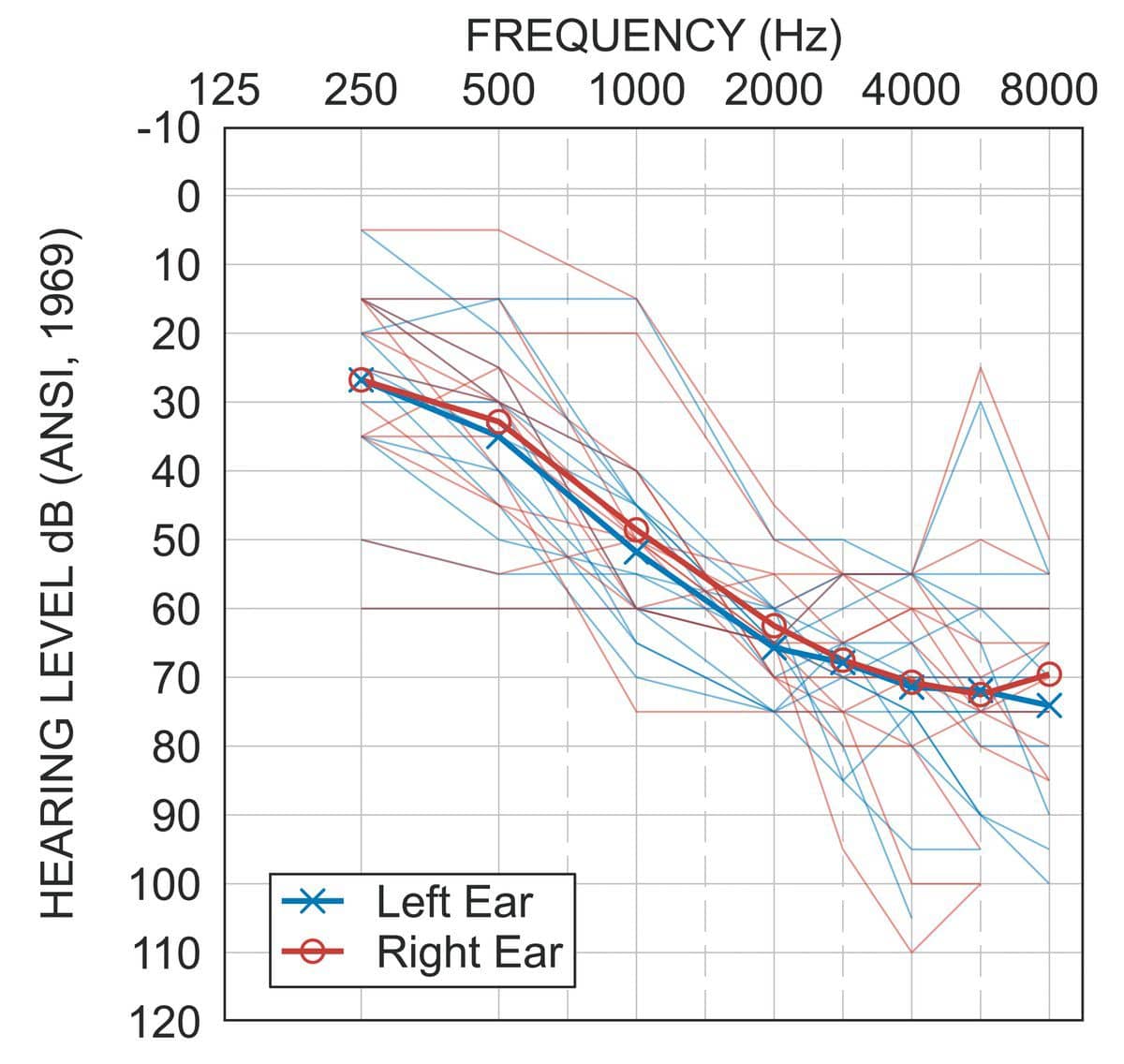
Participants. A total of 14 native English speakers with a symmetrical sensorineural hearing loss (Figure 2) and normal cognitive function (mean age = 68 years, SD = 15, range = 37–83 years, 7 female) participated in this study. Only one participant was not a current hearing aid wearer.
Hearing aids. We compared a full-feature version of the Signia AX with a version that did not have AF. Hearing aids were programmed using the latest version of Signia Connexx fitting software. Participants were fit according to the NAL-NL2 formula at 100% prescription gain. The AF hearing aid was programmed and tested with the default Universal program. The non-AF hearing aid was programmed and tested in a standard omnidirectional microphone mode (non-AF-omn) and in an automatic adaptive directional microphone mode (non-AF-dirm). Features other than noise reduction and feedback cancellation were disabled.
Procedure. We first estimated the SNRs that listeners needed to perform a two-alternative forced choice (2-AFC) phonetic discrimination task at 75% correct performance. Stimuli were recordings of bisyllabic speech (/ba-ba/ and /ba-da/) produced by a male native English talker. These stimuli were presented at 65 dB SPL from a loudspeaker located at a 1 m azimuth (front). At the same time, temporally offset recordings of 4-talker babble were played through each of two loudspeakers located behind the listener at 135° and 225°.
Listeners were presented with pairs of stimuli and asked to indicate whether they were the same (eg, /ba-ba/ and /ba-ba/) or different (eg, /ba-ba/ and /ba-da/). The level of babble noise was varied adaptively from trial to trial according to the Bayesian-based QUEST+ algorithm.7 The results of the 2-AFC test allowed us to behaviorally assess discrimination performance and to individualize MMN testing. Average listener thresholds (SNRs) for discriminating phonemes were -1.2 dB in the AF mode, 2.3 dB in non-AF-omn mode, and 1.8 dB in the non-AF-dirm mode.
Next, we measured the MMN evoked by the same phonetic contrast (/ba-ba/ vs /ba-da/) presented in the same noise at the SNR associated with each listener’s discrimination threshold for the AF condition. Listener EEG was recorded using 19 Ag/AgCl sintered electrodes positioned according to the 10-20 system. High forehead was used as ground and bilateral earlobe electrodes were used as reference. Listeners were presented with a sequence of 800 bisyllabic speech tokens of which 85% were standard (/ba-ba/) and 15% were deviant (/ba-da/). The order of standards and deviants was pseudo-randomized such that at least two standards separated each deviant. Stimuli in the sequence were separated from one another by 0.6-0.7 s.
Results
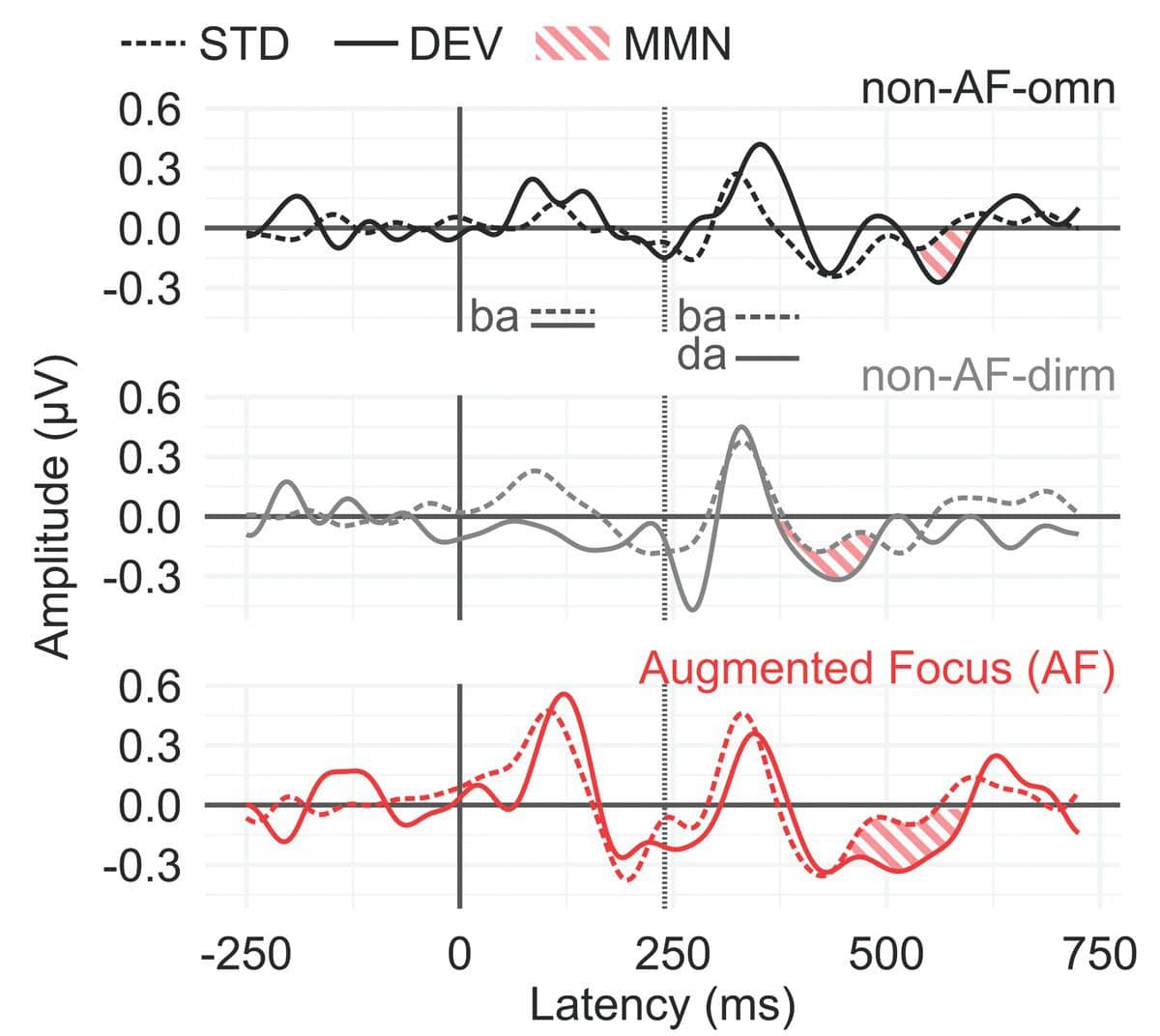
Figure 3 shows the average listener’s brain responses evoked by standard (/ba-ba/, dotted lines) and deviant (/ba-da/, solid lines) stimuli. The MMN can be seen as the difference between standard and deviant responses after the second syllable (thatched red area in Figure 3). Comparing the average MMN across hearing aid conditions, we see that the area separating standard and deviant curves is greatest for the AF condition, followed by the non-AF-dirm and non-AF-omn conditions.
The MMN amplitude was then quantified for each participant as the maximum peak occurring after the second syllable in the difference wave calculated by subtracting the standard response from the deviant response. Statistical analysis revealed that hearing aid condition had a significant effect on listeners’ MMN amplitudes (χ2(2) = 8.17, p = 0.017), where post-hoc contrasts confirmed that MMN amplitudes were significantly enhanced (ie, more negative) for AF compared to non-AF-omn (Figure 4).
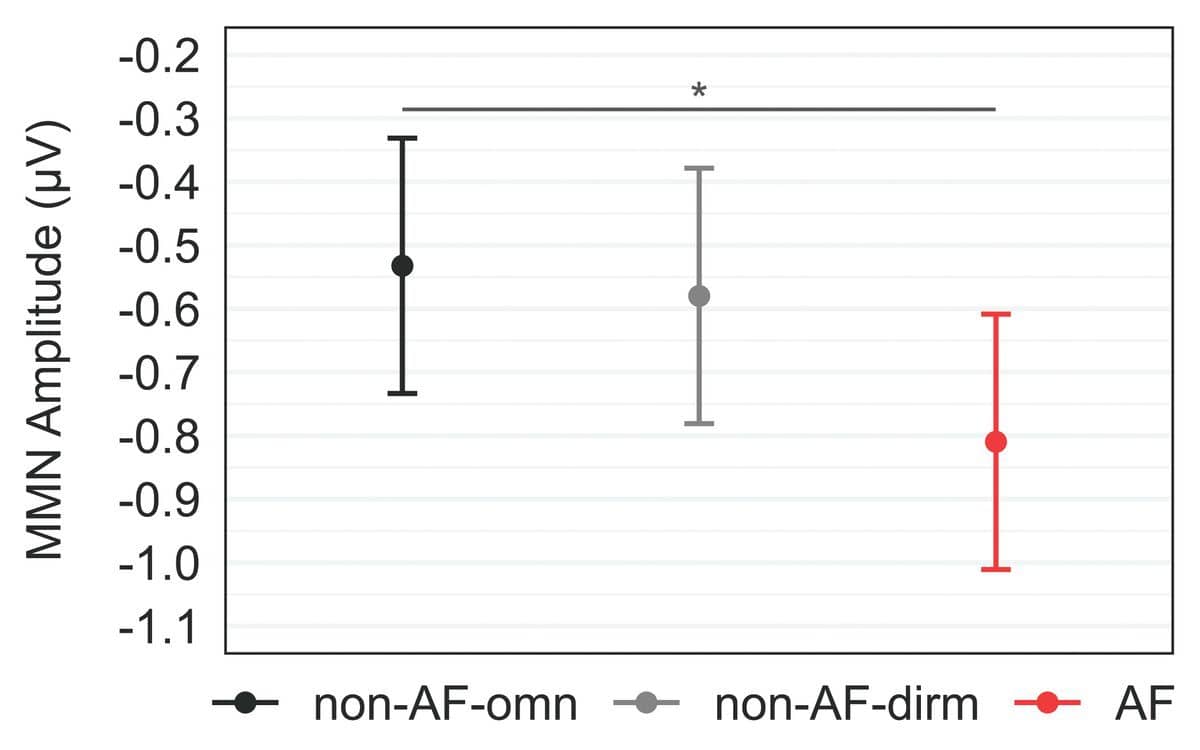
Figure 4. Significant effect of hearing aid condition on listener mismatch negativity (MMN) amplitudes. Points represent estimated marginal means, and error bars represent 95% confidence intervals of these means. Horizontal bar indicates significant post-hoc contrast (*p < 0.05).
These results suggest that the advantages associated with AF technology can be observed in stronger brain activity related to the maintenance and evaluation of predictions for speech in a cocktail party scenario.
Discussion
Our results show that AF technology enhances listeners’ tracking of changing phonemes from a single talker in a cocktail party situation. This is evidenced by larger MMN amplitudes evoked by deviant phonemes in the AF relative to non-AF conditions. We speculate that the increased contrast between the focus (front) and surrounding (back) processing streams made possible by AF split-processing allowed listeners to make stronger predictions about the acoustic features of speech coming from the front. This enhanced the salience of the difference between standard and deviant phonemes.
Because our MMN experiment did not require listeners’ active participation, the behavioral advantages observed in the phonetic discrimination test and in the speech-in-noise tests reported previously6 are likely bottom-up in nature. In other words, AF technology provides the auditory brain with the cues it needs to make the predictions that maintain the acoustic features of a single talker as separate from the surrounding noise/babble without the need for top-down processes. By supporting this kind of bottom-up detection of phonetic contrasts, AF could also reduce the effort/fatigue experienced by the wearer when trying to communicate in noisy environments.
In addition to demonstrating the efficacy of AF processing, this study also demonstrates how the MMN can be used to better understand the ways in which hearing aid processing interacts with ASA mechanisms performed by the brain. Further developing this understanding should help to design and evaluate future features that enhance the contrast between different audio sources in noisy environments.
References
- Bregman AS. Auditory Scene Analysis: The Perceptual Organization of Sound. 1st ed. The MIT Press;1990.
- Friston KJ, Sajid N, Quiroga-Martinez DR, Parr T, Price CJ, Holmes E. Active listening. Hear Res. 2021;399:107998.
- Winkler I, Czigler I. Evidence from auditory and visual event-related potential (ERP) studies of deviance detection (MMN and vMMN) linking predictive coding theories and perceptual object representations. Int J Psychophysiol. 2012;83(2):132-143.
- Paavilainen P. The mismatch-negativity (MMN) component of the auditory event-related potential to violations of abstract regularities: A review. Int J Psychophysiol. 2013;88(2):109-123.
- Taylor B, Høydal EH. Backgrounder Augmented Focus. [Signia white paper.] https://www.signia-library.com/scientific_marketing/backgrounder-augmented-focus/. Published 2021.
- Jensen NS. Høydal EH, Branda E, Weber J. Augmenting speech recognition with a new split-processing paradigm. Hearing Review. 2021;28(6):24-27.
- Watson AB. QUEST+: A general multidimensional Bayesian adaptive psychometric method. J Vis. 2017;17(3):10.

CORRESPONDENCE can be addressed to Dr Slugocki at: [email protected].
Citation for this article: Slugocki C, Kuk F, Korhonen P, Ruperto N. Using the mismatch negativity (MMN) to evaluate split processing in hearing aids. Hearing Review. 2021;28(10):20-23.



