
Since the popularization of non-linear hearing instruments, there has been much discussion on the appropriateness of threshold-based fitting rationales (NAL-NL1) versus those rationales that use individual loudness growth functions. In this article, the NAL-NL1 fitting rationale, which emphasizes speech intelligibility, is compared to the IHAFF fitting rationale, a loudness normalization approach. The authors contend that the differences between these two fitting strategies are not inconsequential. In fact, they can yield audibly different prescriptive results that have perceptual consequences for the hearing aid user, particularly in the case of flat or steeply sloping losses.
An extensive study to evaluate the new NAL-NL1 procedure for fitting non-linear hearing aids has recently been completed by the National Acoustic Laboratories (NAL) in Australia. (For a tutorial on using the NAL-NL1 procedure, see the November 1999 HR, pages 8-20.) One of the aims of this study was to compare the NAL-NL1 fitting rationale (speech intelligibility maximization) to the more common loudness normalization fitting rationale.
To prescribe loudness normalization in the evaluation study, the IHAFF protocol was chosen.1 This is because the IHAFF protocol is based on a pure loudness normalization technique: the amount of gain prescribed at any given frequency and input level is that needed (in dB) by the hearing-impaired client to rate the sound intensity the same as it is rated by normal-hearing listeners. Further, IHAFF uses individually measured loudness growth functions to prescribe gain whereas NAL-NL1 is a threshold-based fitting procedure.
The methodology used in the evaluation study and the analyses of data collected in the study are described in detail in two reviewed papers.3,4 The aim of this article is to take a closer look at the differences between the two fitting rationales (speech intelligibility maximization vs loudness normalization) relative to goals, prescription targets, ease of fitting, and patient acceptance in real-life listening situations. While it should be recognized that, due to pragmatic/time issues, few clinicians use the IHAFF protocol in their practices, the approach is nonetheless based on sound clinical premises, and it remains a good representative of the loudness normalization approach.
Normalization vs Speech Intelligibility Maximization
The goal of loudness normalization procedures (like IHAFF) is to present the amplified frequency-specific and overall loudness of sounds for the hearing-impaired client so that those sounds replicate the loudness levels perceived by normal-hearing (unaided) listeners. This is achieved by comparing loudness data measured on the hearing-impaired client, using a narrow-band test stimulus, with loudness data measured on a group of normal-hearing listeners. The relevant loudness data are obtained by administering a loudness test with known normal loudness data to the client (eg, the Contour test5 within IHAFF2), or by using average loudness data predicted from the hearing threshold level (eg, FIG66). Of the prescriptive procedures and proprietary methods currently available for fitting non-linear hearing aids, the majority are based on restoring loudness to normal levels.
Conversely, NAL-NL1 does not aim at normalizing frequency-specific loudness. Instead, its overall goal is to maximize speech intelligibility for every input level with the constraint that the overall loudness of speech should not exceed the overall normal loudness of speech. In achieving this aim, NAL-NL1 often tends to prescribe gain resulting in the loudness equalization—as opposed to normalization—of speech bands.
Differing Approaches to High Frequency/Sloping Losses
What is the difference in effect between equalizing and normalizing loudness of speech bands? Consider two issues:
1) The low frequency components of speech have more energy than the high frequency components. In the normal ear, the low frequency components of speech are therefore perceived as being louder.7
2) Relative to speech, steady background noises are typically low-frequency weighted,8 so the normal ear is generally exposed to far more loudness across the low rather than across the high frequencies.
When a hearing aid fitting normalizes loudness, there is an attempt to recreate the differences in the relative loudness of high and low frequency bands (ie, the same as they would be perceived by normal-hearing listeners). As both speech and many common background noises are dominated by energy in the low frequencies, the hearing-impaired client may suffer from the effect of upward spread of masking, especially with respect to hearing the softer, high frequency components of speech.
The effect from upward spread of masking is reduced by presenting the speech bands equally loud. To achieve equal loudness of speech bands, relatively less gain is prescribed in the low frequencies compared to the high frequencies, even for someone with a flat hearing loss. This strategy will also reduce the intensity in the low frequencies of general background noises, thus improving the overall signal-to-noise ratio. Therefore, if there is a hearing loss in the low frequencies, NAL-NL1 is likely to prescribe less gain in this frequency region than the loudness normalization procedures.
In focusing on speech intelligibility maximization, NAL-NL1 has introduced a “desensitization factor.” This has the effect of limiting the amount of gain prescribed at frequencies where the hearing loss is severe (>60-80 dB HL depending on the frequency). This is because research on such losses suggests that audibility of speech at these frequencies makes a diminished—or even negative—contribution to speech intelligibility.9-11
What is the effect of the desensitization factor introduced in NAL-NL1? Again, consider speech as the input signal. If speech at any frequency is audible to the normal ear, a loudness normalization rationale will prescribe the amount of gain needed to make speech (at the various frequencies) audible and equally loud relative to the hearing-impaired ear. If the loss is severe in the high frequencies, more gain is applied to that region. It is likely that this amount of gain does not make speech any more intelligible than would a lesser amount of gain. Furthermore, the gain may make the perceived speech signal so loud that the hearing aid wearer turns down the volume, which will reduce speech information at all other frequencies, as well.
The desensitization factor in NAL-NL1 results in the gain being kept down at frequencies where the hearing loss is severe, making it possible to provide more gain at other frequencies where hearing is better, while maintaining a comfortable overall loudness of speech. As a result of the desensitization factor, NAL-NL1 tends to prescribe less gain than loudness normalization procedures at frequencies where a hearing loss is severe; conversely, it may prescribe more gain than the loudness normalization procedure at other frequencies for such clients.
Differences in Prescriptive Targets (NAL-NL1 vs IHAFF)
A recent paper by Byrne et al.12 demonstrated that, when using average loudness data predicted from hearing threshold levels, the insertion gain targets prescribed by NAL-NL1 and several loudness normalization procedures vary substantially for clients with flat loss, reverse sloping loss, and steeply sloping high frequency loss. In the evaluation study, we prescribed a two-channel hearing aid using NAL-NL1 and the IHAFF protocol to 16 subjects (22 ears) with mild or moderate/severe degrees of hearing loss and flat losses, and to eight subjects (14 ears) with steeply sloping high-frequency loss.
Figures 1-2 show the insertion gain curves prescribed by NAL-NL1 and IHAFF at three input levels for two pairs of subjects, each pair having a similar hearing loss. For the subjects for whom the hearing loss is very similar, NAL-NL1, which is a threshold-based procedure, prescribes almost identical insertion gain curves. Conversely, IHAFF, which is based on individual loudness growth functions, prescribes in these cases very different targets for the same hearing loss.
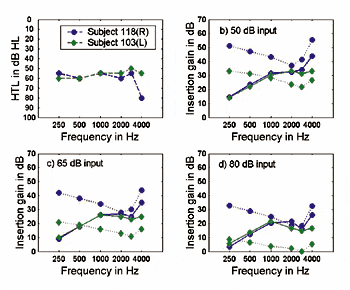
Figure 1a-d. 1a) Audiograms for two subjects with moderate flat loss; 1b) insertion gain targets for a two-channel device prescribed by NAL-NL1 (full line) and IHAFF (dashed line) for a 50 dB SPL input; 1c) for a 65 dB SPL input; and 1d) for an 80 dB SPL input. |
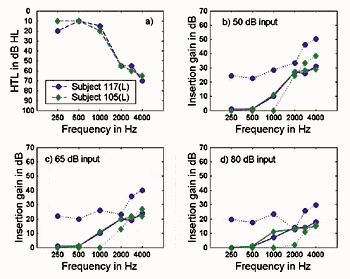
Figure 2a-d. Audiograms for two subjects with steeply sloping high-frequency loss: 2a) insertion gain targets for a two-channel device; 2b) for a 50 dB SPL input prescribed by NAL-NL1 (full line) and IHAFF (dashed line); 2c) for a 65 dB SPL input; and 2d) for an 80 dB SPL input. |
For the two subjects with a moderate flat loss (Figure 1), the insertion gain curves prescribed by IHAFF are parallel at each of the three input levels. This suggests that the two subjects during the loudness test reacted in the same way to the changes in pitch of the test stimuli, but that they had different opinions about the loudness level. That is, subject 103 rated the input levels louder than subject 118, resulting in steeper loudness growth functions. For the two subjects with steeply sloping high-frequency loss (Figure 2), the main difference in the insertion gain prescribed by IHAFF is across the low frequencies. As no gain is prescribed for subject 105 at 250 Hz, 500 Hz, and 1000 Hz, this means that the subject assigned the same, or louder, loudness categories to different input levels as normal-hearing listeners do. Generally, subject 105 rated the input levels louder than subject 117 across frequencies and across input levels. For loudness normalization procedures that use average loudness data predicted from hearing threshold levels (eg, FIG6), such variations are not seen between clients with a similar hearing loss, but the prescribed target would still differ from the NAL-NL1 target.
Because of the variation in prescription for similar audiograms when using individually measured loudness data, the difference in prescription by loudness normalization and speech intelligibility maximization may be large (Subjects 117 and 118) or may be small (Subject 105). In terms of the root-mean-square (RMS) value measured across frequency, the difference between the NAL-NL1 and IHAFF prescribed insertion gain for a 65 dB input level varied from 5.8 dB-15.6 dB for these four subjects. On average, across all 24 subjects (36 ears), the RMS difference between prescriptions for a 65 dB input level was 8.9 dB, which is quite substantial. In most cases, the difference between the NAL-NL1 and IHAFF prescription was close to what one might expect from the above data relative to input levels including 65 dB SPL. In other words, for all subjects with a low frequency loss, IHAFF prescribed more gain than NAL-NL1 in this frequency region. For all but one of the subjects with a severe loss in the high frequencies, IHAFF prescribed more gain than NAL-NL1 in the high frequencies.
Achieving the Prescribed Targets in a Two-Channel Device
Generally, the somewhat large differences in prescription targets seen above may be reduced after implementing the fitting rationales in a hearing aid. This is because the targets may not be possible to reach due to the use of vented earmolds, feedback, and the limitations of the electroacoustic characteristics of the device. Further, it is common practice to adjust the overall gain to accommodate for the hearing aid user’s preferred listening level.
In the evaluation study, we implemented the two fitting rationales both in a digital benchtop hearing aid using occluded earmolds (foam ear tips) and in a wearable digital behind-the-ear (BTE) device using custom-made earmolds. When implementing IHAFF and NAL-NL1 in the benchtop device, good matches to the prescribed targets could be achieved. In this case, the fittings were verified in a Zwislocki coupler. However, when implementing the two fitting rationales in the wearable device, problems arose in reaching the prescribed targets. Insertion gain measurements were used to verify the fittings in the BTEs. After each fitting, the subjects were asked to adjust the overall gain level so that speech presented at 65 dB SPL was comfortable and easy to understand.
Figure 3 shows the difference in insertion gain prescribed by NAL-NL1 and IHAFF for a 65 dB input level and the difference in gain achieved in each of the two test devices after allowing for adjustment of the overall gain level for each of the four subjects reported in Figures 1 and 2. When the gain difference is positive, NAL-NL1 prescribed more gain than IHAFF; when the gain difference is negative, IHAFF prescribed more gain than NAL-NL1.
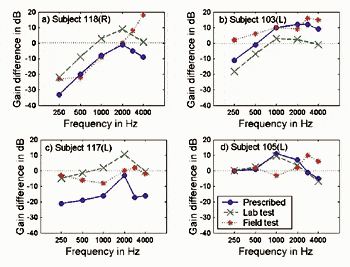
Figure 3a-d. The difference (NAL-NL1 – IHAFF) between prescribed and fitted responses for a 65 dB SPL input. The full line shows the prescribed difference, the dashed line shows the achieved difference in the laboratory, and the dotted line shows the achieved difference in the field test: 3a) Subject 118; 3b) Subject 103; 3c) Subject 117; and 3d) Subject 105. |
The dashed lines in Figure 3 show the difference between rationales as implemented in the benchtop device after adjustment of the overall level of each response to the preferred listening level. These curves have the same shape as the curves resulting from the prescriptions (ie, the targets were well met), but the curves are shifted due to the changes in overall level. In the case of Subjects 117 and 118, IHAFF in the benchtop device provided more gain than NAL-NL1 in the low and in the very high frequencies, whereas NAL-NL1 provided more gain than IHAFF across the middle frequencies. For Subject 117, the RMS difference between prescriptions was reduced by almost 11 dB whereas only small changes (from -1.3 dB to 4.0 dB) were observed for the other three subjects. On average, across all 24 subjects, the RMS difference measured based on the prescribed targets was reduced to 7.4 dB after adjustment of the overall gain levels. This difference is still substantial and would make the rationales audibly different.
The dotted lines in Figure 3 show the difference achieved between rationales after implementation and adjustment of overall gain in the wearable BTE device. These curves have a different shape than the other two curves. This is because matching the two prescriptive targets (IHAFF and NAL-NL1) with the same acoustic system was often very difficult and compromises were made. Therefore, the final differences in responses were often much smaller in the wearable device than in the benchtop device.
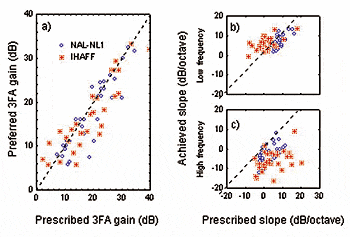
Figure 4. Fitting results for NAL-NL1 (circles) and IHAFF (asterisks): 4a) Preferred vs. prescribed 3FA gain (500 Hz, 1000 Hz, and 2000 Hz), 4b) achieved vs. prescribed low-frequency slope (250 Hz – 1000 Hz), and 4c) achieved vs. prescribed high-frequency slope (1000 Hz – 4000 Hz). |
The preferred three-frequency average gain (3FA) across 500 Hz, 1000 Hz, and 2000 Hz plotted against the prescribed 3FA gain for both rationales is shown in Figure 4A. Many subjects accepted the prescribed 3FA gain, but those who wanted a change in overall gain typically asked to have the gain reduced. Figures 4b and 4c show the achieved response slope in the low frequencies (from 250-1000 Hz) and high frequencies (from 1000-4000 Hz) as a function of the prescribed slope in dB/octave. In the low frequencies, the target was matched reasonably well in most cases with the NAL-NL1, whereas the flatter, or even reversed, slopes prescribed by IHAFF in the low frequencies were more difficult to achieve. Adverse occlusion effects were to blame for some of the discrepancies seen in Figure 4b.
In general, in the high frequencies, the prescribed slope up to 4000 Hz was difficult to reach. The success was limited partly by the electroacoustic characteristic of the hearing aid, and partly by the overall shape of the targets and feedback. Overall, the NAL-NL1 targets were easier to meet than the IHAFF targets. For the two subjects with sloping loss (Subjects 105 and 117), the RMS difference between the two achieved responses was reduced relative to the RMS difference in the prescribed responses (cf, Figures 3c and 3d). However, for the two subjects with flat loss (Subjects 103 and 118) the RMS difference between the fitted responses was about the same as the prescribed RMS difference (cf, Figure 3a and 3b). Across the 24 test subjects, the average achieved RMS difference across frequency in the wearable device was reduced to 6.0 dB, a difference that could still make the listening experience from each fitting rationale noticeably different.
User Preferences
How do the two rationales compare in everyday listening situations? Each subject compared the two rationales in a two-memory device for four weeks in individually selected listening situations that the subject experienced on at least a weekly basis. The subjects were blinded relative to the assignment of prescriptions to listening programs. After each comparison the subject was asked to rate the satisfaction with each program on a scale from “1” (Very bad) to “10” (Very good), with “5” labeled as “okay.” The subjects were also asked to describe the performance of each program. The listening situations were grouped into 13 overall listening categories, ranging from “Watching TV” to “Conversation with a group of people in noise” and “Being outdoors.”
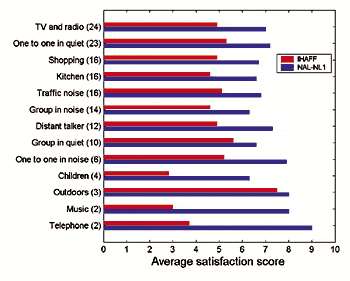
Figure 5. The average satisfaction score produced for IHAFF (red bar) and NAL-NL1 (blue bar) in each of 13 listening categories in the field. The numbers in brackets after each listening category show the number of subjects who compared the two rationales in this category. |
The average listener satisfaction score that was allocated to NAL-NL1 and IHAFF for each of the 13 listening categories is reported in Figure 5. Across all 13 categories, NAL-NL1 received, on average, a higher satisfaction score than IHAFF. Based on the difference in satisfaction score produced for each fitting rationale across the individually selected listening situations, 16 subjects rated NAL-NL1 more satisfactory than IHAFF, whereas six subjects rated IHAFF more satisfactory than NAL-NL1. Two subjects did not complete the field test.
The difference in satisfaction score varied greatly among the subjects. One hypothesis was that, if the RMS difference between amplification was small, then the subjects probably found it difficult to distinguish between the two rationales. Therefore, the satisfaction scores produced by the two rationales were likely to be very similar. In contrast, when the amplification characteristics were quite different, subjects found the speech intelligibility maximization procedure (NAL-NL1) more satisfactory.
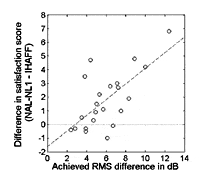
This hypothesis was tested for each subject by relating the difference in satisfaction score produced for each fitting rationale with the RMS difference measured between the fitted frequency responses for a 65 dB input level. The result is shown in Figure 6. A statistical analysis revealed that the correlation between the two factors is highly significant (p < 0.001). Note, that the six subjects rating IHAFF more satisfactory than NAL-NL1 did so by only 1 point or less on the satisfaction scale. In the laboratory, the same tendency was observed: as the RMS difference between responses for a 65 dB input increased, the magnitude of preference score for NAL-NL1 increased. However, in that case, the correlation between the two parameters was not statistically significant (p = 0.27).
Among the four subjects featured in Figures 1-3, one rated IHAFF more satisfactory than NAL-NL1 (Subject 105) and three subjects rated NAL-NL1 more satisfactory than IHAFF. Table 1 lists quotes of these subjects’ descriptions of IHAFF and NAL-NL1 in some of the more typical listening situations. The most common descriptors used by subjects preferring IHAFF were “good,” “comfortable,” and “natural.” Some of these subjects found NAL-NL1 “sharper” or “louder.” Subjects rating NAL-NL1 more satisfactory typically used descriptors such as “clear,” “natural,” and “sharp.” For those subjects for whom the difference in satisfactory scores exceeded 1-2 points, IHAFF was in comparison described as “soft,” “muffled,” and “unnatural.” Both rationales were often reported to make low-level environmental sounds, like clocks, refrigerators, footsteps, and rubbing clothes, intrusive.
| Sub- ject |
Situation | IHAFF | NAL-NL1 |
| 105 | Conversation with wife in quiet | Natural. | Less natural. |
| Conversation in bowling clubhouse | Background noise loud. | Background noise very loud. | |
| Conversation with family incl grandchildren | Comfortable. | A little too loud. | |
| Hearing the skipper on the bowling green | No trouble hearing skipper. | Not as clear as Program 2 (IHAFF). | |
| x | |||
| 103 | Conversation with husband in quiet | Reduced background noise and softer voice. | Rich, aware of background noise (clock, etc). |
| Conversation with family at dinner | For conversation, too soft, but surrounding sounds still audible. | Conversation with family is good, but surrounding sounds are amplified. | |
| Hearing speaker at senior’s meeting | Still hear a little background noise, but too soft for the speaker. | Background noise tolerable and hear the speaker well. | |
| Traveling in the car | Soft but okay. | Natural. | |
| x | |||
| 118 | Conversation with neighbor | Muffled. | Sharp and clear. |
| Hearing at Bingo | Muffled and dull. | Very good. Clear. | |
| Hearing the priest | Boomy. | Natural and clear. | |
| Loud traffic-noise from street | Too loud and boomy. | Loud but bearable. |
In summary, this study showed that, if the two rationales prescribe amplification characteristics that are not extremely different after equalizing the overall gain level, then the client shows a small preference for either rationale. However, if the resulting amplification characteristics from the two rationales differ substantially, then the client shows a predominant preference for NAL-NL1 (ie, maximizing speech intelligibility).
Conclusion
The two fitting rationales (speech intelligibility maximization and loudness normalization) process speech differently and often prescribe responses with substantial differences for clients with flat and steeply sloping loss. The RMS difference between the prescribed responses is sometimes reduced if clients are allowed to adjust the overall gain level to make conversational speech sound comfortable and/or when the device is adjusted to deal with factors such as feedback or the use of vented earmolds. However, in many cases, the RMS difference between responses is still substantial (ie, an average of 6.0 dB difference across frequencies), and hence the responses are clearly audibly different.
Generally, the targets prescribed by the speech intelligibility maximization rationale (NAL-NL1) are easier to reach than those prescribed by a loudness normalization procedure (IHAFF). The evaluation study demonstrated that, as the RMS difference between the achieved fittings increases, the preference for the speech intelligibility maximization rationale increases. The study also shows this prescriptive approach to make speech clearer in many environments.
These findings suggest that NAL-NL1 is a better starting point for fitting non-linear hearing aids. If the RMS difference between the NAL-NL1 target and a loudness normalization target is large, then the client will benefit from NAL-NL1 due to clearer and easier-to-understand speech. If the RMS difference between the two rationales is small, then the choice of prescription method is not critical.


|
Correspondence can be addressed to HR or Gitte Keidser, PhD, National Acoustics Laboratories, 126 Grenville St, Chatswood, NSW 2067, Australia; email: [email protected].
References
1. Dillon H. Prescribing hearing aid performance. In: H. Dillon, ed., Hearing Aids. Sydney: Boomerang Press; 2001: 249-261.
2. Valente M, Van Vliet D. The independent hearing aid fitting forum (IHAFF) protocol. Trends in Amplification. 1997; 2(1):6-35.
3. Keidser G, Grant F. Comparing loudness normalization (IHAFF) with speech intelligibility maximization (NAL-NL1) when implemented in a two-channel device. Ear and Hear. 2001; 22(6):501-515.
4. Keidser G, Grant F. The preferred number of channels (one, two, or four) in NAL-NL1 prescribed WDRC devices. Ear and Hear. 2001; 22(6):516-527.
5. Cox RM, Alexander GC, Taylor IM, & Gray GA. The contour test of loudness perception. Ear and Hear. 1997; 18(5):388-400.
6. Killion M, Fikret-Pasa S. The 2 types of sensorineural hearing loss: Loudness and intelligibility considerations. Hear Jour. 1993; 46(11):31-34.
7. Keidser G, Katsch R, Grant F, Dillon H. Relative loudness perception of low and high frequency speech bands, including the influence of bandwidth and input levels. J Acoust Soc Amer. 2002; 111(2):669-671.
8. Keidser G. Long-term spectra of a range of real-life noisy environments. Austral Jour Audiol. 1995; 17:39-46.
9. Ching TYC, Dillon H, Byrne D. Speech recognition of hearing-impaired listeners: Predictions from audibility and the limited role of high-frequency amplification. Jour Acoust Soc Amer. 1998; 103(2):1128-1140.
10. Ching TYC, Dillon H., Katsch R, Byrne D. Maximizing effective audibility in hearing aid fitting. Ear and Hear. 2001; 22(3):212-224.
11. Hogan CA, Turner CW. High-frequency audibility: benefits for hearing-impaired listeners. Jour Acoust Soc Amer. 1998;104:432-441.
12. Byrne D, Dillon H, Katsch R, Ching T, Keidser G. The NAL-NL1 procedure for fitting non-linear hearing aids: Characteristics and comparisons with other procedures. Jour Amer Acad Audiol. 2001; 12(1):37-51.



