Tech Topic | June 2018 Hearing Review
SoundSense Learn is a feature that uses machine learning to apply user input for easy and efficient optimization of hearing aid parameters. This article describes a test in a double-blind paradigm with recordings made of individual SoundSense Learn parameter settings. Significant increases in sound quality and comfort were found when compared to both the Not Active and Active Classifier conditions. The feature consistently improved sound quality and listening comfort across all test samples.
As outlined in a recent article1 published in the April 2018 Hearing Review, occasional problems still occur in which modern automatic hearing aids occasionally fail to meet their users’ auditory intention—that is, the devices do not make audible the voice(s) or sound(s) the user most wishes to hear and/or pose comfort issues. The article looked at a brief history of personalization via systematic adjustment, and suggested that systems driven by machine learning could be one possible solution.
In the present article, we will introduce SoundSense Learn, a novel machine learning approach to the problem of real-life hearing aid (HA) personalization which was recently introduced as part of the Widex EVOKE hearing aid platform. We will further outline how auditory intention poses a continuous challenge to the user and hearing care professional (HCP) and demonstrate how SoundSense Learn can help users achieve increased sound quality or comfort depending on their auditory intention.
Auditory Intention
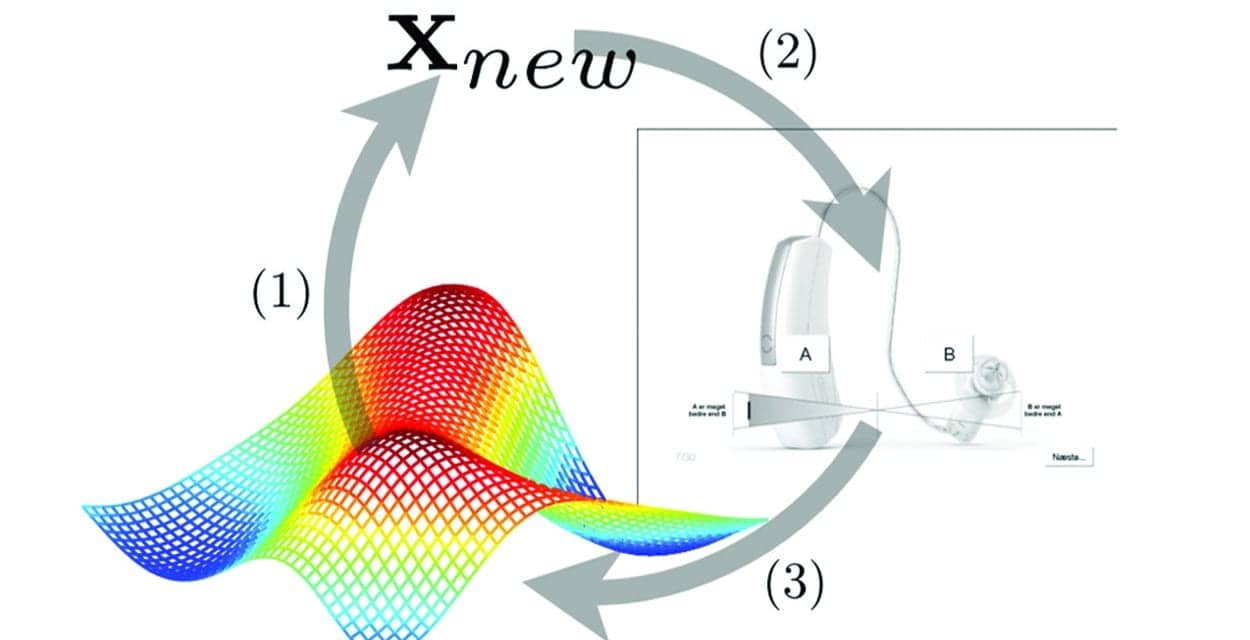
The individual’s intention of what they wish to achieve relative to an auditory-related task is what we call auditory intention. In every listening situation, a user will have an auditory intention. We have previously discussed how automation in hearing aids is an effective way to address the needs of hearing aid users in most situations.1 But any automatic system and/or environmental adaptation is built on assumptions about what to amplify and what not to amplify, and even the best available automatic system faces one major challenge: Knowing exactly what is important, in any given auditory scenario, for each specific user (Figure 1).
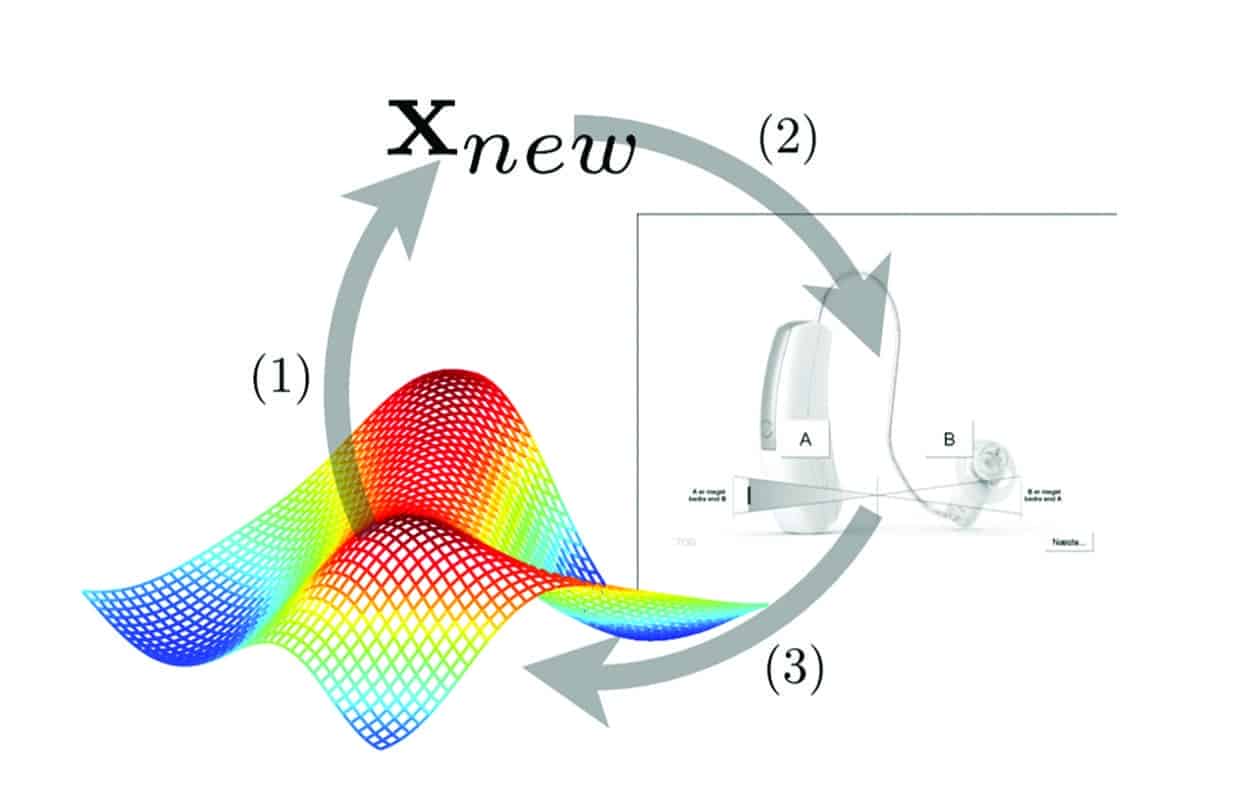
Figure 1. Any user will at any given time have an auditory intention and a related ideal setting of the hearing aid. Here, that ideal setting is exemplified with the colored space. In a perfect hearing aid personalization, the hearing aid will adjust for the auditory intention of the user (1) to drive new settings in the hearing aid (2) until the auditory scenario gives need for another new ideal setting matched to the auditory intention of the user (3). Adapted with permission from Nielsen et al.2
Although automatic adaptive systems have advantages, such as freeing cognitive resources to aid listening,3 they rely on assumptions regarding what is important in any given auditory scenario for each specific user. The reality, though, is that users’ intentions may vary in any given auditory scenario. In a social situation, a user might prefer to increase the conversation level and lower background music—or they might prefer something completely different.
When an automatic system does not meet a given auditory intention, a user is faced with three options: 1) Fine-tuning via the clinician; 2) Adjusting hearing aid controls, or 3) Just putting up with the problem. Returning to the HCP for adjustment for a real-life problem sometimes has challenges to overcome: time delay, no longer being in the situation where the problem arose, and the difficulty for users to remember and describe their problem. All can lead to the fine-tuning appointment becoming frustrating for both the user and HCP.
At the moment when the problem occurs, the user may have the option to make changes via a control. Hearing aid controls have evolved as hearing aids have become more powerful. With the advent of the 2.4 GHz connection between hearing aids and smartphones, the possibility of advanced control has been explored by HA manufacturers.4 It is apparent that, while these controls offer benefits, for many users they are complex and the time necessary to optimize the hearing devices via these complex controls is often enough to dissuade users from trying.
The 2.4 GHz connection has also allowed the other possibility of employing the processing power of the smartphone for hearing aid optimization, running powerful machine learning applications that can analyze user inputs and quickly optimize hearing aid settings in real-life listening situations. This has the potential to quickly and effectively address problems in situations where it is impossible for the HCP to be there.
Efficiently Giving the User Control
One major advantage of employing a machine learning system in hearing aid setting optimization is the speed of the system in narrowing down and identifying an ideal set of hearing aid parameters. The paired comparison methodology, also known as A/B testing, is a widely applied approach for sampling user experience. It is a very approachable method for the user, and needs little to no supervision when applied. As described in Townend et al,1 one of the main problems of comparing parameter settings is that the number of comparisons needed to discover an “optimum setting” increases beyond what can practically be handled—especially for quickly allowing a user to set a HA according to a given auditory intention.
SoundSense Learn is an implementation of a well-researched machine learning approach for individual adjustment of HA parameters.5 SoundSense Learn is designed to individualize HA parameters in a qualified manner, sampling enough possible settings to adjust the HA according to the users’ preference for his/her auditory intention with a high degree of certainty. From a practical perspective, this means the user is given control of a selected set of parameters using an application (app) that minimizes the number of interactions needed to reach an optimal setting (Figure 2).
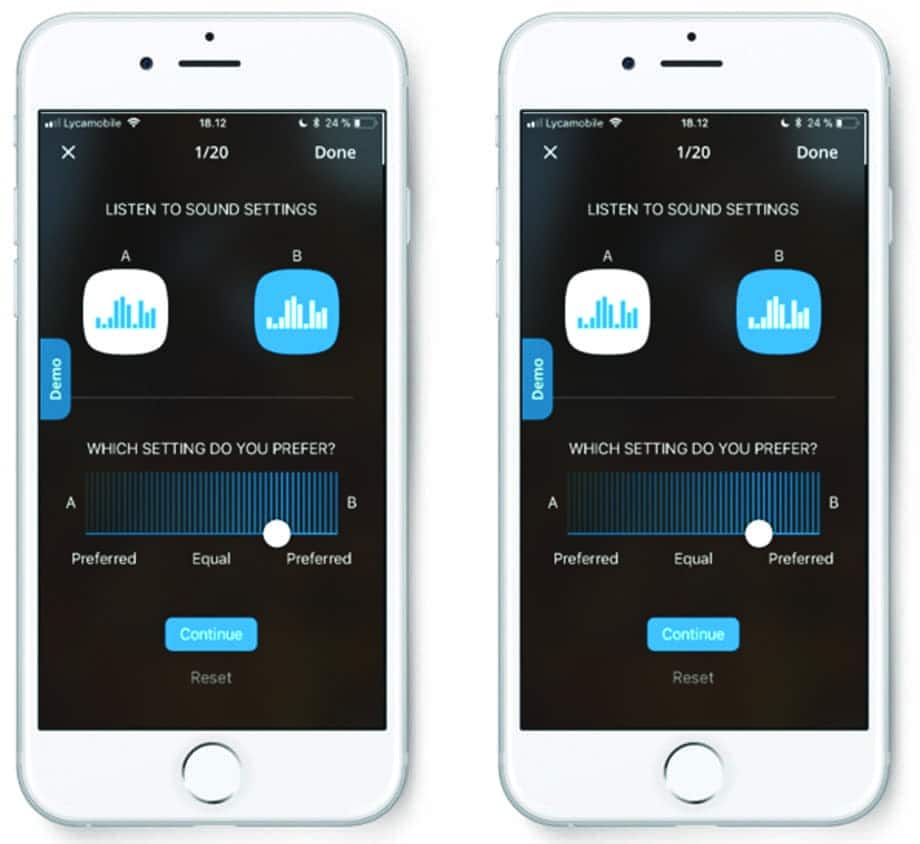
Figure 2. Example user interface for machine learning input based on paired comparison as seen in SoundSense Learn. The user compares two parameter settings and selects the one which is the most preferred for his/her auditory intention. The SoundSense Learn feature then calculates the most likely ideal setting for the next comparison, step by step, getting closer to an ideal setting for the user’s auditory intention. Only 20 iterations are needed to reach an optimal setting.
Testing SoundSense Learn
To test the benefits of using SoundSense Learn as a means for giving the user control over basic HA parameter settings in an efficient manner, we designed an experiment thoroughly testing the feature in a selection of sound scenarios. The main goal of this experiment was to observe any improvement experienced by the user when using SoundSense Learn compared to the same HA with “No Active Classifier” or a HA with an “Active Classifier.” The classifier in question is Widex’s automatic environment detection system with associated optimization of hearing aid parameters.3
Because of the complex nature of dealing with real-time individual optimization in a double-blind paradigm, it was necessary to divide the test into three separate parts:
1) Individual HA parameter settings using SoundSense Learn were generated at the first visit. HAs were fitted to test participant’s individual hearing losses. After this, the test participants listened to nine simulated auditory environments (Table 1) through a head and torso simulator while using the SoundSense Learn application to manipulate HA parameter settings. The test participants were given a visual context (picture) and instructions relating to the objectives for using SoundSense Learn in each of the simulated environments (Figure 3).
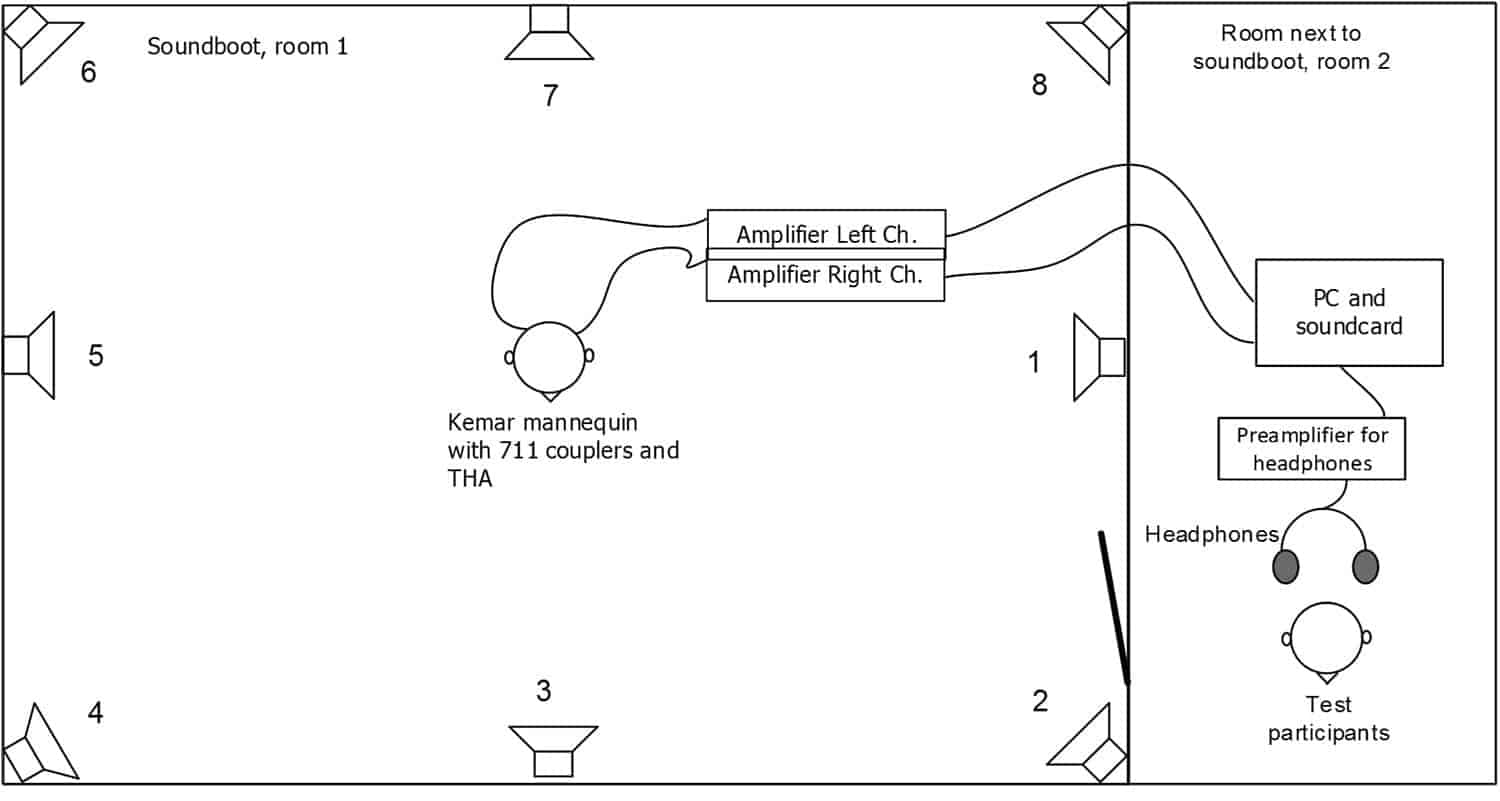
Figure 3. Graphic overview of the real-time listening with SoundSense Learn adjustment using a KEMAR HATS in a simulated auditory environment. This setup allows for the participant to listen to the devices in real time and interact with the devices using SoundSense Learn. The participants were given visual context and written instructions to guide their auditory intention.
2) Recordings of individual HA settings could be made after all settings were performed by the test participants. The experimenter recorded the HAs in all of the simulated auditory environments. Three settings were recorded for each environment: HA with No Classifier, HA with an Active Classifier, and HA with SoundSense Learn. These three settings were applied as the variables in the test.
3) After a minimum of 3 days, the test participants returned and provided ratings of the individual recordings in a double-blind setup.
A total of 19 test participants with mild-to-moderate hearing loss completed the test (average age of 68 years; 32% female). Data was collected using the Continuous Quality Scale known from the ITU-R BS.1534-3 recommendation6 on the dependent variables of sound quality, listening comfort, and speech intelligibility. No reference sample or anchor systems were applied, as the individual settings of the devices didn’t allow for a relevant reference/anchor selection. The tool used for data collection allowed for direct crossfade between the presented samples, which also allowed for a critical comparison.7
Users Are Different
As previously mentioned, one of the main intentions with SoundSense Learn is to allow each individual user to adjust the HA according to his/her auditory intention in a given sound environment. This assumes, to some extent, that users will have different preferences for settings even though the auditory environment and intention are similar. To examine this, we looked at the parameter settings after using SoundSense Learn when presented with a similar acoustic environment and instructions for intention.
As seen in Figure 4, the test participants ended with different parameter adjustments for similar auditory environments and intentions. This confirms that there are variations in what parameter settings users prefer. Having confirmed that the test participants ended with variations in the parameter settings, it is of interest to examine what benefits the test participants achieved using SoundSense Learn. In the following section, we will focus on the improvements that SoundSense Learn showed on sound quality and listening comfort. No results from speech intelligibility will be shown, as no improvements were observed for the tested samples.
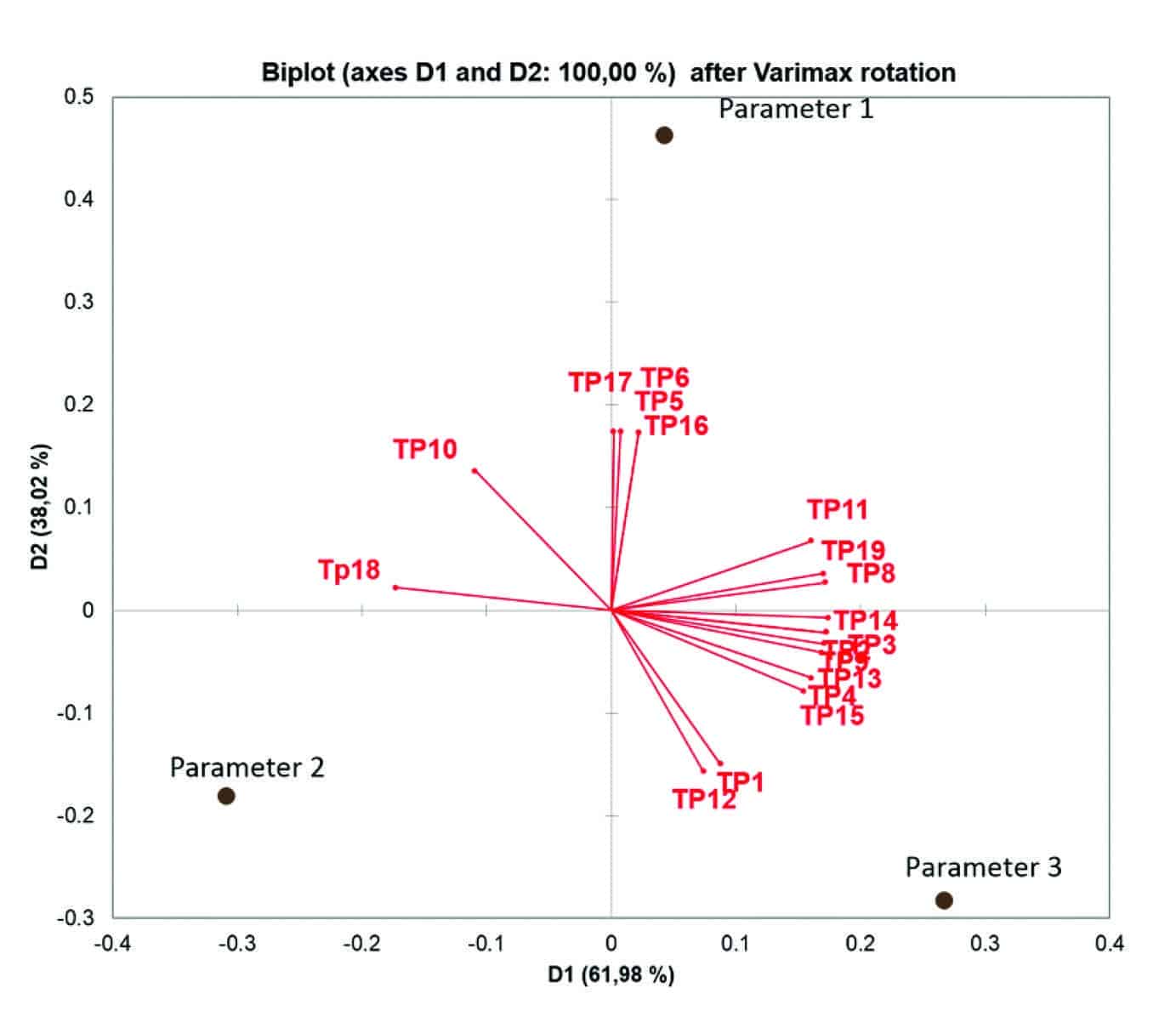
Figure 4. Internal preference mapping using each user’s parameter setting for the noisy canteen/cafeteria sample with the intention to achieve more listening comfort. Each red vector represents a user with the proximity to the black parameter settings representing the achieved settings using SoundSense Learn. The graph shows that the users ended up with different ideal settings, but with clusters representing users with similar behavior. Generally test participants avoided high settings of Parameter 2. This confirms that the test participants showed varying preferences when applying SoundSense Learn to the same sound scenario. Users are indeed different.
Listening Comfort
One of the auditory intentions included in the study was listening comfort. Listening comfort was defined as how comfortable you are overall in the sound scenario (or, alternatively, how annoyed you are with the noise level). The test participants could use the SoundSense Learn app to apply whatever HA parameter settings they found preferable for increasing their listening comfort in the sound scenarios listed in Table 1.
Overall it was found that, using SoundSense Learn, the test participants experienced a significant increase in listening comfort (p<0.01) over the Active Classifier setting. The pattern of increased listening comfort was consistent across the tested sound scenarios (Figure 5). Overall 84% of the test participants preferred the HA parameter settings they achieved using SoundSense Learn (Figure 6).

Figure 5. Mean scores of ratings of perceived listening comfort on the Continuous Quality Scale for each subject’s individual setting (with 95% confidence intervals). Significant improvements were shown for SoundSense Learn over both Active Classifier and Classifier Not Active (p<0.01). In addition we can see a stable performance of SoundSense Learn across the three sound scenarios (right graph).
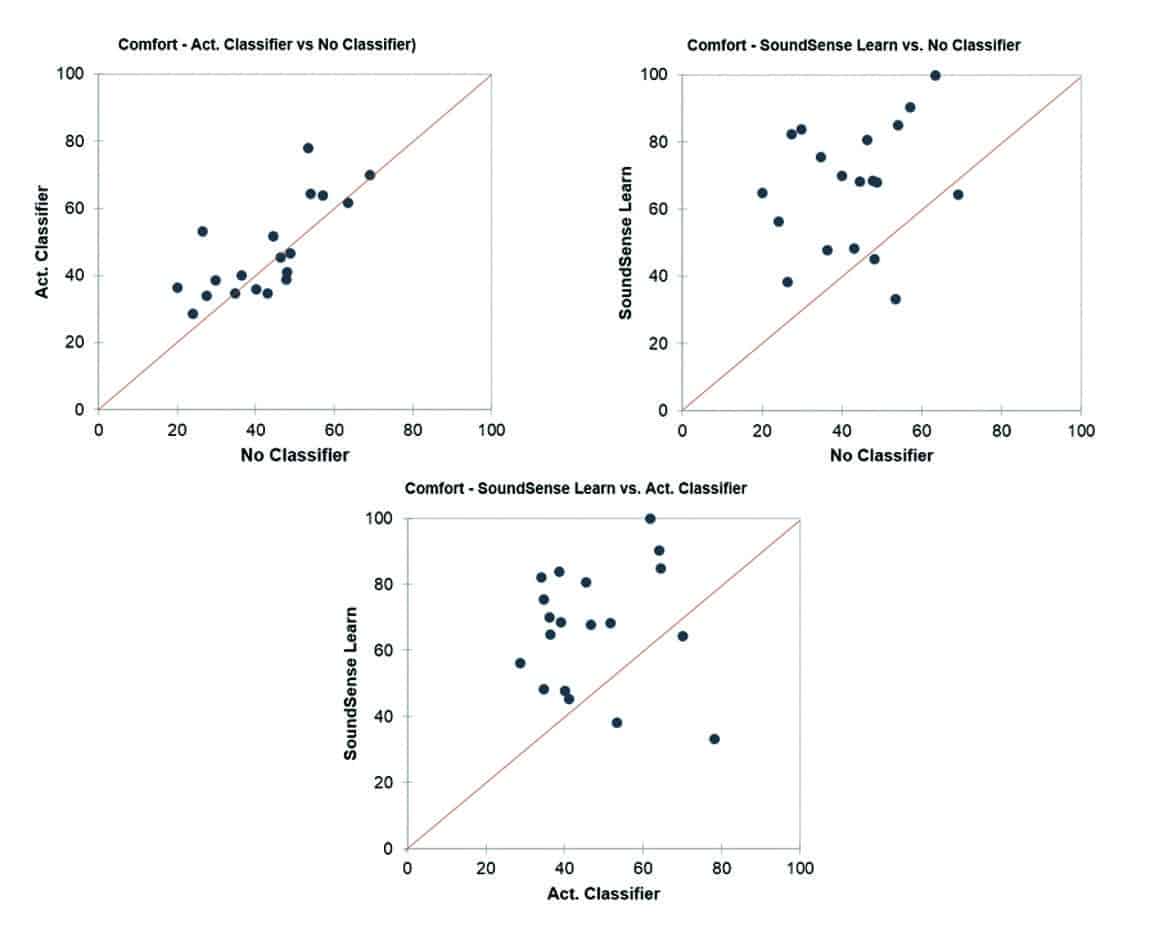
Figure 6. Direct comparison of each test participant’s average rating (over samples) for No Active Classifier, Active Classifier, and SoundSense Learn. We can see that 84% of the test participants achieved improved comfort using SoundSense Learn when compared to No Active Classifier.
Sound Quality
In addition to improving listening comfort, it was hypothesized that SoundSense Learn could be used to improve sound quality. In the experiment, sound quality was defined as relating to how much you prefer to listen to the sample being presented to you. The test participants could use the SoundSense Learn app to apply whatever HA parameter settings they found to increase the sound quality for the three given music samples (top of Table 1).

Table 1. Overview of background noise and music samples used in the test, including the associated auditory intention.
Using SoundSense Learn, the test participants experienced a significant increase in sound quality, both over No Active Classifier and Active Classifier (p<0.05). The pattern of increased listening comfort was consistent across the tested sound scenarios (Figure 7), except for the Contemporary2 sample (jazz trumpet). Overall, 89% of the test participants preferred the HA parameter settings they achieved using SoundSense Learn over the No Active Classifier setting (Figure 8).
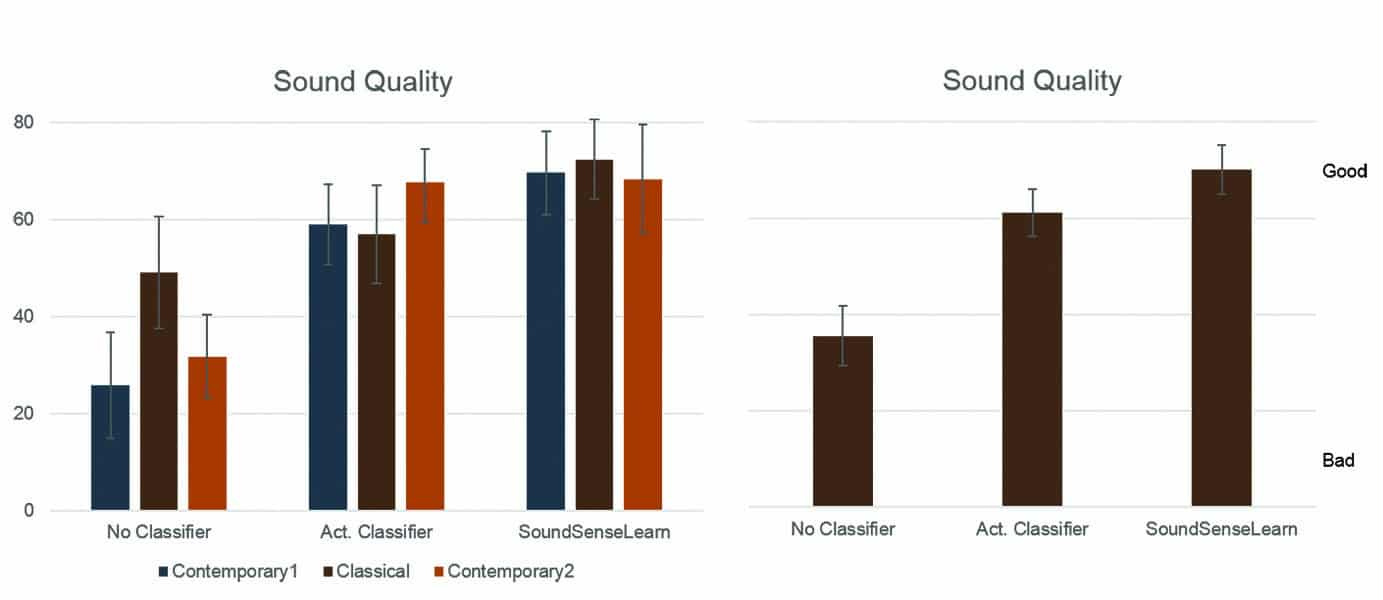
Figure 7. Mean scores of ratings of perceived sound quality on the Continuous Quality Scale for each subject’s individual setting (with 95% confidence intervals). Significant improvements were shown for SoundSense Learn over both active classifier and classifier not active (p<0.05). In addition we can see a stable performance of SoundSense Learn across the three sound scenarios (right graph).

Figure 8. Direct comparison of each test participant’s average rating (over samples) for No Active Classifier, active classifier, and SoundSense Learn. We can see that 89% of the test participants achieved improved comfort using SoundSense Learn when compared to No Active Classifier.
As shown in the previous section, SoundSense Learn showed clear and significant increases for listening comfort and sound quality. Even though the feature performed exceedingly well in the current iteration, it is important to remember that, as with other machine learning technologies, it has the potential to get better and more precise over time. It is our hope that continuous data generated by users of SoundSense Learn will lead to significant improvements in listening.
We also find it important to increase the ecological validity of our research methods when testing HA features, because it ensures a more direct link between what we measure and what the user can expect from the feature. While the sound scenario simulation was performed up to industry standard and a visual context was provided, any future testing of SoundSense Learn should focus on further increasing the ecological validity of the setup. Improvements could potentially include Virtual Reality (VR) for improving context and making auditory intention even more clear. Large-scale data from real-life field trials and clinical feedback will also play an important role in further improving the feature and making it even more accessible to users.
Summary
This article provided a short overview of the potential for SoundSense Learn to facilitate user control according to their auditory intention. SoundSense Learn is a feature that uses machine learning to easily and efficiently apply user input to optimize HA parameters. The feature was tested in a double-blind paradigm with recordings made of individual SoundSense Learn HA parameter settings for 19 test participants. Significant (p<0.05) increases in sound quality and comfort were found when compared to both the Not Active and Active Classifier conditions. The feature performed consistently in improving sound quality and listening comfort across all test samples.

Biography: Oliver Townend, BSc, is Audiologist and Audiology Communications Manager; Jens Brehm Nielsen, PhD, is Architect, Data Science & Machine Learning; and Ditte Balslev, MA, is Audiological Affairs Specialist at Widex A/S in Lynge, Denmark.
Correspondence can be addressed to Oliver Townend at: [email protected]
Citation for this article: Townend O, Nielsen JB, Balslev D. SoundSense Learn—Listening intention and machine learning. Hearing Review. 2018;25(6):28-31.
References
-
Townend O, Nielsen JB, Ramsgaard J. Real-life applications of machine learning in hearing aids. Hearing Review. 2018;25(4):34-37.
-
Nielsen JB, Nielsen J, Sand Jensen B, Larsen J. Hearing aid personalization. Paper presented at: 3rd NIPS Workshop on Machine Learning and Interpretation in Neuroimaging; December 5-10, 2013; Lake Tahoe, Nev. http://eprints.gla.ac.uk/119556/1/119556.pdf
-
Kuk F. Going BEYOND A testament of progressive innovation. Hearing Review.2017;24(1)[Suppl]:3-21.
-
Aldaz G, Puria S, Leifer LJ. Smartphone-based system for learning and inferring hearing aid settings. J Am Acad Audiol. 2016; 27(9)[October]:732-749.
-
Nielsen JBB, Nielsen J, Larsen J. Perception-based personalization of hearing aids using Gaussian processes and active learning. IEEE/ACM Transactions on Audio, Speech, and Language Processing.2014;23(1):162-173.
-
ITU Radiocommunication Assembly. ITU-R BS.1534-3: Method for the subjective assessment of intermediate quality levels of coding systems. Updated October 2015. Available at: https://www.itu.int/rec/R-REC-BS.1534-3-201510-I/en
-
DELTA. SenseLabOnline. http://www.senselabonline.com



Highly encouraging to see Music is taken seriously!
Most Health Service fitting in UK is still targeted on the 250 to 8k range, no assessment being made outside that.
Similarly, our professional education lags behind, though Dr Alinka Greasley’s new research ‘Music and Hearing Aids’ may well change things.
My interest is as a former BBC-trained recordist, making the best of obsolete HAs in narration/music freelance mixing work. Also enjoy live organ. Hope one day to hear the pedals without the familiar recourse to half-dislodged earmoulds!
Strength to you.