A new study compares two approaches to speech-in-noise in hearing aids: Multi-Stream Architecture and Deep Neural Network technology.
By Petri Korhonen, MSc; Francis Kuk, PhD; Christopher Slugocki, PhD; Heidi Peeters, MA
While artificial intelligence (AI) as implemented through deep neural networks (DNN) has the potential to further improve signal processing in hearing aids, the ability of current generation DNNs to match the performance of state-of-the-art directional microphone systems remains unknown. In this article, we compare the speech-in-noise performance of Signia’s Multi-Stream Architecture (MSA) against DNN technology in a recently introduced hearing aid.
Introduction
Communication in noisy environments remains one of the greatest challenges facing listeners with a hearing loss. This is especially true in group conversation situations where there may be multiple moving talkers in complex background noises to which the listeners must track and attend. Hearing aid manufacturers have developed advanced technologies to improve performance in such acoustically complex communication situations. Traditionally, the development of these technologies has been guided by principles rooted in an ever-growing knowledge of the acoustics and psychoacoustics that affect speech communication. These technologies analyze the acoustic scene and adapt their processing to facilitate improved communication based on the unique listening challenges posed by the environment. One such technology based on “human intelligence” is the RealTime Conversation Enhancement (RTCE) processing, which was implemented on the multi-stream architecture (MSA) made available by the Signia Integrated Xperience (IX) hearing aid platform.1
How Multi-Stream Architecture Works for Hearing Aids
Multi-stream architecture starts with Augmented Focus (AF) technology, which splits incoming sounds into two different streams (front versus sides/back). Each stream is then processed using separate paths with independent compression and noise reduction algorithms. This approach is unique in hearing aid signal processing, where all existing technologies process sounds from the front and back/sides using the same processing path. With AF, important speech sounds from one direction may be processed with more linear gain and less noise reduction to preserve critical sound features (e.g., temporal envelope), while competing sounds from the opposite direction may be attenuated more to minimize masking effects.
AF technology has been demonstrated to improve signal-to-noise ratios (SNRs) by 4 dB2, reduce speech reception thresholds by 3.9 dB3, and increase noise acceptance by 3 dB over single-stream directional processing.4 AF has also been demonstrated to have positive effects on how the brain processes speech in background noise, including enhancing contrasts between speech sounds in the wearer’s soundscapes as quantified via the mismatch negativity (MMN) and reducing neural signatures of listening effort as quantified by alpha power in the electroencephalogram (EEG). 5,6
Signia has recently built upon AF technology by introducing the RTCE technology that provides focused enhancement for multiple sound sources originating from different locations in front of the listener. RTCE first analyzes the acoustic scene to evaluate the nature of the dominant sounds in front of the listener. If the dominant sounds are directional and near the listener, the analysis will decide that there is likely active conversation directed at the wearer. RTCE then estimates the number of target sound sources (i.e., communication partners) and their specific spatial locations (i.e., azimuths) relative to the listener. Afterwards, RTCE deploys several narrow directional beams towards the direction of the talker(s). On the other hand, if the acoustic scene analyzer determines that sounds are part of a diffuse background (e.g., babble-noise in restaurants and cafes) and/or are further away, then such sounds are not considered part of the conversation, and no focus beams will be directed towards those sounds.
The goal of RTCE is to make engagement in group conversations easier and more comfortable for wearers by capturing and improving the SNR of each conversation partner, even when the conversation partners move around and change locations. RTCE technology has been demonstrated to provide improved speech understanding, reduced listening effort, and increased noise tolerance,7 along with high levels of listening satisfaction and preference in real-world conversations.8 Neurophysiological correlates of these behavioral benefits have also been reported through enhanced MMN responses and reduced EEG alpha power when listening to speech-in-noise.9,10
Deep Neural Network Approach
In contrast to the “human intelligence” approach to algorithm design, some hearing aid manufacturers have recently attempted to approach the speech-in-noise problem using machine learning (ML), a subfield of artificial intelligence (AI). ML uses generic algorithms, which learn how to solve a problem by observing example data. These algorithms are not explicitly told how to solve a problem. Instead, the algorithms are free to solve problems however they deem optimal. There is no requirement for the solution to mimic conventional approaches or to be easily explainable to humans.11 To date, ML approaches to solving the speech-in-noise problem in hearing aids rely on deep neural networks (DNNs).12 The networks are optimized during the algorithm’s development by presenting it with a variety of speech-in-noise scenarios. It is hoped that the DNN will provide speech-in-noise benefits that generalize to real-world listening environments, including those that were not included in the training scenarios.
The DNN-based noise reduction technologies offered by various manufacturers differ substantially in their complexity and sophistication. The network structure and the intricacies involved in the training of the network, such as the data used for the training, must all be decided during hearing aid development. Also, developers need to consider the balance between complexity of processing and battery consumption. Thus, DNN solutions can differ substantially among implementations. It is unclear if the result of any DNN optimization would exceed that of a “human intelligence” based non-DNN device. Thus, the efficacy of DNNs should be carefully evaluated with realistic listening situations.
In this study we compare the speech-in-noise performance of two hearing aids: one that features the multi-stream architecture-based RTCE technology and another that features a DNN-based noise reduction technology. The two hearing aids are compared in a simulated group conversation setting with three talkers taking turns speaking from different azimuths (0°, 30°, and 330°) across a range of SNRs in an acoustically complex environment. The null hypothesis is that there is no performance difference between the RTCE and DNN algorithms across the outcome measures used in the evaluation.
Methods
Participants
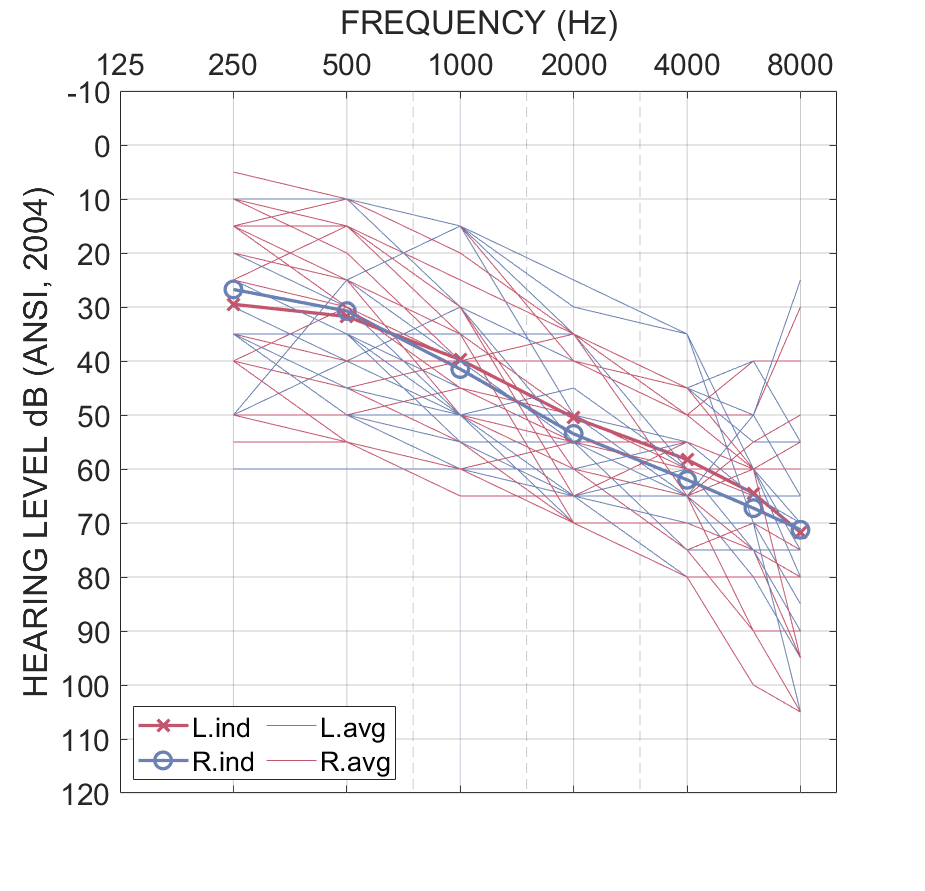
An a priori power analysis suggested 15 participants would be sufficient to power the study at a 0.8 level. In total, 20 older adults (mean age = 74.5 years, range 64-90 years, 7 females) with a bilaterally symmetrical mild-to-severe sensorineural hearing loss (Figure 1) participated. All participants were native speakers of American English. Thirteen of the 20 listeners had more than 1 year of experience with receiver-in-the-canal (RIC) style hearing aids. All participants passed cognitive screening on the Montral Cognitive Assessment (MoCA, average = 27.9). The protocol was approved by an external institutional review board (Salus; IRB: RP2402) and informed consent was obtained from all participants.
Hearing aids
Listeners were tested using bilaterally fit Signia Pure Charge & Go 7IX hearing aids (HAs), which use RealTime Conversation Enhancement (RTCE) technology. The performance of the RTCE device was compared against a recently introduced premium product from another manufacturer, which implements a DNN-based noise reduction technology. The study followed a single-blind design, where participants did not know the identity of each hearing aid. The HAs were coupled using fully occluding ear tips and programmed based on the participants’ audiometric thresholds using NAL-NL2 fitting targets implemented on each manufacturer’s fitting software. All hearing aids were set to “speech in loud noise” programs to ensure that the RTCE and DNN features were activated.
Setup
Hearing aid fitting and testing took place inside a double-walled sound-treated booth with internal dimensions of 3 x 3 x 2 meters (width x length x height). Listeners were seated in the center of the booth surrounded by eight loudspeakers. Six loudspeakers were placed at 0°, 30°, 120°, 180°, 240°, and 330° in the azimuth at a 1-meter distance from the listener (Figure 2). In addition, two loudspeakers were placed at 45° and 315° in the azimuth at a 1.5-meter distance from the listener and pointing towards the corners of the booth to create a diffuse field. All loudspeakers were at ear level.
Speech-in-noise testing was conducted using high context sentences from the Repeat and Recall Test (RRT).13 These sentences are syntactically valid and semantically meaningful (e.g., “Keep the ice cream in the freezer”), thus reflective of meaningful conversation during real-life listening. Target sentences alternated randomly between the three locations (0°, 30°, and 330°) simulating conversation between three conversation partners taking turns. All sentences were spoken by the same male talker. The level of the speech was adjusted based on listener performance using a Bayesian-guided algorithm. It is not uncommon in real-life for the competing sounds to include static background noises as well as fluctuating noises and other non-target talkers. To mimic such a realistic conversation-in-noise situation, an ongoing cafeteria noise was presented from 120°, 180°, and 240° and at -6 dB softer from 45° and 315°. Two speech-like distractor signals (i.e., International Speech Test Signal, ISTS) 14, simulating talkers outside of the conversation, were presented from 120° and 240° at +6 dB louder than the cafeteria noise (Figure 2). The total combined background noise level was 72 dB SPL.

Procedure
Speech-in-noise performance was measured in two phases. Phase 1 used the RRT sentences to estimate the listeners’ performance intensity (P-I) function by varying the speech level adaptively according to a Bayesian-guided algorithm.15Each trial included 32 sentences with 3 or 4 target words scored per sentence. From the P-I functions, we derived the SNRs required for 25%, 50%, 75%, and 90% correct word-level speech reception thresholds (i.e., SRT-25, SRT-50, SRT-75, and SRT-90). This effectively allowed us to estimate the SNRs required for different levels of conversation success. The two study hearing aids (RTCE and DNN) were tested in a counterbalanced order.
Phase 2 measured each listener’s speech-in-noise performance at the SNR corresponding to the SRT-50 measured in Phase 1 for the worse performing technology. Word and sentence recognition performance (% repeated correctly) was assessed using 32 sentences. Communication challenges can also extend to other dimensions not captured by speech recognition measures alone. For example, even when listeners report that speech is loud enough and can be understood, listening can still feel effortful, tiring, and stressful.16 Such negative experiences may lead listeners to quit participating in activities involving challenging listening. Thus, after each trial, participants were asked to rate how effortful they found the listening situation on a scale from 1 to 10 (1 = “minimal effort”, 5 = “moderate effort”, and 10 = “very effortful listening”). Listeners were also asked to estimate how long (in minutes) they would be willing to spend listening in that noise condition (tolerable time).
Results
Speech recognition performance
Speech Reception Thresholds across performance criteria
Figure 3 (left) compares aided SRTs between RTCE and DNN technologies at different performance criteria (SRT-25, SRT-50, SRT-75 and SRT-90) as extrapolated from the P-I functions measured during Phase 1 of the experiment. For 19 of the 20 listeners, the SNRs required for 50%, 75%, 90% performance were lower with RTCE than with DNN (18 of the 20 for 25% performance). Figure 3 (right) summarizes the average RTCE benefit over DNN at each SRT performance criterion. Here, we can see that listeners performed better with RTCE than with DNN at all performance criteria levels (RTCE vs DNN; SRT-25: -10.5 vs -9.2 dB; SRT-50: = -7.5 vs. -5.7 dB; SRT-75: -4.4 vs. -2.1 dB; SRT-90: -1.6 vs. 1.2 dB) (all p < 0.001). The improvement with RTCE over DNN increased from 1.3 dB at SRT-25 to 2.8 dB at SRT-90. In other words, the performance differential was smaller at SNRs where performance was relatively poor (i.e., 25% understanding) and increased at SNRs where performance was relatively good (i.e., 90% speech understanding).

Speech in noise performance at SRT-50
Figure 4 plots sentence- and word-level performance scores measured for the RTCE and DNN technologies measured at fixed SNRs corresponding to each listener’s aided SRT-50 in the poorer HA condition. Most participants (16 out of 20) performed better with RTCE than with DNN technology (Figure 3, left and center). On average, performance was 14.1% better for words (t(19) = -4.41, p < 0.001) and 17.4% better for sentences (t(19) = -5.00, p < 0.001) with the RTCE than with the DNN (words: 68.3% vs 54.2%; sentences: 45.8% vs 28.4%)(Figure 3, right). This suggests that listeners can follow multi-talker conversations in the same acoustically complex and difficult listening environments more accurately with the RTCE than with the DNN technology.

Impact of technology on listening effort ratings and willingness to stay in noisy background
Figure 5 plots listening effort ratings and tolerable time as reported by the listeners in the two HA conditions. Twelve out of 20 listeners rated listening less effortful with RTCE than with DNN. The average effort rating was 6.8 with the RTCE and 7.8 with DNN, but the difference was not statistically significant (t(19) = 1.86, p = 0.078). Fifteen out of 20 listeners reported an increased willingness to stay in noise (i.e., tolerable time) when tested with RTCE (mean = 16.1 min) than with DNN (mean = 8.7 min). This difference was statistically significant (t(19) = -3.63, p < 0.01), which suggests that listeners were willing to engage in the group conversation in noise for longer durations in the RTCE condition than in the DNN condition.

Discussion: RTCE vs. DNN
This study suggests that the RTCE technology available in Signia IX results in superior conversation-in-noise performance over a premium hearing aid that uses DNN-based technology. Specifically, the RTCE device yielded an average SNR improvement of between 1.3 and 2.8 dB over the DNN based feature, or 14% improvement in word and 17% improvement in sentence understanding at a SRT criterion of 50%. A majority (12 out of 20) of participants also rated listening less effortful with RTCE than with DNN. RTCE increased the duration of time listeners were willing to stay in noise by 7 minutes compared to the DNN technology (or an 85% increase in relative duration).
Reduced listening effort ratings reported by a majority of participants suggest that listeners did not need to use as much top-down processing, such as use of contextual cues to repair missed or misheard words, to help speech understanding in the RTCE condition compared to the DNN condition. Less effortful speech understanding could increase a listener’s willingness to remain engaged in communication and promote greater participation in social activities.16 This speculation is supported by the significant increase in reported tolerable time for RTCE compared to DNN conditions.
Further Reading
Interestingly, the benefit of the RTCE over the DNN was not uniform across listening conditions, but instead increased from 1.3 dB at an SRT criterion of 25% understanding to 2.8 dB at an SRT criterion of 90% understanding. This result highlights the benefits of using the Bayesian-guided RRT speech-in-noise test that is able to estimate a listener’s full P-I function. By estimating the full P-I function, we were able to confirm that the advantage of the RTCE over DNN-based noise reduction is observed over a range of SNRs for each listener. Moreover, we were able to observe that the magnitude of RTCE benefit over DNN increases as listening conditions improve and speech understanding becomes more conducive to supporting real-world conversation.
In other words, according to the study results, the benefits of RTCE over DNN are not limited to very challenging SNRs where listener understanding is below the level (e.g., <50%) needed to feel motivated to continue with conversation. Instead, the greatest benefit was observed at SNRs where speech understanding was >75%. Such moderately challenging communication situations represent conversations people are more likely to encounter and spend time in the real world.
As noted earlier in the introduction, the advantage of RTCE is that it is designed with the developers’ specific knowledge of how the algorithm should work in daily situations. The developers have full control of the processing. Such is not the case for current generation DNN technology. When considering the efficacy of a hearing aid, the diligent HCP must consider how the hearing aid (or algorithm) is designed and implemented, and not merely the technology platform on which the algorithm is based.
Petri Korhonen, MSc, is a senior research scientist; Francis Kuk, PhD, is the director; Christopher Slugocki, PhD, is a research scientist; and Heidi Peeters, MA, is a research audiologist at the WS Audiology Office of Research in Clinical Amplification (ORCA) in Lisle, Ill.
References
1. Jensen N, Samra B, Parsi HK, Bilert S, Taylor B. Multi-stream architecture for improved conversation performance. Hearing Review. 2023;30(10):20-23.
2. Korhonen P, Slugocki C, Taylor B. Study reveals Signia split processing significantly improves the signal-to-noise ratio. AudiologyOnline. 2022;Article 28224. Available at: https://www.audiologyonline.com/articles/study-reveals-signia-split-28224
3. Jensen N, Hoydal E, Branda E, Weber J. Augmenting speech recognition with a new split processing paradigm. Hearing Review. 2021;28(6):24-27.
4. Kuk F, Slugocki C, Davis-Ruperto N, Korhonen P. Measuring the effect of adaptive directionality and split processing on noise acceptance at multiple input levels. Int J Audiol. 2023;62(1):21-29. doi:10.1080/14992027.2021.20227899
5. Slugocki C, Kuk F, Korhonen P, Ruperto N. Using the mismatch negativity (MMN) to evaluate split processing in hearing aids. Hearing Review. 2021;28(10):20-23.
6. Slugocki C. Split-processing in hearing aids reduces neural signatures of speech-in-noise listening effort. Hearing Review. 2022;29(4):20,22-23.
7. Korhonen P and Slugocki C. Augmenting split processing with a multi-stream architecture algorithm. Hearing Review. 2024;31(5):20-25.
8. Folkeard P, Jensen NS, Parsi HK, Bilert S, Scollie S. Hearing at the mall: multibeam processing technology improves hearing group conversations in a real-world food court environment. Am J Audiol. 2024;33(3):782-792. doi:10.1044/2024_AJA-24-00027
9. Slugocki C, Kuk F, Korhonen P. (in press). Using the mismatch negativity to evaluate hearing aid directional enhancement based on multi-stream architecture. Ear Hear.
10. Slugocki C, Kuk F, Korhonen P. Using alpha-band power to evaluate hearing aid directionality based on multistream architecture. Am J Audiol. 2024;33(4):1164-1175. doi:10.1044/2024_AJA-24-00117
11. Bishop MC. Pattern Recognition and Machine Learning. New York, NY: Springer; 2006.
12. Andersen AH, Santurette S, Pedersen MS, et al. Creating clarity in noisy environments by using deep learning in hearing aids. Semin Hear. 2021;42(3):260-281. doi:10.1055/s-0041-1735134
13. Slugocki C, Kuk F, Korhonen P. Development and clinical applications of the ORCA Repeat and Recall Test (RRT). Hearing Review. 2018;25(12):22-27.
14. Holube I, Fredelake S, Vlaming M, Kollmeier B. Development and analysis of an International Speech Test Signal (ISTS). Int J Audiol. 2010;49(12):891-903. doi:10.3109/14992027.2010.506889
15. Watson AB. QUEST+: A general multidimensional Bayesian adaptive psychometric method. J Vis. 2017;17(3):10. doi:10.1167/17.3.10
16. Pichora-Fuller MK, Kramer SE, Eckert MA, et al. Hearing impairment and cognitive energy: the framework for understanding effortful listening (FUEL). Ear Hear. 2016;37 Suppl 1:5S-27S. doi:10.1097/AUD.0000000000000312