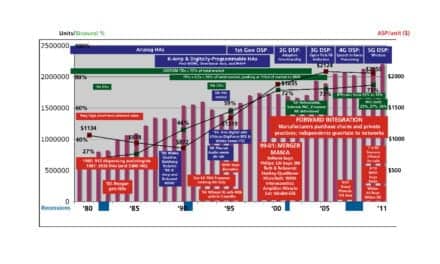
The challenge of relating electroacoustic measurement data to hearing instrument user requirements and preferences has long been considered both attractive and daunting. In spite of extensive and diligent efforts by standards organizations to tackle this problem, many fundamental properties of speech and ambient sounds are not well represented in the commonly applied measurement techniques. The problem seems particularly pertinent to digital hearing instruments.1
Attempts to capture the brief temporal dynamic properties of speech through hearing instruments have been reported over the years2, but these important elements have remained generally elusive. A relatively new software program (Tempus 3D) developed by Frye Electronics provides a tool for the analysis and portrayal of such acoustical signals. Based on a type of proprietary wavelet analysis, the 3D program allows precise measures of magnitude, time and frequency in brief time segments.3 Examples of the use of this software for characterizing digital hearing instruments were provided in a recent Hearing Review article.1
Wavelet transforms are well suited for time-frequency analysis, and one of their particularly attractive features is an arguably superior representation of time detail4-7 over the more familiar Fast Fourier Transform (FFT) or Short-Time Fourier Transform (STFT) approaches. This is particularly the case for “non-stationary” types of signals, such as the rapidly changing elements of speech consonants. Furthermore, in the analysis of the spectral energy of speech, the surprisingly high magnitude of high frequency brief transients may be better revealed by the Tempus 3D method3 than by other mathematical measurement strategies.
This paper will describe some uses of this software program in a private practice clinical setting to look for spectral correlates that might relate to perceptual experience as reported by hearing instrument users. For some of the data illustrated below, in-situ hearing aid outputs were collected by means of a standard clinical probe microphone (Frye Electronics FP-40) system. In another instance, the output of a hearing aid system was recorded through a 2cc coupler. Together they provide a few selected illustrations of how the time, frequency and magnitude properties of real speech elements—processed through hearing aids—can be examined in considerable detail with relatively simple procedures.
A variety of acoustical signals were routed to the audio input of the computer used for programming hearing instruments in the clinic. For the segments reported here, inputs consisted of both pre-recorded speech in quiet and noisy conditions. Levels and acoustical circumstances were controlled to make useful comparisons of several conditions for digital and analog hearing instruments. The data were first digitized and then converted to “.wav” files for subsequent playback and analysis.
Distortion due to Low Battery Voltage
A customer presented with a complaint about audible distortions in his programmable analog hearing instrument. The user reported that it was particularly noticeable on /s/ sounds and high frequency transients. The probe microphone assembly’s monitor allowed the clinician to hear the distortion. Tempus 3-D data was obtained for a compact disc recording of speech discrimination materials (Speech Audiometry Materials produced by Brigham Young Univ. Hearing and Speech Laboratory) with the carrier phrase “Point to ____.” The test material was played from a speaker located one meter from the listener’s head. Digital recordings were made from the output of the probe microphone with the tip of the calibrate tube located 5 mm medial to the interior of the hearing instrument in the client’s ear.

Fig. 1. Frequency/magnitude portrayal from the Tempus 3D program of the recording “Point to School” in a hearing instrument with audible distortion. Time (ms) is located along the horizontal x-axis, frequency (Hz) is located along the vertical y-axis, and magnitude is given as a color with a range of 50 dB represented from violet (strongest sounds) to dark blue (weakest sounds). The red band of energy that essentially persists across the entire 120 milliseconds contains a large part of the /s/ sound of interest. Note that the frequency of that band of greatest intensity is between 3 and 4 kHz. The vertical black line in the figure is taken at 27 milliseconds into the data. A band of yellow colored energy can be seen around 500 Hz.
A sample of the /s/ segment of the recording, “Point to School” is shown in Fig. 1. Because the /s/ sound on “school” contained audible distortion, the window of analysis was applied to a 20 millisecond (ms) period that clearly included that fricative sound. The software allows the user to play any selected segment. Hence, it was not difficult to isolate the period of interest within the total captured signal.

Fig. 2. A slice of time at 27 ms into the recording of Fig. 1. It can be seen that energy is spread well below the prominent /s/ center frequency in the 3000-4000 Hz range. The hearing aid battery was found to be the cause of this distortion.
The color map of Fig. 1 uses a one-sixth octave selection for the analysis. The 3-D portrayal represents the 120 ms time segment containing the /s/, as picked up in the client’s ear canal with the hearing instrument installed. To provide further detailed analysis, a slice of time at 27 ms was pulled out. The frequency/magnitude portrayal of that slice is illustrated in Fig. 2. It is clear that energy is spread well below the prominent /s/ center frequency between 3 and 4 kHz at that point in time.

Fig. 3. View of the “s” in “school” after the hearing aid battery was replaced.

Fig. 4. Further examination of a single point in time, where the “s” in “school” is almost completely contained around the 3500 Hz region rather than spread into the lower frequencies (i.e., 500-1500 Hz).
It turned out that a fresh battery solved the audible distortion of the client’s hearing instrument. The previous battery tested on the borderline of the “good” range of a standard office battery voltage tester, but was apparently insufficient for the user’s hearing aid circuit. It was instructive to then look at the difference in the hearing instrument’s output for the same passage and conditions with the distortion now removed. Fig. 3 shows the same three-dimensional view of the /s/ in “school” after the battery had been replaced. A slight shift of the time axis may be noticed, as it was difficult to align the analysis window in exactly the same point in the waveform for the two sequential measures. However, the 3-D view after the good battery was installed indicates much better containment of the /s/ energy in the high frequencies, and less downward energy spread of distortion frequencies is indicated by more blue and less green colored data. This is further verified by examining the single point in time from the slice portrayal in Fig. 4. As compared to Fig. 2, the energy of the /s/ is much more contained in the narrow area around 3500 Hz, rather than spread noticeably into lower frequency regions, particularly at 500 and 1500 Hz. Therefore, the use of this kind of microscopic eavesdropping tool made it fairly easy to see spectral properties that related to audible distortions.
DSP and Frequency Shifting
Digital signal processing (DSP) allows for many interesting alterations of audio signals. One that appears to be quite useful is incorporated in hearing instruments developed and produced by AVR Sonovation of Israel. The AVR ImpaCt hearing instrument uses a digital speech re-coding algorithm, and is designed for listeners with severe-to-profound losses in the high frequencies. One algorithm is intended to relocate energy from speech in higher frequencies downward to where amplification might be clinically useful for the listener.

Fig. 5. View of the time period containing the /k/ sound in “Thank you” without application of frequency compression.
Fig. 5 shows the 3-D view of the time period containing the /k/ sound in “Thank You” prior to applying the frequency compression algorithm. The recorded passage utilized a female talker. In this case, the outputs from an in-the-ear (ITE) hearing instrument were collected from a 2cc coupler prior to spectral analysis.

Fig. 6. Same time period in Fig. 5 after frequency compression/transposition by AVR’s ImpaCt. Note dramatic lowering of the frequency energy previously above 4000 Hz.
Comparing Fig. 5 to Fig. 6, where the algorithm has been activated, clearly shows the intended frequency shift effect of the AVR hearing instrument. In both figures, a cursor line was drawn at a point 40 milliseconds into the analysis. Note particularly the dramatic lowering in frequency of the energy previously above 4000 Hz.

Fig. 7. Unprocessed segment of the unvoiced plosives at the end of the word “basket.”

Fig. 8. End of the word, “basket” (compare with Fig. 7), after processing by algorithm.
Another passage with a female speaker was utilized to examine the processing’s effect on the unvoiced plosives at the end of the word, “basket.” Illustrations of that time period are shown in Fig. 7 for the unprocessed original and Fig. 8 with the processing activated. Again, the robust and unequivocal effect of the AVR algorithm can be seen. The illustrated area largely consists of the co-articulated “t” at the end of “basket” followed by the beginnings of the unstressed “i” vowel in the word “is”. Clearly, AVR’s “proportional frequency compression” algorithm works quickly enough to adjust to very rapid dynamic changes in speech sounds. The effect was also acoustically unambiguous to both trained and untrained listeners.

Fig. 9. The entire 1.85 second recording of the sentence, “The basket is full of grapes.” The top spectrogram shows the unprocessed sentence and the bottom spectrogram shows the sentence after processing by the ImpaCt device. The software program used here is R.S. Horne’s Spectrogram v5.0.5 freeware.
A more conventional method of showing the frequency shift is provided in the spectrographic comparison portrayals of Fig. 9. In this figure, a different software program (Spectrogram version 5.0.5 freeware by R.S. Horne) was used to show a longer period, including the approximately 1.85 seconds of the entire sentence: “The basket is full of grapes.” The top shows the unprocessed sentence and the bottom when the processing is activated.
DSP and Brief Component Enhancement
In another application of the Tempus 3D, some rather surprising results were observed. Several clients were fit with digital hearing instruments having an algorithm that was designed to improve speech understanding by increasing the magnitude of brief speech transients. In a number of informal listening tests, neither normal-hearing or hearing-impaired listeners reported a noticeable difference when the algorithm was activated to a maximum extent versus turned off. This led to some additional probe microphone recordings from the ears of consumers wearing hearing aids for 3D temporal analysis.

Fig. 10. One-sixth octave analysis output of the /t/ sound in the sentence, “I hope you didn’t have to wait too long,” as spoken by a female talker in noise, where the hearing instrument had its noise reduction algorithm activated and adjusted to maximize speech transients such as the unvoiced plosive /t/.

Fig. 11. Same analysis of Fig. 10 sound sample with the speech enhancement algorithm turned off.
Fig. 10 shows a sixth-octave analysis output of the /t/ sound in the sentence “I hope you didn’t have to wait too long” from a recording by a female speaker in noise. In this figure, taken from a probe microphone output, the software in the digital hearing instrument is set to maximize such speech transients as the unvoiced plosive /t/. When compared to Fig. 11 of the same time period with the algorithm deactivated entirely, it is indeed difficult to visually observe the anticipated differences.

Fig. 12. Single point slice of data in Fig. 10 showing consonantal energy around 5 kHz while the “ay” sound in “wait” is seen at around 500 Hz.

Fig. 13. Single point slice of data in Fig. 11 where the speech enhancement algorithm was employed.
As in the earlier techniques, single point slices were also taken for more detailed analysis of this sample. These data are shown in Figs. 12 and 13. The consonantal energy is clearly concentrated in the region around 5 kHz, while portions of the tail end of the “ay” vowel in “wait” is seen (around 500 Hz). However, even this closer scrutiny failed to show a clear effect of activating the algorithm. If the intended effect was to provide 3 or more dB of transient speech sound increase, it seems likely that this method of analysis would have revealed such an effect. Another conventional spectrographic comparison was performed with the results shown in Fig. 14. It is noteworthy how much energy above 5 kHz is evident in the output of the hearing instrument in the ear canal.

Fig. 14. A look at the same sentence shown in Figs. 10-13 using the freeware program created by R.S. Horne. Top: with the transient DSP algorithm deactivated; Bottom: with algorithm set to maximum.
For the audio samples shown in Figs. 10-14, a panel of five listeners, two with hearing impairment and three with normal hearing, were asked to make A/B listening comparisons of 10 randomized recordings of each condition (algorithm programmed to maximum and turned off). No differences could be detected among the tallies for this simple test. This suggests minimally that the Tempus 3D measure did accurately reflect the insufficiency of the digital signal processing. Variations of the passage were studied with samples of the utterance in quiet, as well as in noise, and with compression and other noise-reducing algorithms turned on and off. Essentially the same spectrographic findings were observed in each case. Hence, in our clinic, it was not possible to verify the value of this particular processing scheme.
Summary
This brief technology paper described a few samples of some ongoing data collection of hearing instrument processing phenomena. The tool used to obtain the data is an inexpensive way to obtain fast and reliable examinations of brief transient acoustical events. The Tempus 3D software applies a type of wavelet analysis to capture the rich detailed temporal aspects of acoustical signals. Wavelet transformations provide some advantages over other measurement techniques when non-stationary transient phenomena, such as speech plosives and bursts, are of interest.
Measures of hearing instruments using this software are continuing in the private practice setting where these findings were obtained. Other hearing instrument “behaviors,” and their perceptual consequences, will be reported at a later time. As 21st century hearing instruments become progressively capable of new and exotic signal processing schemes, there is clearly a need for more comprehensive analysis of their operations on real-world signals and in real-use conditions.3
The method of analysis demonstrated in this article is an inexpensive means of providing a valuable addition to the array of tools that can be advantageously applied to this challenge. Obviously, any tool that might lead to a better understanding of acoustical satisfaction among hearing instrument users merits the consideration of auditory scientists and professionals.
Acknowledgements
The author wishes to thank Barak Dar and Joel Skoog of AVR Sonovations, Minneapolis, for their assistance in the preparation of this article, particularly for help in generating Figs. 5-10.

References
1. Frye G: Testing digital hearing aids: the basics. Hearing Review 2000; 7 (8):20-27.
2. Schweitzer C: Time: The third dimension in hearing aid performance. Hear Instrum 1986; 37 (1): 24-27.
3. Schweitzer C & Frye G: Pursuing the elusive in 3-D: Characterizing 21st century hearing aids. Paper presented at the American Auditory Society meeting; Scottsdale, AZ, April 2000.
4. Schiff S: Resolving time-series structure with a controlled wavelet transform. Optical Engineering 1992; 31 (11): 2493-2495.
5. Krishan G & Schweitzer C: Application of wavelet transformations in auditory science. Paper presented at the American Auditory Society meeting; Scottsdale, AZ, March 1999.
6. Rioul O, Vetterli M: Wavelets and signal processing. IEEE SP Mag 1991; 14-38.
7. Wit H, van Dijk P & Avan P: Wavelet analysis of real ear and synthesized click evoked otoacoustic emissions. Hear Res 1994; 73: 141-147.
Correspondence can be addressed to HR or Christopher Schweitzer, HEAR 4-U. 2770 Arapahoe Rd., #126, Lafayette, CO 80026; email: [email protected].
.gif)