
Tech Topic | October 2017 Hearing Review
The recently enhanced Audibility Extender (AE) in Widex BEYOND hearing aids contains several new features and reflects our evolving knowledge about cognitive factors in listening so that a wider range of hearing aid users receive maximum benefit from this technology.
The first commercially successful frequency lowering device was introduced by Widex in 2006.1 The Audibility Extender (AE) resulted in statistically significant benefits in adults and children with unaidable high-frequency hearing loss.2-4 In recent years, Widex has sharpened its design rationale by incorporating knowledge and understanding from the cognition field. The resulting design rationale, called Effortless Hearing, prompted us to look at how each feature may be designed and implemented so the listeners expend the least effort to receive the most optimal benefits with the use of each hearing aid feature. In this article, we describe how the Effortless Hearing design rationale is applied to the use of frequency lowering in the BEYOND hearing aid.
ASA & ELU: Cognitive Models of Language Understanding
In a previous paper,5 we reported that language understanding is achieved through two processes. One is a process of analysis and synthesis called Auditory Scene Analysis (ASA), described by Bregman.6 This is followed by another process whereby a series of “matching” with the internal representations is used to reveal the identity and meaning of the external speech sounds. Ronnberg et al7,8 described this process with their Ease of Language Understanding (ELU) model.
Auditory Scene Analysis (ASA). During this process, the multi-modal linguistic inputs are segregated and recombined into meaningful units called “auditory objects.” Spectro-temporal characteristics of the sounds—including the onsets and offsets, harmonic structures, etc—are utilized over time in order to synthesize the auditory objects for further processing. A more complete set of input cues and minimal interference (ie, from hearing loss, masking, transmission quality) are prerequisites for good object formation. This process also requires listeners to steer their attention towards the right target sounds. A lack of sufficient attention, motivation, or attendance to the wrong targets could lead to a failure of object formation.
Ease of Language Understanding (ELU) model. The second process is the “matching” process. During this step, the formed auditory objects go through an episodic buffer for implicit processing where they are matched to the phonological representation (learned information) in the long-term memory (LTM) of the listeners. This stage of implicit processing is automatic, subconscious, effortless, and likely age-independent. Understanding occurs when a match is made.
If a mismatch occurs, so that understanding is not immediate, explicit processing is required. During this stage of conscious processing, the input signals are stored temporarily in the working memory of the listeners. Information from the LTM is retrieved and iterative rematching is attempted for resolution. Context, listener experience, information from other sensory modalities (visual, tactile, etc), language competence, and use of compensatory strategies are involved until a match or a decision is made.
This back-and-forth process of fine-tuning the match requires effort and expenditure of cognitive energy. The more difference there is between the auditory objects and the phonological representation, the more difficult the task and more effort required. If a task becomes too difficult, the listener may give up on the task.
Thus, motivation is an important part in maintaining attention/effort and ensuring success in language understanding. Items that form meaningful matches are understood. Repeated exposure to the same stimulus-response pattern (such as from training) strengthens the connections or match. Learning occurs when information is transferred into long-term memory. This “learned” information forms a new phonological representation and becomes the basis for future matching.
The success of the explicit processing is likely dependent on the working memory capacity of the individual listeners. Working memory (WM) is defined as “retention of information in conscious awareness…for its manipulation and use in guiding behavior.”9 People with a good working memory have a higher likelihood of success in understanding because they can store more information in the temporary storage and use it in their iterative processing. Therefore, they are able to handle more complex tasks, respond faster, and with less effort. They are less affected by distortions or gaps in the input because they can overlook the distorted information and/or fill in the missing information.
On the other hand, those with a poor WM may not have the same abilities as those with a better WM. The size of the WM varies among individuals and generally decreases with age. In addition, the momentary size of the WM is affected by the motivation of the individuals. Those who are sufficiently motivated on a task will likely use the full potential of their WM, while those who are unmotivated may not.
Thus, the naturalness of the sounds should be preserved as much as possible for successful language understanding with the least effort. In addition, listeners must be motivated to remain engaged in the listening task. They need to have sufficient WM to accomplish the listening task. Training or repeated exposure to the same stimulus/response pattern reinforces the connection for learning to occur.
Explaining Frequency Transposition Using a Cognitive Model
A review of the Audibility Extender (AE). The AE uses linear frequency transposition. High-frequency sounds above a particular frequency (called start frequency, or SF) are transposed one octave down to a lower frequency (called the target region) and mixed with the lowered frequencies to form the new sound.
Until recently, sounds above the start frequency were not amplified. Sounds below the start frequency (that included the original sounds and the filtered transposed sounds) are amplified so its output level is audible. The interested readers are referred to Kuk et al1 for a detailed review.
The cognitive model applied to the AE. An immediate conclusion from the action of the AE is that the transposed sound would be different from the original aided sound in several ways. Figure 1 shows the spectrogram of the word “spot” with amplification (left) and transposition (right). It is assumed that the person using the transposition has no aidable hearing above 3000 Hz (which is used as the start frequency).
1) The transposed sounds have a restricted bandwidth. In contrast to the amplified spectrogram on the left of Figure 1, the spectrogram on the right (AE sound) has minimal output above the start frequency of 3000 Hz. This is because sounds above the start frequency are not amplified. This is definitely unnatural for someone with normal hearing. The perception to someone with a significant high-frequency hearing loss may vary depending on the nature of the loss.

Figure 1. Spectrogram of the word “spot” amplified (left) and transposed (right). The “red” and “yellow” areas are frequencies with a high intensity. The “blue” areas are frequencies with a lower intensity.
- Those who have usable but unaidable high frequencies (because of severity of loss and limitations of hearing aids). Not amplifying the highs may not alter their perception at soft and medium levels from the traditional manner of amplification since they have been missing those high frequencies. However, at a high input level, these individuals could conceivably hear the high-frequency output of the hearing aids. Thus, not amplifying the high frequencies may degrade the naturalness/intelligibility of the high- frequency sounds at such levels. A broad bandwidth could make the ASA and matching processes easier.
- Those who have an unusable high-frequency loss (eg, a dead region) that may or may not be aidable. The impaired wearers may not notice any difference between amplifying versus not amplifying the high- frequency sounds at the soft and medium levels. Indeed, Mackersie et al10 and Cox et al11 reported no negative consequences with amplification at these input levels even with a diagnosis of a dead region. On the other hand, Moore and Malicka12 reported distortion and poorer speech understanding in people with a dead region. Mackersie et al10 reported reduced speech understanding in people with a dead region only at high input levels. Brennan et al13 reported that people with a more severe hearing loss preferred a narrower bandwidth. Cox et al11 suggested that people with a dead region may prefer a limited bandwidth in laboratory tests. One consistency among these mixed results is that interference from the dead region can occur in some candidates if one amplifies the high frequencies. For those individuals, a narrower bandwidth could reduce the amount of interference compared to a full bandwidth. Cox et al14 estimated that about one third of individuals with a high-frequency hearing loss may have a dead region.
In both cases, the transposed sounds are different from the representations of sounds in the listeners’ long-term memory. Implicit processing alone is insufficient to match the sounds for meaning. This will increase the listeners’ effort to understand the transposed sounds because explicit processing is involved.
One commercial solution is to proceed with transposition while keeping the full amplified bandwidth. This could potentially be a solution for those who use transposition to overcome the limitation of the hearing aid’s limited bandwidth. It may also sound more “natural” than the restricted bandwidth to those with a normal or mild hearing loss. Figure 2 shows the spectra of the original sounds (red) and the transposed sounds with the full bandwidth (black line) and restricted bandwidth (green). Two spectral peaks are seen with the full bandwidth case.
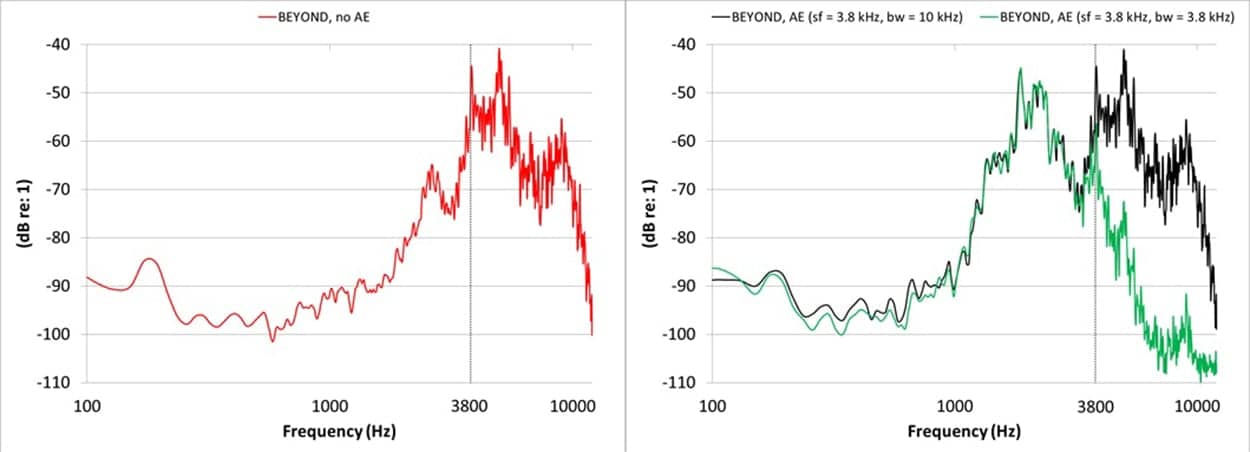
Figure 2. Spectra of a sound (a) original spectrum with single peak (red), (b) transposition with restricted bandwidth (green), and (c) transposition with full bandwidth (black). Note the double spectral peaks in the full bandwidth case.
There are two potential problems with keeping a broad bandwidth. First is that the transposed sounds (eg, transposed /s/ now in the 2000 Hz region) are heard with the un-transposed, amplified sounds (/s/ at 4000 Hz) simultaneously. The sounds in the source region could create a distraction for the transposed sounds and decrease their salience, making them more difficult for the brain to form meaningful connections between the new transposed sounds and their targeted objects.
As indicated above, a potential problem with a full bandwidth is the potential distortion for people with a dead region under at least some listening conditions. When listening to recordings of speech, music, and birds—one with a dead region (ie, distortion) above 3000 Hz, and one without any distortion (but with hearing loss of same degree)—the effect of a simulated “clipping distortion” loss above 3000 Hz with transposition (start frequency at 3000 Hz) between a narrow bandwidth (up to 3000 Hz) and a broad bandwidth (up to 10 kHz) becomes apparent. When distortion is not present, the audio recordings with the broad bandwidth sound reasonable and natural. On the other hand, when the loss results in distortion, the recordings with a narrower bandwidth sound cleaner, more natural, and less confusing. (Editor’s note: Dr Kuk had supplied HR with a series of sound samples for demonstration purposes. However, due to a technical problem, we are currently unable to provide these samples.)
2) The transposed sounds are spectrally different from the original sounds. In addition to the narrower bandwidth, the transposed sounds include a mixture of the original low-frequency sounds and the transposed high-frequency sounds (which are now low frequencies). A common myth is that this mixing results in masking of the low-frequency sounds. It is important to realize that speech is a timed sequence of acoustic events, with each sound occurring at a specific time. Thus, when the /s/ sound in “spot” shown in Figure 1 is transposed from 4000 Hz to 2000 Hz, it does not overlap with any existing sounds at that specific time. Thus, no simultaneous masking of sounds from the same source occurs.
The fact that the transposed /s/ sounds more like /sh/ is due to the fact that its dominant frequency is now moved to 2000 Hz. This observation will be true for both frequency transposition and frequency compression as long as the 4000 Hz is moved to a 2000 Hz region. This change in dominant frequency associated with frequency lowering suggests that implicit processing will likely be insufficient to obtain a match. New stimulus-response associations, achieved through repeated explicit processing and training, would seem necessary for the wearer to perceive the lowered /s/ sounds (with dominant frequency at 2000 Hz) as a natural /s/ sound. Naturally the spectra of the lowered /s/ and the /sh/ sounds should be different enough for ease of learning.
The manner in which the original sounds mix with the transposed sounds could impact the sound quality of the transposed sounds. A voiced phoneme has a fundamental frequency characterized by the spacing of the harmonics. During transposition, it is possible that the harmonics (ie, between the original sound and the transposed sounds) do not always align (Figure 3). The closer spacing between harmonics gives the impression of a more echoic sound image. In addition, the poorer sound quality could discourage the wearers from listening in the transposition mode.

Figure 3. Illustration of the effect of misalignment during frequency transposition. Sound quality is preserved when the harmonics are aligned (in middle panel); otherwise, artifacts like an echoic sound may be perceived (bottom panel) if the harmonics are not aligned.
All these actions (of mixing the original and transposed sounds with a restricted BW) during transposition suggest that a new sound image will be presented to the individual for object formation and matching. This likely makes the ASA process more difficult, and guarantees limited success with implicit processing alone. In other words, effortful, explicit processing would be indicated.
It was indicated earlier that the success of explicit processing is highly dependent on the task difficulty and the cognitive level of the listeners. People with a good working memory are likely to learn the identity of the transposed sounds quicker and make them part of their long-term memory sooner than people with a poorer WM. However, the listener has to be suitably motivated to accept the transposed sounds.
Thus, the desirable frequency lowering algorithm must consider the nature of the listeners’ high-frequency hearing loss (unusable or unaidable) and their cognitive backgrounds. In addition, the potential candidates have to be motivated to accept the new sound image. It is interesting to note that Arehart et al15 showed that those with a poorer WM performed worse with more frequency compression. On the other hand, Ellis and Munro16 were unable to link cognitive ability with success on the use of frequency compression. More studies are needed to confirm how cognitive skills affect outcomes when frequency lowering is employed.
The Enhanced AE in the BEYOND
The frequency transposition algorithm used in the BEYOND hearing aid is redesigned over the earlier version so it can be individualized based on the etiology of the loss (presence of dead region) and the cognitive background of the wearers.
Individualization based on etiology of hearing loss. It was alluded to earlier that the etiology for the high-frequency loss (ie, with or without distortion) could have different consequences from the use of a broad output bandwidth. An adjustable output bandwidth may be desirable. Those without a dead region and good WM may have transposition with a broad bandwidth; those with a distorting dead region may have a restricted bandwidth.
One enhancement in the BEYOND AE is a variable Output Frequency Range (OFR). This option allows the clinician to specify the amplification bandwidth in the AE mode from as low as the start frequency to a full bandwidth of 10 kHz in one-third octave intervals. Figure 4 illustrates a start frequency at 3000 Hz with two output bandwidths—one at a bandwidth of 4900 Hz, and one with a broader bandwidth up to 7000 Hz. Note the absence of gain in the 6000 Hz channel for the narrower bandwidth case (ie, 4900 Hz). AE candidates who have a documented dead region in the high frequencies, measured through the use of the TEN test17 or some other means, may use a restricted bandwidth up to the frequency where the dead region begins.

Figure 4. SoundTracker Audibility Extender (AE) display of output spectrum for two bandwidths at 4900 Hz (left) and 7000 Hz (right).
The individualized OFR may also be estimated through pair-wise comparison of listener preference. Recall that the perception from a dead region is distortion of sounds and reduced speech recognition. One may solicit subjective judgments from the wearer by presenting an 85 dB SPL broadband signal (music or speech) with the AE program set to the intended start frequency. Start with the OFR set to the maximum bandwidth, and ask the wearer to listen to the sound quality of the stimuli at this OFR setting. Then adjust the OFR down by one interval (1/3) and ask the wearer for their preference between the two bandwidths (full bandwidth vs 1/3 octave lower). If the he/she prefers a narrower bandwidth, the next comparison bandwidth would be even narrower; otherwise, compare with a broader OFR setting. Repeat this adaptive iterative process until a stable preference is determined.
We conducted a study examining the preferred OFR in 10 candidates of the AE. The participants listened to music and speech stimuli at 85 dB SPL with the AE set to the default start frequency while the OFR was varied. Figure 5 shows the number of individuals who preferred a specific bandwidth. Data points falling on the diagonal are those whose preferred bandwidths were the same as the start frequency (ie, those who did not want any amplification beyond the start frequency). There are several observations. First, only 3 listeners in the speech condition and one listener in the music condition preferred a BW limited to the SF. For speech stimuli, 6 of the 10 listeners preferred a BW that was 2 intervals (or 2/3 octaves) above the start frequency, whereas 5 of the 10 subjects showed the same preference for music. Thus, the default OFR of 2 intervals on the BEYOND (indicated as the dotted line above the diagonal) would have covered half to two-thirds of the AE candidates. The other listeners likely used a broader BW; however, no one preferred the broadest BW. Indeed, only one listener in the music stimulus condition (of the 20 possible) preferred the broadest 10 kHz bandwidth.
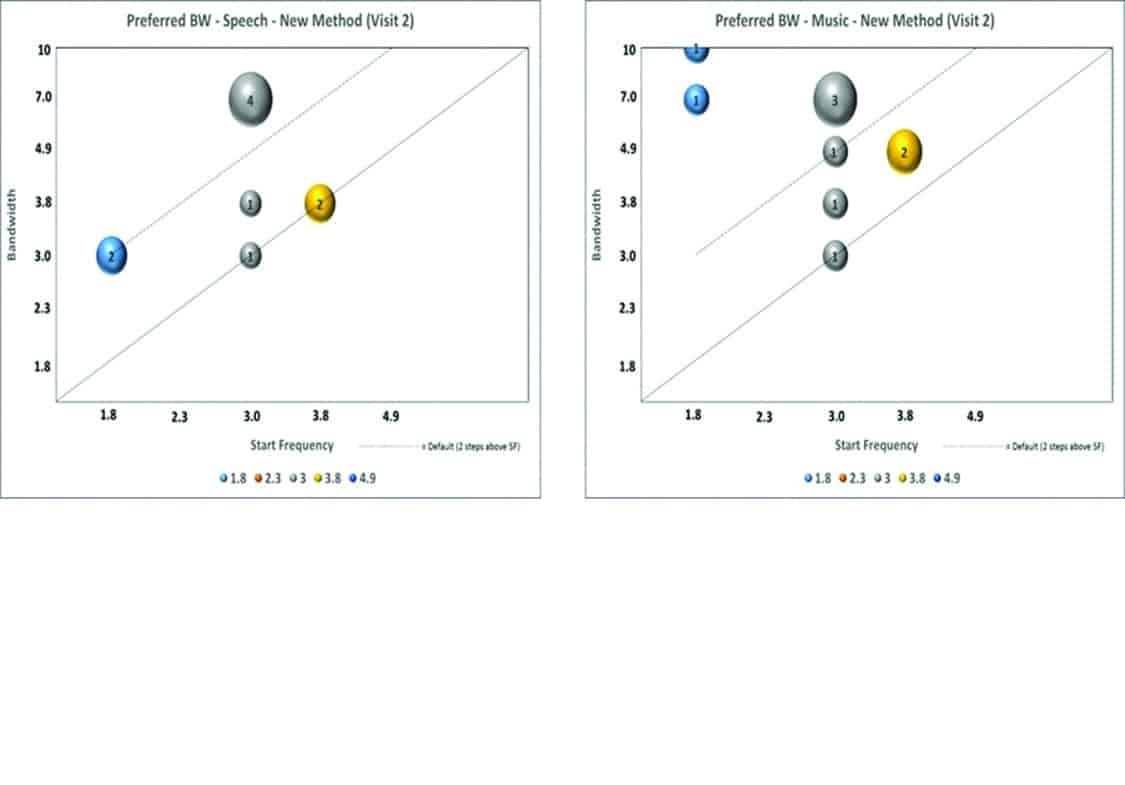
Figures 5a-b. Frequency of preferred output frequency range (OFR) for: A) speech, and B) music at the default start frequency. Numbers in each bubble represent the number of wearers preferring the indicated setting.
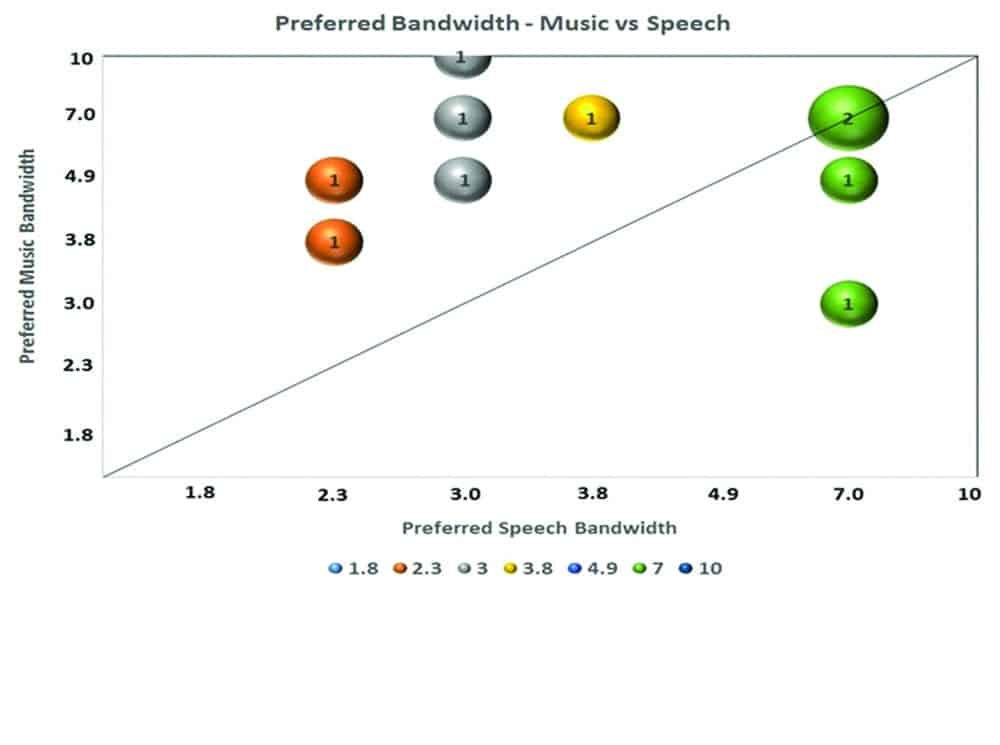
Figure 6. Comparing the preference for output frequency range between the use of music (y-axis) and speech (x-axis) as stimuli.
Figure 6 compares the preference in OFR between using speech and music as the stimuli. Again, data points on the diagonal are those who had the same preference in OFR for the two types of stimuli. Only 2 listeners showed the same OFR of 7 kHz for music and speech. Six of the remaining listeners preferred a broader BW for music than for speech, while only 2 preferred a broader BW for speech than for music. Thus, if music listening is one of the main uses for the AE program, one may increase the OFR by at least one interval (1/3 octave) over that measured with speech. This is also in line with the observation that a broader bandwidth is preferred for music listening in candidates for frequency lowering.18
Enhancing an AE Fitting Based on Individual Cognitive Level or WM
It is reasonable to expect that people with a good WM are more likely to achieve matching and adapt to the transposed sounds so these sounds become part of the LTM sooner than people with a poorer WM. This knowledge may help to explain the outcome of the AE fittings—but it may do little to improve the satisfaction with the AE fitting. On the other hand, if one can enhance the algorithm (and the fitting) so that minimum effort is required from the listeners, both people with good and poor WM may be successful without the clinicians’ knowledge of their patients’ cognitive backgrounds.
This line of thinking forms Widex’s Effortless Hearing (EH) design rationale.5 EH creates hearing aid features with the goal of minimizing listener effort during language understanding (and listening in general). In the case of frequency transposition, the EH rationale aims to maximize the likelihood of a match between the acoustic sound and the internal representation during the initial visit. That could be problematic since the frequency-transposed sounds would not be part of the listener’s LTM. Thus, a logical adjustment is to start with the minimal (but detectable) difference between the transposed sounds and the listeners’ phonological representation at the initial fitting, train the listeners on the transposed sounds, and slowly increase the amount of transposition until the desired target is reached. This protocol of the enhanced AE fitting is shown in Figure 7.
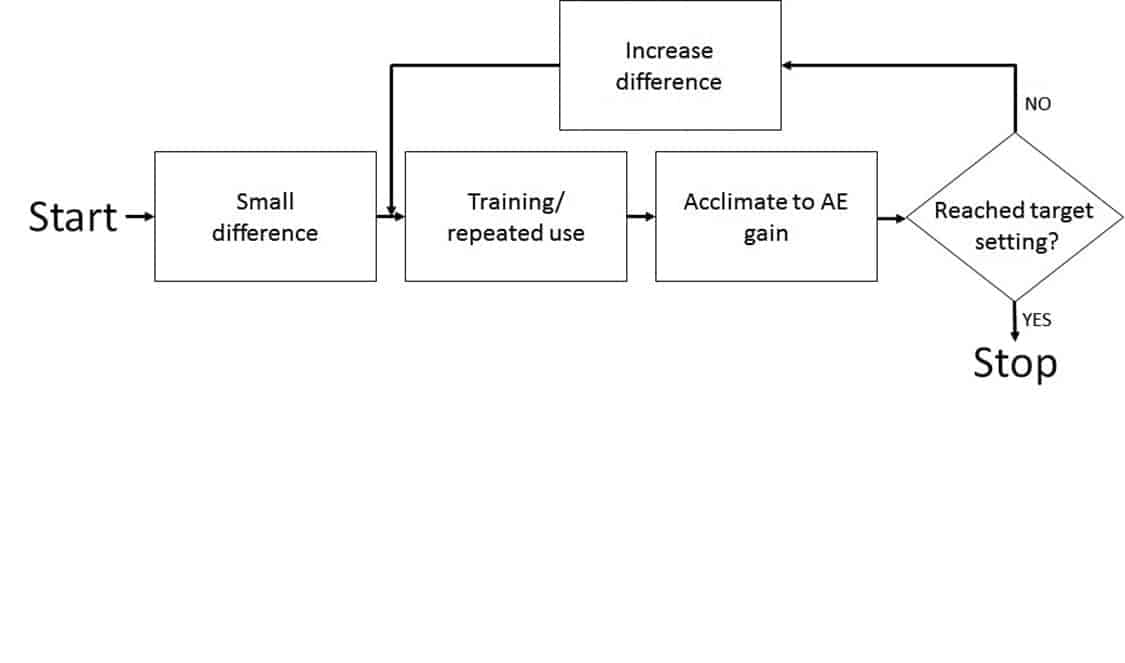
Figure 7. Block diagram showing the steps designed to ensure Effortless Hearing in AE candidates.
1) Starting with minimal difference between natural and transposed sounds. As indicated earlier, transposed sounds are different from the original sounds in their output bandwidths, output spectra, and overlaps in the harmonics. In order to minimize the mismatch in the output bandwidth, it may be worthwhile to consider an initial OFR of 7 kHz (as indicated previously, none of the listeners in the pilot study preferred a full 10-kHz bandwidth), and then slowly narrowing the bandwidth in 1/3 octave steps, if necessary.
The default SF used in the BEYOND has already considered the potential of initial mismatch and has been refined accordingly over the previous versions. To further minimize the initial mismatch, one may start with the highest SF (at 4.9 kHz) and gradually decrease the SF to the target start frequency over time.
To circumvent the occurrence of mis-alignment of the harmonics and to preserve the naturalness of the transposed sounds, a Harmonic Tracker is included in the BEYOND. This automatic algorithm tracks the harmonics of the transposed sounds to make sure that they are aligned with the original sounds to minimize echoic artifacts. Figure 8 shows the difference in the mixed signal with (left) and without (right) harmonic tracking. The online version of this paper also has an audio example of this sound.

Figure 8. Audio sample of the effect of Harmonic Tracker on the AE (left with harmonic tracking and right without harmonic tracking).
The BEYOND AE also uses a Speech Detector to distinguish between voiced (in all channels) and unvoiced (only above 2000 Hz) sounds. When a voiced speech sound is detected, it is transposed at a lower AE gain level than an unvoiced sound (which is transposed at maximum AE gain). This minimizes any masking by the transposed voiced sound in the target region, and adds to the salience of the unvoiced transposed sounds.
All these enhancements preserve the sound quality of the transposed sounds and make it less different from the original sounds. This also demands the least amount of listening effort from listeners. Minimizing the amount of initial mismatch may also motivate the listeners to continue using the AE algorithm, increase their experience with the new sound image (ie, learning), and increase the likelihood of initial acceptance.
2) Training with transposed sounds. One of the key findings in cognition is that learning occurs after the same stimulus-response pattern is repeated. Thus, for the minimally transposed sounds to become part of the listeners’ long-term memory, they need to be heard repeatedly. In that regard, formal auditory training is beneficial. Widex has developed a training program19 to supplement the use of the AE. Training may also take place in less formal manners, such as watching captioned TV or movies. All these activities provide opportunities for wearers to practice listening to the new sounds and associate those sounds with their meanings.
3) Using AE gain acclimatization. The transposed sounds are amplified so they are approximately 5 to 10 dB above the hearing loss at that frequency. To gradually ease the listeners into accepting the transposed sounds, the BEYOND AE has an AE Gain Acclimatization feature. Once activated, the target AE gain is reduced by 6 dB at the time of fitting, only to automatically increase in ½-dB-steps per day until the full target AE gain is restored in 12 days after fitting. This minimizes the amount of initial mismatch and makes it easier (less effortful) for acceptance of the AE sounds. The automatic gain change makes it easier for the clinicians and the wearers to reach the final target AE gain. Glista et al20 also demonstrated the need for acclimatization in the use of frequency lowering in children.
In summary, the new features in the BEYOND AE—specifically the Harmonic Tracker, Speech Detector, flexible Output Frequency Range (OFR) and Start Frequency (SF), and the AE acclimatization—are designed to improve the likelihood of initial match between the transposed sounds and the phonological representations in the listener’s long-term memory. This minimizes the need for explicit processing and could benefit people of all cognitive backgrounds.
4) Decreasing start frequency until the default is reached. It takes approximately one month for the typical listener to accept the transposed sounds when the AE is set to the target start frequency.4 It is conceivable that this “minimal difference” approach, which uses concepts from existing cognitive models, may lead to a shorter adaptation period. Regardless of the adaptation time, it is important for the wearers to return at regular intervals (2-4 weeks) so the start frequency can be lowered systematically for graduated exposure to the transposed sounds until the default start frequency and target AE gain is reached.
The enhanced AE used in the BEYOND hearing aid is designed using Effortless Hearing design rationale. The new features reflect how cognitive factors are considered in the design process in order that people of all cognitive backgrounds may receive the maximum benefit from its use.
Acknowledgement
The authors thank Mary Cay Chisholm, AuD, at the Northwest Speech and Hearing Clinic in Arlington Heights, Ill, and her patients for participating in the data collection.
Editor’s Note: Dr Kuk has supplied HR with a series of recordings that simulate

Correspondence can be addressed to Dr Kuk at: [email protected]
Citation for this article: Kuk F, Seper E, Korhonen P. Audibility extender: using cognitive models for the design of a frequency lowering hearing aid. Hearing Review. 2017;24(10):26-34.
References
-
Kuk F, Korhonen P, Peeters H, Keenan D, Jessen A, Andersen H. Linear frequency transposition: Extending the audibility of high frequency information. Hearing Review. 2006;13(10):42-48.
-
Auriemmo J, Kuk F, Lau C, et al. Effect of linear frequency transposition on speech recognition and production of school-age children. J Am Acad Audiol. 2009;20(5):289-305.
-
Kuk F, Peeters H, Keenan D, Lau C. Use of frequency transposition in a thin-tube, open-ear fitting. Hear Jour. 2007;60(4):59-63.
-
Kuk F, Keenan D, Korhonen P, Lau C. Efficacy of linear frequency transposition on consonant identification in quiet and in noise. J Am Acad Audiol. 2009;20(8):465-479. DOI: 10.3766/jaaa.20.8.2
-
Kuk F. Going BEYOND: A testament of progressive innovation. Hearing Review. 2017;24(1)[Supp1]:3S-22S.
-
Bregman A. Auditory Scene Analysis: The Perceptual Organization of Sound. Cambridge, MA: MIT Press;1990.
-
Rönnberg J, Rudner M, Foo C, Lunner T. Cognition counts: A working memory system for ease of language understanding. (ELU). Int J Audiol. 2008;47: Suppl2:99S-105S. DOI: http://dx.doi.org/10.1080/14992020802301167
-
Rönnberg J, Lunner T, Zekveld A, et al. The Ease of Language Understanding (ELU) model: theoretical, empirical, and clinical advances. Front Syst Neurosci. July 13, 2013;7: article 31. DOI: https://doi.org/10.3389/fnsys.2013.00031
-
Pichora-Fuller MK, Kramer SE, Eckert MA, et al. Hearing impairment and cognitive energy: the Framework for Understanding Effortful Listening (FUEL). Ear Hear. July/Aug, 2016;37[Supp1]: 5S-27S.
-
Mackersie CL, Crocker TL, Davis RA. Limiting high-frequency hearing aid gain in listeners with and without suspected cochlear dead regions. J Am Acad Audiol. July/August, 2004;15(7):498-507.
-
Cox RM, Johnson JA, Alexander GC. Implications of high-frequency cochlear dead regions for fitting hearing aids to adults with mild to moderately severe hearing loss. Ear Hear. Sept/Oct, 2012;33(5):573-587.
-
Moore BCJ, Malicka AN. Cochlear dead regions in adults and children: diagnosis and clinical implications. Semin Hear. 2013;34(1): 37-50.
-
Brennan MA, McCreery R, Kopun J, et al. Paired comparisons of nonlinear frequency compression, extended bandwidth, and restricted bandwidth hearing aid processing for children and adults with hearing loss. J Am Acad Audiol. Nov-Dec, 2014;25(10):983-998.
-
Cox RM, Alexander GC, Johnson J, Rivera I. Cochlear dead regions in typical hearing aid candidates: prevalence and implications for use of high-frequency speech cues. Ear Hear. May/June,2011;32(3): 339-348.
-
Arehart KH, Souza P, Baca R, Kates JM. Working memory, age, and hearing loss: susceptibility to hearing aid distortion. Ear Hear. May/June, 2013;34(3):251-260. doi: 10.1097/AUD.0b013e318271aa5e
-
Ellis RJ, Munro KJ. Predictors of aided speech recognition, with and without frequency compression, in older adults. Int J Audiol. March, 2015;54(7):467-475. doi: 10.3109/14992027.2014.996825
-
Moore BCJ. Testing for cochlear dead regions: audiometer implementation of the TEN(HL) Test. Hearing Review. 2010;17(1):10-16,48.
-
Mussoi BSS, Bentler RA. Impact of frequency compression on music perception. Int J Audiol. 2015;54(9): 627-633. doi: 10.3109/14992027.2015.1020972
-
Kuk F, Keenan D, Peeters H, Lau C, Crose B. Critical factors in ensuring efficacy of frequency transposition II: facilitating initial adjustment. Hearing Review. 2007;14(4):90-96.
-
Glista D, Scollie S, Sulkers J. Perceptual acclimatization post nonlinear frequency compression hearing aid fitting in older children. J Speech Lang Hear Res. December, 2012;55(6): 1765-1787. doi:10.1044/1092-4388(2012/11-0163)



