
Research | February 2016 Hearing Review
Less can be more in the application of compression, time constants, and channels
The authors look back at a study from 2000 that showed short time constants and a large number of independent compression channels reduced the temporal and spectral contrast of speech when using technology of that period. Additionally, in subjective paired comparisons, long time constants, low compression ratios, and a small number of compression channels were preferred in the investigated technology configuration by normal-hearing and hearing-impaired listeners. Although hearing aid technology has improved dramatically since 2000, there are still lessons to be learned from this report.
Most digital hearing instruments offer dynamic compression in several frequency bands (multi-channel dynamic compression). Some of the underlying concepts differ greatly with respect to the number of compression channels, the applied compression ratios, and the values of the time constants involved.
As these parameters bear great influence on the spectral and temporal structure of speech output signals, a study on the subjective preference of different parameter settings was conducted in 2000, using state-of-the-art technology of that day. Speech-in-quiet comparisons were performed using a single-channel compression amplifier, a 4-channel compression amplifier, and a 16-channel compression amplifier. In each case, release times of 15 ms, 380 ms, and 1,400 ms were coupled with fast attack times.
A total of 5 normal-hearing and 5 hearing-impaired subjects participated in paired comparison tests. The normal-hearing subjects heard compression ratios of 1:1, 2:1, and 8:1. The hearing-impaired subjects had compression ratios lower than, equal to, and greater than that determined by DSL(i/o). Each subject judged 351 paired comparisons of the 27 different conditions. Using the technology available at that time, the results were consistent with few exceptions: Fewer channels of compression, longer release times, and lower compression ratios were preferred by both subject groups. While it is clear that improved technology and compression strategies have developed significantly over the last 15 years, this paper may still serve as a useful reminder of the limitations of simple multi-channel compression with short time constants. Simple, in this case, means the compression in each channel operates independently of the others.
Authors’ Note: The present paper is based on the first author’s presentations at IHCON, Lake Tahoe, Calif, also presented at the 2000 EUHA Congress in Germany.1,2
The Success of WDRC and Multi-channel Compression
When fitting for sensorineural hearing impairment using linear hearing instruments, soft sounds are typically perceived as too soft, while loud sounds are perceived as too loud. Wide dynamic range compression (WDRC) solves this problem by using gain that depends upon the input level: maximum gain for soft sounds and minimum gain for loud sounds.
Multi-channel compression (MCC) performs this task in several frequency bands independently. Often-cited advantages of MCC are frequency-dependent loudness restoration and subsequent listening comfort without the use of a volume control, audibility of soft sounds in all frequency regions, and noise reduction in the case of different frequency spectrums of (loud) noise and (softer) speech.
Today, MCC is a standard feature in every hearing instrument. However, the products and the respective fitting approaches utilize different compression ratios, multiple knee-points, advanced interdependencies across channels, and typically different time constants for attack and release in a different number of compression channels.
In contrast, the present paper reviews a study which was conducted 15 years ago to investigate the impact of basic multi-channel compression on judged sound quality, as measured by subjective preference, using independent compression in each channel. It focuses on two parameters: compression time constants and the number of independent compression channels, and how they affect speech. Of particular interest was the effect of interactions between compression time constants and compression ratios, as measured by the subjective sound quality impression of the subjects.
Multi-Channel Compression, Time Constants, and User Preference
This study was not the first one to focus on the effect of compression. It is reasonable to conclude that the use of WDRC had an important rebirth after the results of Villchur were published in 1973.3 Although the theoretical advantages of multichannel compression in hearing aids were described by Villchur, his favorable experimental results were obtained with only two channels.
When Villchur was a visiting scientist at MIT, a quick experiment in the late 1970s demonstrated that it was possible to have too much of what might have been a good thing: with a computer-based 16-channel compression system later described by Lippmann et al in 1981,4 each channel was set to an 8:1 compression ratio. While such high compression ratios are normally associated with compression limiting for loud sounds, and would never be realized in modern solutions, the result of the MIT experiment was that with a high vocal pitch, the vowels from the series “heed hid had hod hawed hood who’d” all sounded much the same. The explanation was immediately clear: Excessive compression in each of the 16 one-third-octave channels flattened the peaks in the vowel spectrum sufficiently so that they all sound nearly the same. This cannot happen with a single channel compression amplifier.
Several studies examined the effects of compression after Villchur and Lippmann’s results.5-11 Each found decreasing sound quality with increasing compression ratios and decreasing release times, but none of these focused on the number of compression channels. In general, linear processing or long release times were preferred in subjective ratings. In most cases, speech recognition was only marginally influenced by the compression ratio or the number of compression channels.
Unfortunately, systematic variations of the number of channels, compression ratio, and release time in one system are rare, and precise measurement procedures (like paired comparisons) are needed to resolve small differences between the different settings. Therefore, the experiment described here was undertaken to systematically explore the impact of different parameter settings for multiple channel compression systems, representing typical technology from around the year 2000, in the basic case where each channel operated independently of the levels in the other channels (contrary to some of current technology), and a classical “simple” attack and release time mechanism is used.
Another reason for formally reporting these earlier data was given indirectly in the data reported by Killion,12 obtained on more than 60 normal-hearing audiologists (depending on the experiment) and 27 hearing-aid wearers. In 2003, the output of a premium digital hearing aid from each of the six major manufacturers was recorded with the aid of the KEMAR manikin. A string quartet from the Chicago Symphony Orchestra and a jazz trio were used as sound sources. The insertion response was deduced from the music recordings by subtracting the spectrum of the open-ear recording from the aided recording. Interestingly enough, the hearing aid with the lowest fidelity ratings from both normal-hearing and hearing-impaired subjects had “syllabic compression” with a release time less than 50 ms (audible as a defect to most listeners) and a ragged frequency response. Both subject groups gave an average fidelity rating of less than 30% to that aid. One might argue that the low fidelity ratings resulted because that aid had been factory adjusted for speech, not music. But that aid did just as poorly on speech: It had the lowest intelligibility in noise of all the tested hearing aids.
The recent trend appears to be toward the use of longer and adaptive time constants and reduced compression ratios, but informal listening tests on some modern digital aids suggest that, while some have excellent sound quality and intelligibility in noise, not all of them do. One possible explanation for the latter may lie in the results reported here.
Effect of Multi-channel Compression
The following figures visualize the effect of different release time settings and of different numbers of compression channels on the temporal and spectral structure of speech. For demonstration purposes, the compression ratio was somewhat exaggerated by setting it to 8:1, and no conclusion based on listening tests should be made based on such settings.
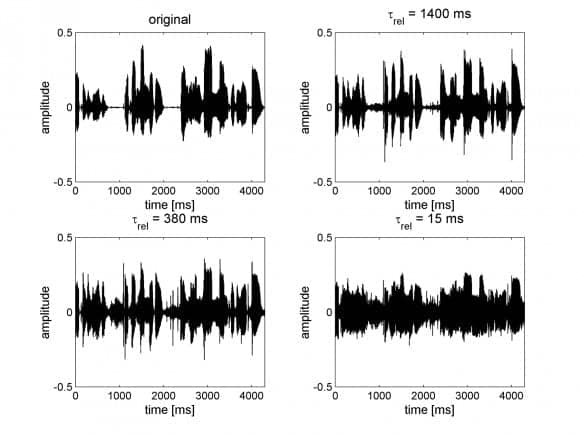
Figure 1. Influence of multi-channel compression release time on the temporal structure of speech for a 16-channel compression system with an exaggerated compression ratio of 8:1. The upper left panel shows the original signal.
Figure 1 shows the influence of the release time on the temporal structure of speech for a section from the fable The North Wind and the Sun (in German: “als sein Wanderer, der in einen warmen Mantel gehüllt war”; in English: “when a traveler…wrapped in a warm cloak.”) A short release time reduces the contrast or difference between the peaks and valleys of the temporal envelope. For the graphs in Figure 1, a speech signal was compressed using release times of 1,400 ms, 380 ms, and 15 ms as defined by ANSI. The attack time was 3 ms in all three panels showing compression. This figure shows that, as the release time is decreased, the temporal contrast is decreased because the soft parts (valleys) of the signal are more amplified than the loud parts (peaks).
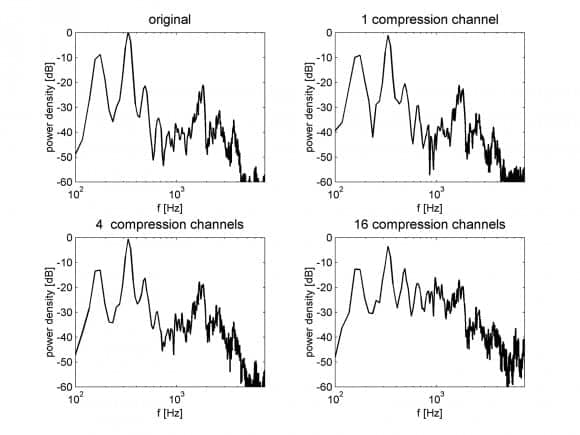
Figure 2. Influence of number of compression channels on the spectrum of a speech segment. The upper left panel shows the original signal.
Interestingly enough, the number of compression channels can also affect the frequency spectrum of speech. Figure 2 shows the spectrum of a speech segment processed through a 1-, 4-, and 16-channel dynamic compression system with a short release time (15 ms) and a compression ratio of 8:1. In this case, as the number of channels increases, the spectral contrasts of speech are reduced, because the valleys in the spectrum receive greater amplification than the spectral peaks.
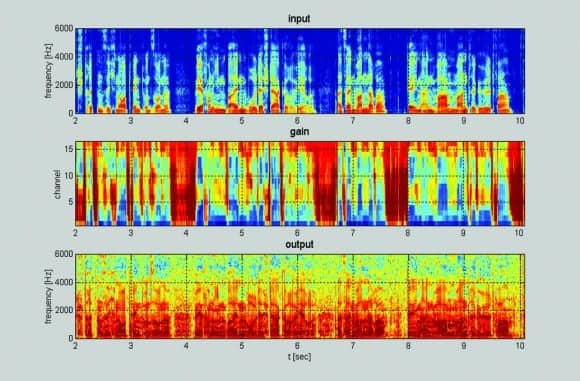
Figure 3. Independent, single knee-point compression in 16 channels with a release time of 15 ms and a compression ratio of 8:1.
Figures 3 and 4 tell the same story somewhat dramatically in spectrogram form, where in each figure the top spectrogram shows the input and the bottom spectrogram shows the output.
The middle spectrogram shows the gain applied to the input. Someone skilled at “reading” spectrograms and familiar with the German language might recognize the sentence “Einst stritten sich Nordwind und Sonne, wer von ihnen beiden wohl der stärkere wäre, als ein Wanderer, der in einen warmen Mantel gehüllt war” (in English: “The north wind and the sun were disputing which was the stronger, when a traveler…wrapped in a warm cloak”).
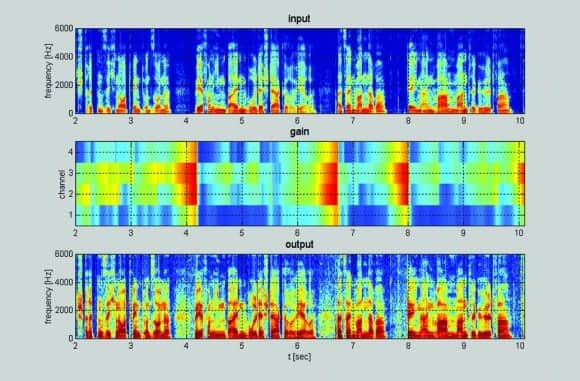
Figure 4. Independent, single knee-point compression in four channels with a release times of 380 ms and a compression ratio of 8:1.
With independent compression in 16 channels and a release time of 15 ms, the output spectrogram at the bottom of Figure 3 is almost unreadable (and difficult to understand when listening) because so much information has been compressed out. With four channels of compression and a release time of 380 ms, the output spectrogram in Figure 4 is easy to read because it retains nearly all the information in the original.
Study Methods
A flexible experimental test system with steep filter characteristics and multi-channel compression was used in the experiments described here (see Figure 5). The input signal was filtered in 16 channels and linearly amplified in each channel according to the hearing loss with the gain settings G1 to G16. In addition, compression resulted in an additional non-linear gain contribution in the 1, 4, or 16 channels. The 4- and 1-channel compression was derived from the levels in the 16-channels. To explain, the 16 channels were summed to the targeted number of channels, and the respective levels in each summed channel were determined, and the corresponding gains were applied in dependence on the input-output function. Three different settings of the compression ratio were used for every group of listeners (normal-hearing and hearing-impaired). The single compression kneepoint was set to 40 dB SPL. The attack time was always set to five periods of the mid-frequency in every channel. The release time was either 15, 380, or 1,400 ms according to ANSI S3.22.
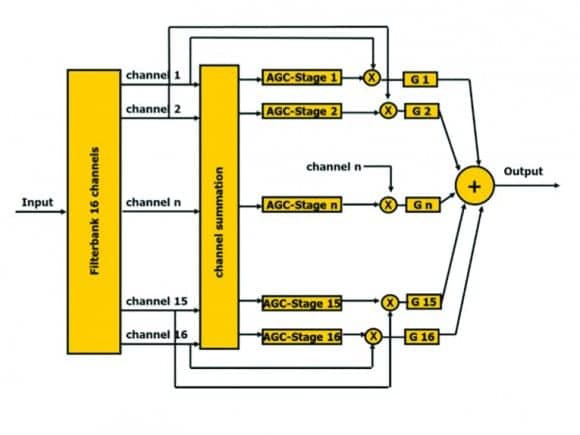
Figure 5. Multi-channel compression system with 16 channels.
Figure 5 shows a block diagram of the experimental test system which was used. The experiment was steered by a control software running on a PC. Signals were routed via a sound card to external boards for digital signal processing, DSP1 and DSP2, which calculated the multi-channel compression algorithm. The output signals were then routed to one ear of a headphone and the listeners gave their response on a touch screen connected to the PC as shown in Figure 6.

Figure 6. Experimental setup.
The task of the listeners was to judge the subjective overall impression of speech in quiet in a paired comparison tournament (ie, they compared two parameter settings of the compression algorithm and selected that setting with better overall impression). A total of 27 different settings of the compression algorithm, 3 numbers of channels, 3 release times, and 3 compression ratios resulted in 351 paired comparisons per listener. The speech samples (story told by a male speaker) were presented at a comfortable level. The average spectrum of speech was preserved independent of the number of compression channels by respective frequency dependent calibration to speech simulating noise. By use of broadband noise, rather than speech, the average spectrum was normalized even though individual vowels of actual speech were sometimes flattened, as described above. Before the paired comparisons, all parameter combinations were adjusted by each listener to equal loudness.
Subjects
The experiments were conducted in the year 2000 at the Hörzentrum Oldenburg, Germany. Five normal-hearing listeners and five listeners with a moderate broadband hearing loss participated.
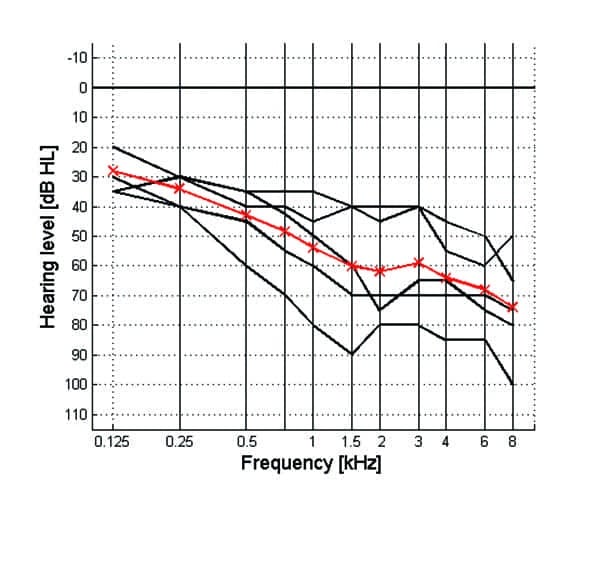
Figure 7. Hearing loss of the five hearing-impaired listeners. The average hearing loss is shown in red.
Figure 7 shows the hearing loss of the hearing-impaired listeners. The compression ratios (CR) for the normal-hearing listeners were 1:1 (linear), 2:1, and 8:1.
The compression ratios for the hearing-impaired listeners were set frequency dependent for each individual listener according to the calculation in the DSL(i/o) fitting algorithm (denoted as “b”). Two additional frequency dependent settings of the compression ratios were used—one above (denoted as “c”) and one below (denoted as “a”) the DSL(i/o) recommendation.
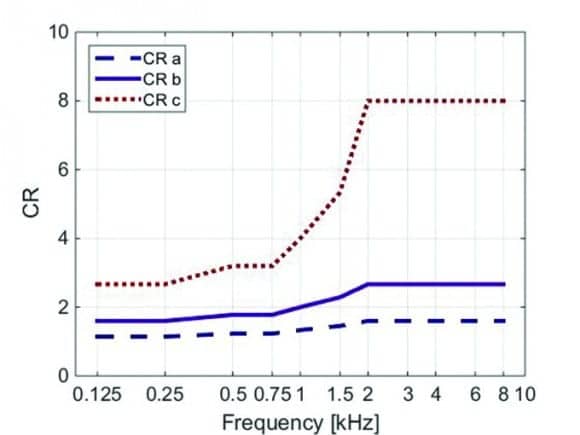
Figure 8. Median CR settings for the hearing-impaired listeners. The solid purple line (b) shows the setting according to the hearing loss calculated with DSL(i/o). The other two lines give a lower and a higher setting.
Figure 8 shows the average settings used.
Results
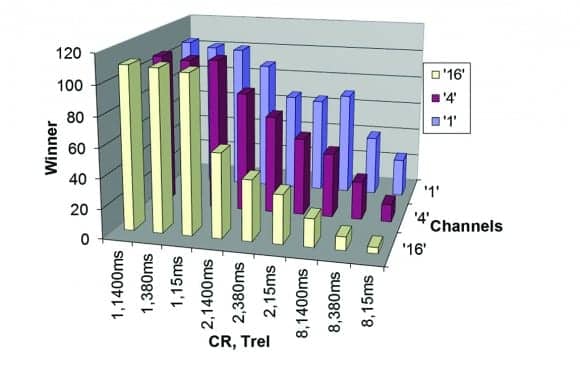
Figure 9. Number of wins for normal-hearing listeners for each of the 27 parameter combinations. The figure shows three rows for the different number of channels (1, 4, or 16) and nine combinations for CR and release time. The first number of the labels on the x-axis gives the CR (1:1, 2:1, or 8:1) and the second number gives the release time (15, 380, or 1,400 ms).
Figure 9 shows the number of wins as a measure for the subjective overall impression for each parameter combination in the paired comparison set with normal-hearing listeners. The subjective preference increases with decreasing number of channels, decreasing CR, and increasing release time. Similar results can be observed for hearing-impaired listeners, as shown in Figure 10.
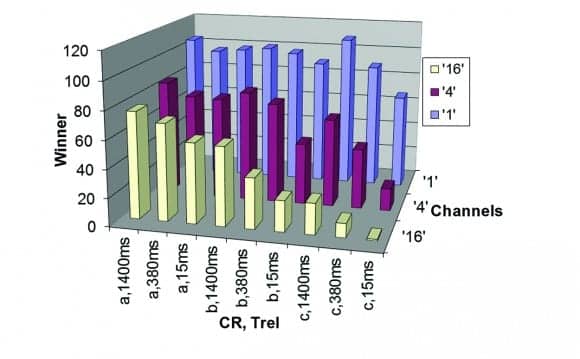
Figure 10. Number of wins for hearing-impaired listeners for each of the 27 parameter combinations. The figure shows three rows for the different number of channels (1, 4, or 16) and nine combinations for CR and release time. The first number of the labels on the x-axis gives the CR (“a” for low, “b” for medium, or “c” for high CR) and the second number gives the release time (15,380 or 1,400 ms).
Discussion
This study, conducted in 2000 using typical technology of the time (and with channels that operated independently of each other), showed a subjective preference for long release times, low compression ratios, and a small number of channels in paired comparison tests for normal-hearing as well as hearing-impaired listeners. It was expected that normal-hearing listeners would prefer as less compression as possible, but it was not clear which parameter (compression ratio, release time, or number of channels) has the most influence on the subjective impression and whether hearing-impaired subjects would prefer that setting which corresponds to their hearing loss respective dynamic range. The results showed that greater compression led to less preference for both normal-hearing and hearing-impaired listeners independent of whether this compression was achieved by a higher number of compression channels, a higher compression ratio, or shorter time constants.
These results are supported by the analysis of the temporal and spectral contrast of speech signals as shown in Figures 1 and 2, and are in line with literature results described briefly at the beginning of this paper. As the temporal and spectral contrasts are reduced by varying the release time and the number of channels, the subjective preference for the corresponding parameter combinations is decreased.
Now, the question remains why one should use compression in hearing aids at all and not linear amplification, which seems to be subjectively preferred. The question of which compression is best also remains. It has to be taken into account that the experiment was conducted using technology representing state-of-the-art in 2000 for five hearing-impaired listeners with a broadband hearing loss only, and only one signal was used to examine the subjective preference for different parameter settings: speech in quiet at a comfortable level. Also in this study, the average speech spectrum in the different conditions was matched and loudness differences were compensated. These actions were adopted to reduce the differences in the compression settings to sound differences not related to frequency shaping and loudness impression.
Thus the results obtained here for speech “pre-compressed” to a comfortable level can not be generalized to everyday life or to modern compression technology. Manifold signals with different levels, spectra, and time structure, as well as certain amounts of noise, are processed by hearing aids. Due to the limited dynamic range of hearing-impaired listeners (which might even be highly dependent on the frequency region, especially for steeply sloping hearing losses), those signals need different amounts of gain for restoration of audibility and loudness while avoiding discomfort. Also, dynamic compression results in less gain for high level noise (eg, car noise in the low frequency region). But since the dynamic range of hearing-impaired listeners is rarely less than 30 dB (the dynamic range of speech), this can be achieved mostly with long release times and a small number of compression channels.
The minimum number of necessary compression channels seems to be given by loudness restoration, audibility for soft sounds, and noise reduction, which does not mean “the more channels the better.” On the other hand, an increased number of channels allows for higher resolution in other processing areas like feedback cancellation, noise reduction, and adaptive directionality.
A disadvantage of long release times is a decrease in detectability of soft sounds that occur soon after loud sounds. This problem can be solved by using short time constants for short loud sounds only: a combination of long and short release times dependent on the level changes in the input signal. Such technology has been around for many years and, indeed, one of the popular single-channel compression systems13 used a level-dependent high-frequency boost coupled with adaptive compression (20 ms recovery from short transients moving to 600 ms recovery for long transients). This avoided “spectral flattening” and excessive compression while maintaining audibility for soft sounds.
For many years after the first introduction of digital hearing aids, both fidelity listening tests and intelligibility-in-noise tests suggested superior sound quality using Killion’s analog configuration. By the time of the listening test and speech-in-noise study reported by Killion in 2004,12 multi-channel digital hearing aids with excellent sound quality and intelligibility in noise had been introduced. These improvements have continued during the last decade.
Although the effect of compression on speech quality shown in this contribution is 15 years old, its general finding—namely, that short release times in combination with a high number of compression channels reduce subjective quality—is still valid and was recently confirmed for music in 2014.11 Nevertheless, the findings in this analysis are limited to classical compression algorithms with “simple” attack and release time mechanisms.
Conclusions
- This analysis showed that short time constants and a large number of independent compression channels using a state-of-the-art technology circa 2000 reduce the temporal and spectral contrast of speech, and
- In subjective paired comparisons, long time constants, low compression ratios, and a small number of compression channels were preferred in the investigated technology configuration by normal-hearing and hearing-impaired listeners.
Acknowledgements
This study was conducted during the employment of Inga Holube and Volkmar Hamacher at Siemens Audiological Engineering Group in Erlangen, Germany. The authors thank Sivantos GmbH and Hörzentrum Oldenburg, Germany, for their permission to publish the study, and several (former) colleagues for their support and data collection.
References
-
Holube I, Wesselkamp M, Hamacher V, Gabriel B. Multi-channel dynamic compression: Concepts and results. Paper presented at the International Hearing Aid Research Conference (IHCON) Tahoe City, Calif, August 13-17, 2000.
-
Holube I. Multi-channel dynamic compression: Concepts and results. Paper presented at the 45th International Congress of Hearing Aid Acousticians (EUHA), Germany.
-
Villchur E. Signal processing to improve speech intelligibility in perceptive deafness. J Acoust Soc Am. 1973;53(6):1646-1657.
-
Lippmann RP, Braida LD, Durlach NI. Study of multichannel amplitude compression and linear amplification for persons with sensorineural hearing loss. J Acoust Soc Am. 1981;69(2):524-534.
-
Neuman AC, Bakke MH, Mackersie C, Hellman S, Levitt H. The effect of compression ratio and release time on the categorical rating of sound quality. J Acoust Soc Am. 1998;103(5):2273-2281.
-
Moore BCJ, Peters RW, Stone MA. Benefits of linear amplification and multichannel compression for speech comprehension in backgrounds with spectral and temporal dips. J Acoust Soc Am. 1999;105(1):400-411.
-
Van Buuren RA, Festen JM, Houtgast T. Compression and expansion of the temporal envelope: Evaluation of speech intelligibility and sound quality. J Acoust Soc Am. 1999;105(5):2903-2913.
-
Boike KT, Souza PE. Effect of compression ratio on speech recognition and speech-quality ratings with wide dynamic range compression amplification. J Sp Lang Hear Res. 2000;43(2):456-468.
-
Hansen M. Effects of multi-channel compression time constants on subjectively perceived sound quality and speech intelligibility. Ear Hear. 2002;23(4):369-380.
-
Moore BCJ, Füllgrabe C, Stone MA. Determination of preferred parameters for multichannel compression using individually fitted simulated hearing aids and paired comparisons. Ear Hear. 2011;32(5):556-568.
-
Croghan NBH, Arehart KH, Kates JM. Music preferences with hearing aids: effects of signal properties, compression settings, and listener characteristics. Ear Hear. 2014;35(5):e170-e184.
-
Killion M. Myths that discourage improvements in hearing aid design. Hearing Review. 2004;11(1):32-40, 70.
-
Killion MC. High Fidelity and Hearing aids. Audio. 1991;75(1):42-44.

Inga Holube, PhD
Inga Holube, PhD, is a professor at the Institute of Hearing Technology and Audiology at the Jade University of Applied Sciences in Oldenburg, Germany.

Volkmar Hamacher, PhD
Volkmar Hamacher, PhD, is director of research at Advanced Bionics GmbH, in Hanover, Germany.

Mead Killion, PhD
Mead C. Killion, PhD, is an audiologist, engineer, and president of Etymotic Research Inc, Elk Grove Village, Ill.
Correspondence can be addressed to HR or Dr Holube at: [email protected]
Original citation for this article: Holube I, Hamacher V, Killion MC. Multi-channel Compression: Concepts and (Early but Timeless) Results. Hearing Review. 2016;23(2):20.?


