Supplement | January 2017 Hearing Review
The science, research, and technology behind Effortless Hearing
As we learn more about aging, cognition, and the importance of hearing, it is becoming clear that one goal of hearing aid design and fitting should be to create a favorable signal-to-noise ratio and reduce the amount of effort required to decode speech. In short, we need to facilitate communication by making speech signals more accessible to the listener—or what Widex calls Effortless Hearing. This special supplement of The Hearing Review provides an overview of the research, engineering, and clinical testing behind Effortless Hearing and why we believe it represents a landmark achievement in hearing aid design.
Francis Kuk, PhD
Francis Kuk, PhD, is director of the Widex Office of Research in Clinical Amplification (ORCA) in Lisle, Ill.

Widex recognizes that natural sounds that preserve more cues for identification are less cognitively demanding for the brain to process than sounds that are unnatural. This is why we believe Widex hearing aids have the most natural and admired sound quality in the industry, with recent studies1 supporting this view.
The expressed consequence of this naturalness, however, may differ depending on a listener’s cognitive capacity. For listeners with a poor working memory, the natural sound would have preserved more of the important speech cues (temporal, spectral, etc) than an unnatural sound. This lessens the needs (and efforts) of the listeners to retrieve other resources (such as memory) for understanding. The reduced effort could improve overall performance in the listening situation. For listeners with a good working memory, the natural sound enhances the listening experience by providing a better sound quality, even though speech understanding may not be enhanced further.
In other words, a hearing aid design rationale that preserves the naturalness of sounds and enhances the important speech cues would benefit people of all cognitive capacities. Such a belief for natural sounds guided Widex in its product design throughout the years.
The latest expression of that design rationale, which we termed Effortless Hearing, is first realized in the UNIQUE hearing aid2 and continues into the BEYOND series. This special supplement to The Hearing Review explains why Effortless Hearing is important, describes hearing aid elements that could help achieve Effortless Hearing, and presents evidence about how the features in the BEYOND may improve listening experiences.
WHY IS EFFORTLESS HEARING IMPORTANT?
Applying meaning to sounds and understanding of speech is a complex process. According to Bregman’s theory of Auditory Scene Analysis (ASA),3 the brain takes inputs from the two ears and extracts binaural (interaural level and timing differences), temporal (onset, offset, duration, and envelope), and pitch cues (fundamental and harmonics) to construct an auditory scene of the specific listening environment.
From these cues, important speech features (such as fundamental frequency, amplitude modulation, etc) are extracted and grouped based on their similarities. This provides the brain with different auditory objects so the listener may focus his/her attention on a particular sound while ignoring other sounds in the sound environment. To derive meaning from the auditory objects, the listener will need to retrieve from his/her lexical memory, as well as other contextual cues. Thus, understanding is dependent on the integrity of the auditory pathway at every stage—from external ear through temporal cortex—the availability of sufficient cognitive capacity, and the naturalness of the input sounds.
Unfortunately, none of that can be assumed of the average hearing-impaired person wearing hearing aids. This is especially so for an elderly hearing-impaired person who is disadvantaged from a less audible and distorted signal reaching a deprived auditory system that may have varying degrees of cognitive impairment in attention, memory, and processing.4
WHAT HAPPENS TO THE BRAIN WITH AGING?
A decrease in brain mass occurs with aging.5 This is especially seen in the gray matter in the prefrontal cortex where working memory and executive function reside and in the medial temporal lobe (including the hippocampus) where learning and memory reside.6 Salat et al7 also reported decreases in the white matter in the frontal lobe and the corpus callosum. Resnick et al8 also reported atrophy in some parietal regions. In addition, the number of synaptic connections also decreases with age. Dementia is implicated when the number of synapses decreases by more than 40%.9
These physiological changes are also associated with changes in cognitive abilities. Fluid abilities, or those that involve processing of information in cognitive domains such as attention, memory, executive function, language and visuospatial abilities, show a decrease as we age. Abilities that are accumulated through our experiences, or crystalized abilities, stay or improve with age.10 In addition, Vaden et al11 showed a functional change in the cingulo-opercular activity that is important for a listener to adjust his/her attention on a task to optimize performance. Davis et al12 also reported a posterior-anterior shift in cortical activities with aging, indicating an increased in attention and listening effort to compensate for the loss in sensory input as we age. These changes suggest that an elderly person is more likely to have a poorer working memory, is more distractible, and needs to spend more effort to complete an activity.
WHAT HAPPENS TO THE BRAIN WITH AGING?
It is generally known that a loss of hair cells in the cochlea occurs with aging. This is observed as a decrease in hearing thresholds, especially in the high frequencies. More recently, Kujawa and Liberman13 reported that age and noise exposure may also result in a loss of synapses in a mouse model even though thresholds remain normal. The loss of hair cells and/or synapses limits the capacity of the auditory system to transmit information to the brain, and could potentially lead to retrograde degeneration reflected in higher auditory centers—from the cochlear nucleus to the auditory cortex. This is frequently cited as “the central effects of a peripheral hearing loss.”14
The loss of hair cells and/or synapses limits the capacity of the auditory system to transmit information to the brain, and could potentially lead to retrograde degeneration reflected in higher auditory centers—from the cochlear nucleus to the auditory cortex. This is frequently cited as “the central effects of a peripheral hearing loss.”
Eckert et al15 also reported a decrease in gray matter volume in the auditory cortices associated with aging. Bharadwaj et al16 suggested that a loss of auditory fibers could disrupt the synchronous firing, or phase locking in the central auditory system, leading to poorer coding of temporal features of sounds. The physiological changes within the auditory system with age explain the poorer hearing sensitivity, and the reduced spectral, temporal, and intensity resolution.17
The recent findings on the temporal coding and the involvement of the cingulo-opercular network also suggests that hearing loss not only reduces the system’s ability to encode sounds, but also in attending to multiple sound sources. This may be a major reason for the speech-in-noise complaint as frequently reported by hearing-impaired people. It also suggests that an elderly hearing-impaired person needs fewer co-occurring sounds at a favorable signal-to-noise ratio (SNR) to ensure successful communication compared to an elderly normal-hearing person.
HOW DO WE UNDERSTAND LANGUAGE, AND HOW MUCH EFFORT IS EXPENDED IN DOING IT?
The decrease in size of the working memory with age may explain a person’s reduced ability to understand speech in noise.18,19 The size of the working memory, as measured using the Reading Span test20 at many research facilities, reflects the ability of the person to retain and process (including attention to task) information.
How working memory capacity may affect speech understanding has been postulated by Ronnberg et al21 using the Ease of Language Understanding (ELU) model. In this model, it is postulated that during a speech understanding task, the incoming speech goes through a stage of unconscious processing whereby it is compared to lexical representations stored in the long-term memory. If there is a good match, understanding of the speech message occurs automatically and subconsciously. When there is not a good match, a level of explicit processing occurs where both top-down and bottom-up processes are involved to resolve the mismatch. Depending on the degree of mismatch, this process takes varying amounts of time and effort. For individuals with a good working memory, this process may take little time, be less effortful, and have a high rate of success. For people with a limited (or poor) working memory, this process may take longer, require greater effort, and still have a higher risk of failure because of insufficient working memory.
In 2016, Edwards22 proposed a hybrid model of Bregman’s Auditory Scene Analysis (ASA)3 and Ronnberg et al’s ELU21 where higher level of processing (such as attention), and the result of the explicit (or conscious) processing is applied before the pre-attentive processing. This hybrid model suggests that the individual’s motivation for the task (eg, listening to speech in noise), including his/her performance on the task (ie, successful or unsuccessful) may shape the ASA and dictate how much perceived effort the listener expends during the communication process.
At Widex, we have been operating on a sensory surface concept in understanding perception. The sensory surface is a theoretical construct linking the external world to the perceptual world. The input to this surface is the input sounds, the “goodness” of which is determined by factors such as the environments, the speaker characteristics, and the hearing aid processing. Any distortions (from the natural inputs, hearing aids, or from the impaired auditory system) could lead to a distorted input for the perceptual system where the processes described in the ASA and the ELU models are applied. The sensory surface construct deems the input and the integrity of the auditory periphery important in shaping (and encoding) the input signals prior to its use in the perceptual domain.
These models (including ELU, the hybrid model, and the sensory surface construct) would predict that speech understanding is the most successful (and least effortful) if the task can bypass any explicit processing—in other words, if all processing is implicit and automatic. This would make speech understanding effortless for everyone regardless of their cognitive capacities.
This is a lofty long-term goal and may not be realistic currently because individuals do differ in their cognitive capacities (which are difficult, if not impossible to improve), and there are multiple factors that affect cognition (which we are continuing to explore). On the other hand, if one can improve the quality of the sounds perceived at the most peripheral level, this alone will increase the likelihood of an accurate and thorough ASA. This may increase the odds that automatic processing is sufficient to understand the message, and minimal effort will be needed for explicit processing. This could motivate listeners and encourage attentive behaviors for a longer time, resulting in a better ASA and a better listening outcome for people of all cognitive capacities.
Thus, hearing aids should be designed to restore audibility, minimize distortions (and distractions) while preserving the natural cues in order that the resulting sounds have the best potential to be processed in the most efficient manner. Such hearing aids would minimize the input demands placed on the listeners and potentially eliminate one source of variables that requires additional cognitive effort for processing. This lessened effort motivates continued attentive listening and increases communication success for everyone.
This is the thinking behind the Effortless Hearing design principle. It is easy to see that Effortless Hearing is not merely a slogan, but rather a commitment to integrating the latest knowledge and technology into a form that enhances the lives of every hearing-impaired person.
Hearing aids should be designed to restore audibility, minimize distortions (and distractions) while preserving the natural cues in order that the resulting sounds have the best potential to be processed in the most efficient manner. Such hearing aids would minimize the input demands placed on the listeners and potentially eliminate one source of variables that requires additional cognitive effort for processing. This lessened effort motivates continued attentive listening and increases communication success for everyone. This is the thinking behind the Effortless Hearing design principle.
HEARING AID ELEMENTS THAT ENHANCE EFFORTLESS HEARING
Effortless Hearing design requires the preservation of all important acoustic cues and the enhancement of specific ones based on the needs of the individual hearing-impaired person.
One may better appreciate the details of this design rationale by examining the key features involved in the three functional stages that all hearing aids encompass: capture, purify, and process sounds. In the capture stage, all the necessary nuances of the incoming sounds (ie, natural hearing) should be available for later-stage processing. Because not all natural sounds are desirable, the hearing aids must be able to purify and process the captured incoming sounds in such a way that they retain all the necessary nuances without the distractions that may make them more effortful to hear. It is easy to see that sounds that are not captured, or are captured incorrectly, would be difficult to purify or process at later stages. Because of the hearing loss (and its attenuative and distortive consequences), sufficient individualization must be provided during the processing stage to meet the needs of the wearer in each listening environment. The important distinctions among different hearing aids (and designs) so they qualify for the Effortless Hearing principle are the implementations behind each of these three stages. We will group the features on the BEYOND hearing aid under these three stages to illustrate how the BEYOND is designed to promote Effortless Hearing.
The BEYOND is built on the same U-platform as the UNIQUE hearing aid; thus many of the features and benefits seen in the UNIQUE may be expected of the BEYOND also. This is true both on an overall basis, as well as on a feature base. The important advance made in the BEYOND is the TRI-LINK, a successful integration of a new made-for-iPhone (MFi) 2.4 GHz wireless chip (Pure-link) so that audio signals from a smartphone may be streamed directly to the BEYOND (Figure 1).
![Figure 1 [Click on images to enlarge]: BEYOND functional block diagram.](https://hearingreview.com/wp-content/uploads/2017/02/fig-1.jpg)
Figure 1 [Click on images to enlarge]: BEYOND functional block diagram.
Effortless hearing requires that all the natural nuances within the input sounds are captured accurately. This includes information in the frequency, intensity (including intensity changes and relative intensities between ears) and temporal domains. In a digital hearing aid, the sampling frequency of the analog-to-digital converter (ADC) determines the frequency range of sounds that can be captured. For example, a sampling frequency of 33 kHz (as used in all Widex digital hearing aids since the SENSO in 1996) captures input sounds up to 16.5 kHz. As in all Widex wireless hearing aids, the BEYOND WIDEX-LINK also samples at a rate or 25 kHz, capturing sounds up to 12 kHz for transmission.23
The number of bits used in the ADC determines the range of sounds and the maximum SPL that can be captured by the hearing aid. As a simplification, one bit of the ADC provides about 6 dB of dynamic range. To preserve all the natural nuances of the input sounds, the ADC must be able to capture sounds as soft as 10 dB SPL and as loud as 110-115 dB SPL.24 Because modern hearing aid microphones have an upper physical limit of about 115 dB SPL and a lower physical limit of 5-10 dB SPL, only the range of sounds between 5 and 115 dB SPL can be meaningfully captured by hearing aids (ie, less than 110 dB dynamic range). Unfortunately, even in 2013, most hearing aids had a low input limit below 105 dB SPL, and some even as low as 96 dB SPL. This severely limits the natural quality of loud sounds, such as speech in noisy places and moderately loud music.
Widex introduced True Input Technology in the DREAM hearing aids in 2013 and raised the upper input limit linearly to 113 dB SPL25 while keeping an input dynamic range between 15 and 113 dB SPL. The ability to preserve the linearity of the inputs at these levels prevents the risk of distortion at the input stage which may degrade the effectiveness of subsequent signal processing algorithms. In three separate studies, it was shown that the high input limit of 113 dB SPL resulted in better speech recognition in noise at an input level above 85 dB SPL,26,27 and sound quality ratings of music28 than a hearing aid with an input limit of 103 dB SPL.

Figure 2: The extended 108 dB linear input dynamic range of the BEYOND hearing aid.
In the BEYOND, Widex increases the number of bits in the ADC while keeping the upper limit of the BEYOND at 113 dB SPL. This extends the lower limit to 5 dB SPL, effectively providing a linear operating range of 108 dB SPL (Figure 2, from 5 to 113 dB SPL). This suggests that the BEYOND would capture linearly the full range of input sounds permissible by current microphone technology, minimizing the risk for input distortion and allowing for more accurate subsequent processing.
Figure 1 also shows that there are 4 independent ADC in the BEYOND. Two ADC are reserved for the front and back microphones (which are required for the adaptive directional microphone system), one is reserved for the Pure-link, and one for the T-coil input. This means that signals from each input source can be independently sampled and processed without any compromises. For example, the previous MT option will leave the microphone in an omnidirectional mode while the user is using the T-coil. In the BEYOND, the MT option allows a directional microphone (which requires two microphone inputs) and the T-coil to be used at the same time. Similarly, one may also have a streamed input and a directional microphone input. This allows the BEYOND to capture a cleaner acoustic input in noise while the listener is using an MT or streaming option.
Because the auditory system uses input from both ears to assist in spatial awareness and sound localization,29 bilateral hearing aid fitting is a fundamental requirement to capture (and retain) the spatial and temporal characteristics of the input for subsequent processing. However, bilateral hearing aids do not guarantee that the natural inter-aural intensity difference (IID) and inter-aural timing difference (ITD) cues of the inputs are preserved at the output of the hearing aids. Additional signal processing is needed to preserve such cues. However, having all the inputs from both ears is critical for the subsequent processing.
The need to preserve inter-aural cues (intensity and time), along with the desire to link the wearer’s hearing aids to external audio devices for effortless hearing, prompted Widex to introduce the WIDEX-LINK wireless technology in the CLEAR.30 WIDEX-LINK uses near-field magnetic induction (NFMI) at 10.6 MHz for short range transmission and a proprietary 2.4 GHz band for long range transmission. Audio information from 2.4 GHz enabled sources are routed to an intermediary or relay device (such as the M-Dex, Com-Dex or Call-Dex) for conversion to a 10.6 MHz carrier for NFMI transmission and reception at the hearing aids. The short range NFMI also allows communication and synchronization between hearing aids of a bilateral pair. Information about the input levels at the two hearing aids, as well as the parametric settings, are shared between the two hearing aids at a rate of 21 times per second. This allows synchronized adjustment of compression settings, noise-reduction mode, determination of feedback, synchronization of Zen tones, as well as program and volume change between hearing aids.30
The BEYOND introduces the TRI-LINK wireless technology, which refines the current WIDEX-LINK wireless technology, and includes Pure-link technology. This uses Made-for-iPhone (MFi) technology to realize direct streaming from smartphones to hearing aids. A new 2.4 GHz antenna is added in the BEYOND in addition to the 10.6 MHz NFMI antenna. This new technology allows information (such as music, news, etc) to be streamed directly from smartphones to the wearer’s BEYOND hearing aids at a very low current drain. A current drain of 1.35 mA is estimated during inter-ear communication and <1.8 mA is estimated during typical daily use, assuming 25% streaming usage. This is lower than any comparable product currently on the market!
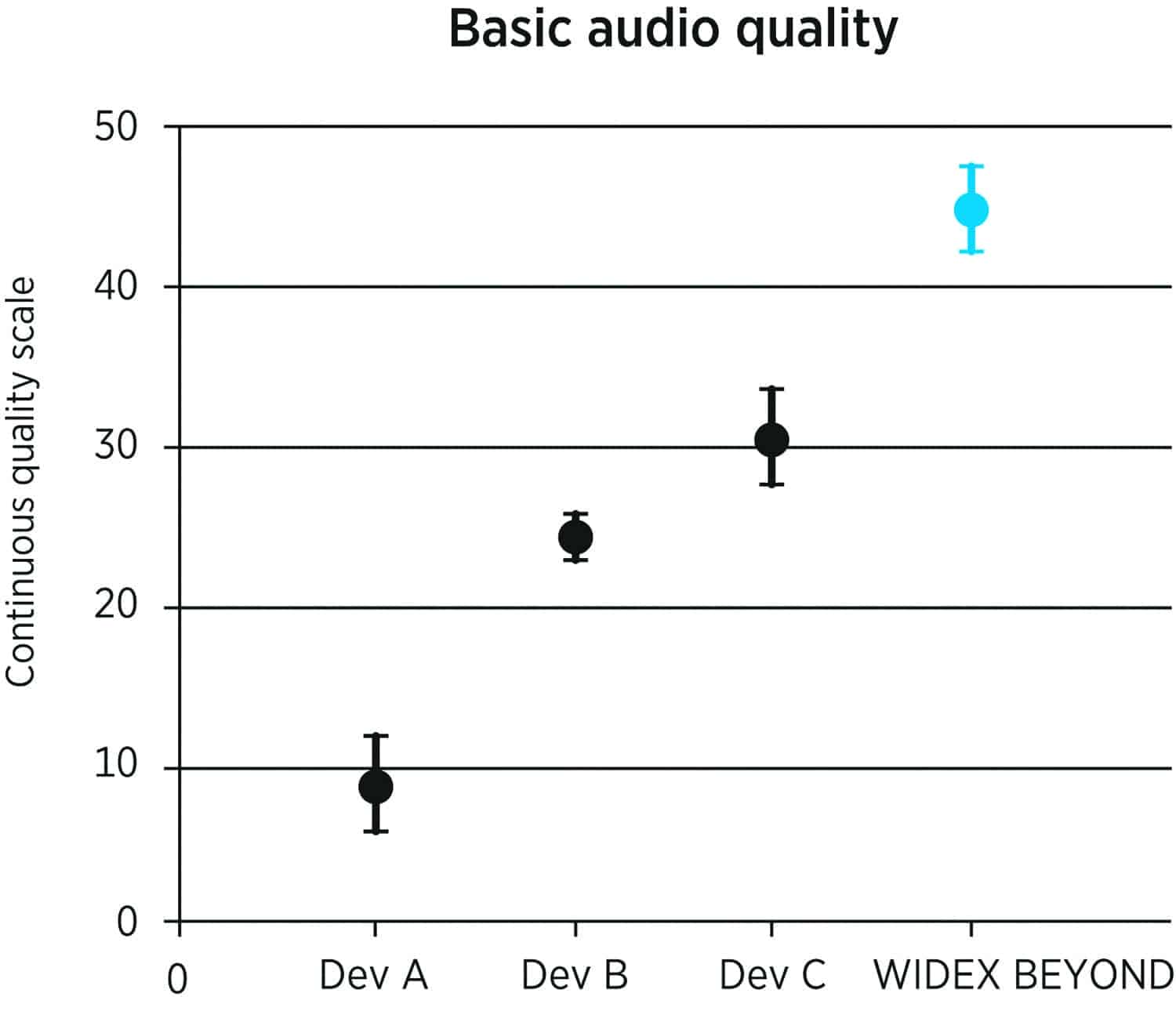
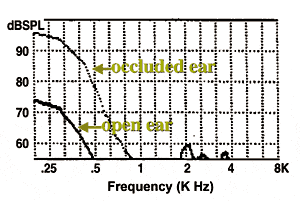
Figure 3: Sound quality ratings among 4 commercial MFi hearing aids that allow 2.4 GHz direct streaming.31
A recent study was conducted using the MUSHRA procedure comparing the sound quality of the BEYOND streaming with 3 industry competitors.31 A total of 20 normal-hearing individuals listened to sounds processed by the 4 pairs of hearing aids recorded through KEMAR while using a double-blind methodology. Listeners were able to listen and compare the sound qualities of speech and music samples for as long as needed in order to assign a rating. The results of the MUSHRA comparison is shown in Figure 3. It is clear that listeners preferred the quality of sounds streamed by the BEYOND over that of the other devices.
BEYOND PURIFICATION
Not all sounds that are captured are desirable for hearing aid wearers. If the undesirable sounds can be removed from the input stage before processing, this provides a cleaner signal for subsequent processes, such as compression and noise reduction. The cleaner signals could improve the speed and accuracy of processing (such as the identity of the environment, speech or noise, etc). Having only the desirable inputs could minimize the amount of distractions that the hearing aid wearers experience, improving their ease of listening and lessening the need for explicit processing. Obviously, all features that are dedicated to purification involve signal processing and are listed in this section for ease of conceptualization.
Wind Noise Attenuation (WNA)
Wind turbulence at the hearing aid microphones results in wind noise. The amount of noise is dependent on the wind speed and the position of the microphone opening. MarkeTrak VIII32 showed that only 58% of hearing aid wearers are satisfied with the performance of their hearing aids in windy situations. Minimizing the impact of wind (subjective annoyance, speech understanding) could result in effortless hearing and maximize communication success from mostly indoors to indoors and outdoors.
There are various approaches to wind noise reduction. As early as 2002, Widex took advantage of the different correlational properties of sounds created by wind and non-wind origins at the two microphones of a dual -microphone system. When wind is detected, the microphone system switches from a directional mic mode to an omnidirectional mode to minimize wind noise.33 Because wind noise is mostly low frequencies, the wind noise algorithm in the Diva33 also provides low-frequency gain reduction when wind noise is detected. In the CLEAR Super hearing aids, Widex added a weather cover to its receiver-in-the-ear (RITE) and behind-the-ear (BTE) hearing aids to laminarize wind flow and further reduce the impact of wind. Many manufacturers are still using combinations of what Widex has used as their main wind noise reduction algorithms. These methods reduce some annoyance from wind; however, they may not improve the signal-to-wind noise ratios.
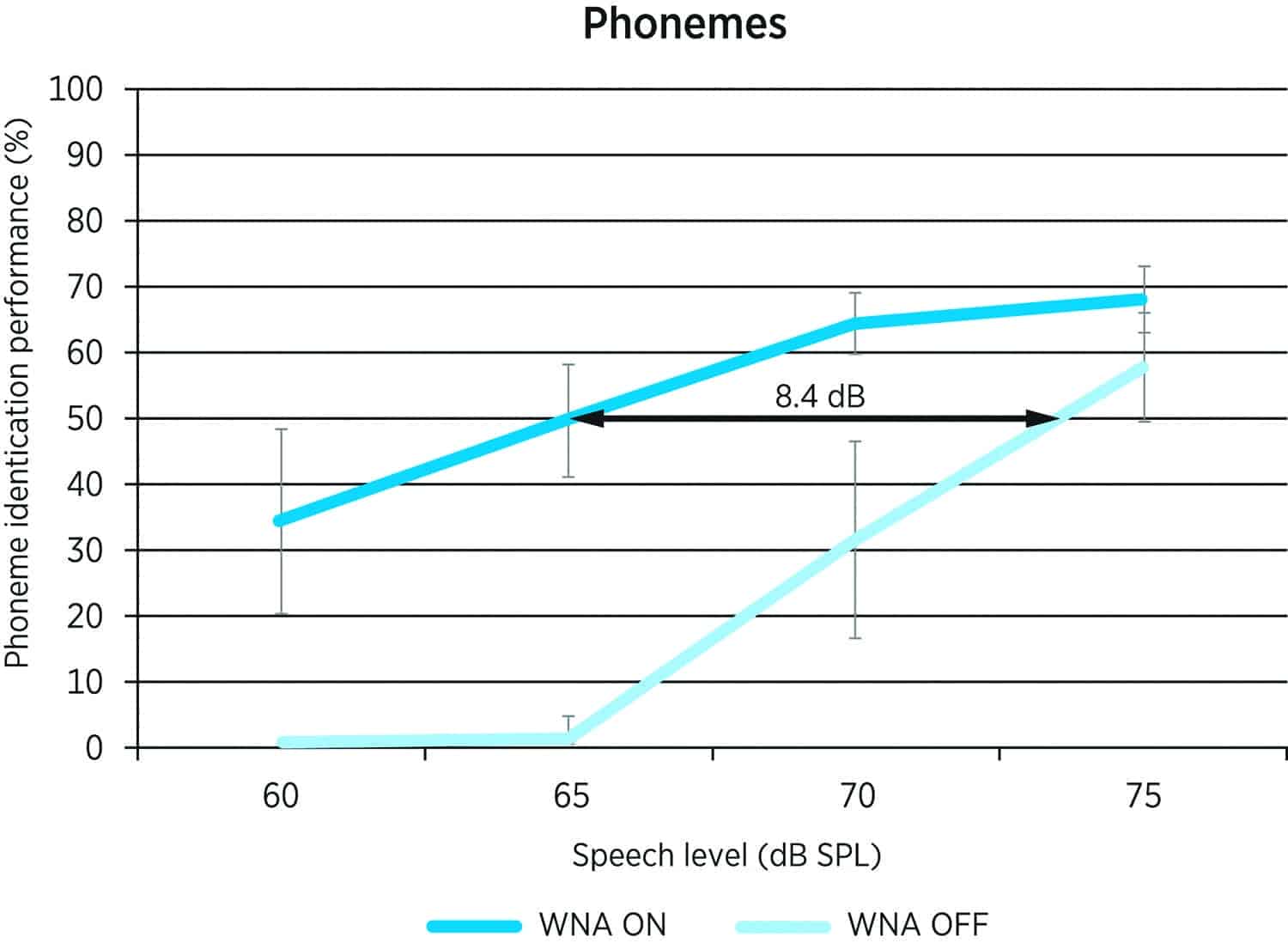
Figure 4. Phoneme identification and signal-to-noise ratio (SNR) improvement provided by the wind noise attenuation algorithm.34
The BEYOND not only inherits all the strategies from previous generations of Widex hearing aids in minimizing wind noise, but also pioneers a new approach to wind noise attenuation. The patented, software based wind-noise attenuation feature consists of two major functional stages: the detection stage (involving wind noise detection and input selection) and the reduction stage (involving an adaptive filter). The detection stage examines a combination of correlation, frequency spectrum, and energy level from the two microphone inputs in the dual microphone directional system to estimate the presence of wind.
The input signals from both microphones are fed to an adaptive Least Mean Square (LMS) filter. One important property of this filter is that it only allows correlated signals to pass through while ignoring the uncorrelated signals. Because wind noise is uncorrelated and speech is correlated at the two microphones, only speech arrives at the output of the LMS filter. The filtered output (which is rid of wind noise) forms the input for the subsequent signal processing (compression and noise reduction). This approach to wind noise attenuation reduces wind annoyance and improves the signal-to-wind noise ratio (SWNR) regardless of wind directions, and can be realized in monaural fittings.
Figure 5. Wind noise annoyance as a function of azimuths between WNA ON and OFF.35
The effectiveness of this algorithm was evaluated at ORCA-USA with wind blowing directly in front at a speed of 5 m/s (as in biking) and speech (nonsense syllables) presented to the left side at levels from 60 to 75 dB SPL in 5 dB increments. Recordings were made from KEMAR in a wind tunnel and a total of 15 subjects were tested under earphones. Figure 4 shows almost 50% improvement in phoneme scores, or an equivalent improvement in SWNR of 8.4 dB using a 50% criterion.34
An independent study was conducted at Eastern Michigan University using the same test conditions and setup on 10 subjects. Similar conclusions were also reached.35 In addition, the study reported similar levels of noise annoyance regardless of wind noise azimuths when the WNA algorithm is activated (Figure 5).
HD Locator
Desirable sounds that are spatially separated from the undesirable sounds can be purified using directional microphones. In the BEYOND, two continuously matched microphones form the HD Locator—a low-frequency compensated, fully adaptive, multichannel directional microphone system to cleanse the incoming signals before subsequent processing. Because a directional microphone has the design objective of removing sounds from azimuths other than the front, Widex has paid special attention to audibility issues so that speech from all directions will not be negatively affected even in the directional mode.33,36
Widex introduced the first fully adaptive directional microphone in the Diva by using two omnidirectional microphones in order to make it possible to switch from an omnidirectional mode to any directional modes.37 In so doing, the signal-to-microphone noise level is improved by 3 dB. In order to preserve the audibility of soft speech presented from the sides and back, the Diva pioneered the use of a moderate directional threshold at 50-55 dB SPL. That is, the Diva would not adapt into a directional mode for any soft sounds presented from the back below this level. This preserves the audibility of soft sounds including speech.38 In addition, low frequency output is compensated (to an omnidirectional mic level) when the hearing aid is in the directional mode to ensure consistent loudness.
In the Inteo, Widex first introduced a 15-channel fully adaptive directional microphone such that each of its 15 independent channels may have its own polar pattern (from omnidirectional to bidirectional and anything in between) depending on the acoustics of the listening environments.39 This has the advantage over a broadband directional microphone or a system with fewer channels (such as 4) in situations where the noise from the sides or back is frequency specific. Pedersen et al40 compared the speech intelligibility difference between a 15-channel and a broadband directional microphone in the presence of a 1000 Hz narrow-band noise. The authors reported almost 10 dB SNR advantage in speech intelligibility of the 15-channel system over the broadband system.
Two other important improvements were made in the Inteo HD locator. First, the directional system is comprised of an omnidirectional microphone as the front microphone and a bipolar microphone as the rear microphone. This has the effect of heightening the sensitivity to noises from the sides for more effective identification and processing by the subsequent noise reduction system. A second enhancement is the implementation of a Speech Detector which detects the presence of speech at the input stage. Any speech sounds, regardless of azimuths and intensity of presentation, keeps the hearing aid in the omnidirectional mode in order to preserve speech audibility. The SNR improvement and acceptable noise level (ANL) offered by the Inteo directional microphone over the omnidirectional microphone condition was estimated at 4 dB and 3 dB respectively.41 Auriemmo et al42 also reported SNR improvements in children. The HD Locator improves speech intelligibility in noise and reduces listening effort.
Widex CLEAR and subsequent models include as part of the HD Locator a Digital Pinna algorithm, which compensates for the loss of pinna shadow with the use of RIC and BTE styles hearing aids. Such compensation restores the front-back localization cues that are lost with the use of these hearing aid styles. Wearers are provided with a more natural input for spatial awareness and ease of listening. Kuk et al43 demonstrated that such an algorithm significantly improved front-back localization.
An optional Reverse Focus program, which allows the wearers to switch into a program with a reverse cardioid directional pattern, is also available since the CLEAR. This allows wearers to hear less of the sounds that come from the front, and more of the sounds that come from the back. A real-life situation where such a program may be helpful is driving while carrying on a conversation with passengers seated in the back. Kuk and Keenan44 showed a SNR improvement of 6 dB with this program in the intended situation. A Free-Focus program, available on the COM-DEX, allows wearers to freely select which directions (front-back-left-right) they want to listen.
The BEYOND maintains all the key characteristics of the HD Locator and more. In the BEYOND, the HD Locator also incorporates adaptive activation times so it responds even more quickly to sudden changes in noise directions when needed. Indeed, the BEYOND HD Locator allows its wearers to sample freely all the relevant acoustic events in their environments and only attenuates when it is needed to minimize the impact of noise. Realizing that elderly hearing-impaired individuals require more effort and may be more easily distracted by other non-target sounds in the listening environments, the HD Locator preserves speech audibility and spatial cues while improving SNRs to minimize distractions. This promotes effortless hearing/listening.
BEYOND PROCESSING
Sounds after the input stage are processed by various signal processing algorithms to minimize the impact of sounds that cannot be purified. These same algorithms can enhance the level of desirable sounds individually so that listening is as effortless as possible.
The individualization process starts at the very first step in the fitting process where the in-situ hearing thresholds, or sensogram,45 and feedback test46 are conducted. These two processes measure the individuals’ hearing loss while considering the effects of their ear canals and vent characteristics on the “true” hearing loss (or equivalent adult thresholds) and optimal gain settings on the hearing aids. This individualization process continues through the processing chain and can be seen in all the key areas of processing—enhancing audibility and temporal cues, minimizing the impact of noise, enhancing audibility of high frequency cues (HF boost + AE), and contributing to full automaticity. Examples of individualization to meet the wearer’s needs in each area are highlighted below.
Enhancing Audibility and Temporal Cues
Variable Speed Compressor. The compressor is the core processing unit of modern hearing aids, and its parameters must be selected carefully. At a fundamental level, appropriate gain should be applied to frequencies where hearing is deficient (ie, individual hearing loss compensation). This is ensured through the determination of in-situ thresholds (ie, sensogram). In addition, such programming changes must also account for the individual differences with changes in acoustic environments. While all compression parameters are important, we will focus on two: compression thresholds (CT) and compression speed (or time constants), and review how they could affect effortless hearing.
Compression thresholds. Since the introduction of the SENSO, the first in-the-canal digital hearing aid, Widex has used a very low CT of 20 dB HL.47 It was further lowered to 0 dB HL (when possible) when the Diva was introduced in 2001. The advantage of a low CT is that it provides extra gain to low input sounds, and assures the consistent audibility for soft speech.48 For example, this could involve listening in a quiet place, or understanding speakers/languages that “fall off” in amplitude towards the end of a sentence.49 In a recent field study, wearers rated the UNIQUE hearing aids an average of 2 intervals (on a 7-interval scale, from “4 or neutral” to “6 or satisfied”) higher than their own hearing aids on understanding soft speech!50 Due to these processing strategies, extra audibility for soft sounds has been a hallmark feature of Widex hearing aids.
Time constants (or speed of compression). Compression speed (time constants) has received renewed attention recently. A fast time constant ensures audibility, but at the expense of distorting the temporal and spectral contrasts of the input signals. A longer time constant has the advantage of maintaining the linearity (or temporal nuances) of the input signal.51
Souza52 also reported that longer time constants have the advantages of speech intelligibility and sound quality, especially for individuals with cognitive challenges. Unfortunately, there may be times when a fixed long time constant may not be able to follow fast intensity changes, resulting in a loss of audibility. It has been suggested that hearing aids with different time constants should be used for people with different working memories.53
Widex recognizes the importance of the temporal structures, not just for people with a poor working memory, but also for people with a good working memory. Due to this belief, Widex has been advocating the use of slow-acting compression since the SENSO to preserve the temporal envelope of the input sounds. This, in turn, achieves a natural sound quality to benefit people of all cognitive backgrounds.
Widex recognizes the importance of the temporal structures, not just for people with a poor working memory, but also for people with a good working memory. Due to this belief, Widex has been advocating the use of slow-acting compression since the SENSO to preserve the temporal envelope of the input sounds.47 This, in turn, achieves a natural sound quality to benefit people of all cognitive backgrounds. Adaptive release time (called Sound Stabilizer since the Diva) and transient noise reduction algorithm (called Sound Softener since the CLEAR54) are included to provide primarily slow-acting compression at most times, but fast-acting compression with sudden changes in the environments. In this way, audibility and listening comfort are maintained while preserving as much of the temporal envelope as possible.
The BEYOND hearing aid advances the concept of adaptive compression by using two (or dual) compressors working in parallel to achieve the benefits of slow-acting compression and fast-acting compression in the same hearing aid. The primary compressor uses long time constants. It forms the main compressor of the hearing aid, as it adjusts the overall loudness of the input while preserving its temporal waveforms. The secondary compressor uses a shorter time constant as it follows the rapid short-term dynamics of the inputs. A Jump system is also used to facilitate smooth gain change with sudden changes in input levels. Figure 6 is a schematic of this dual compressor system.
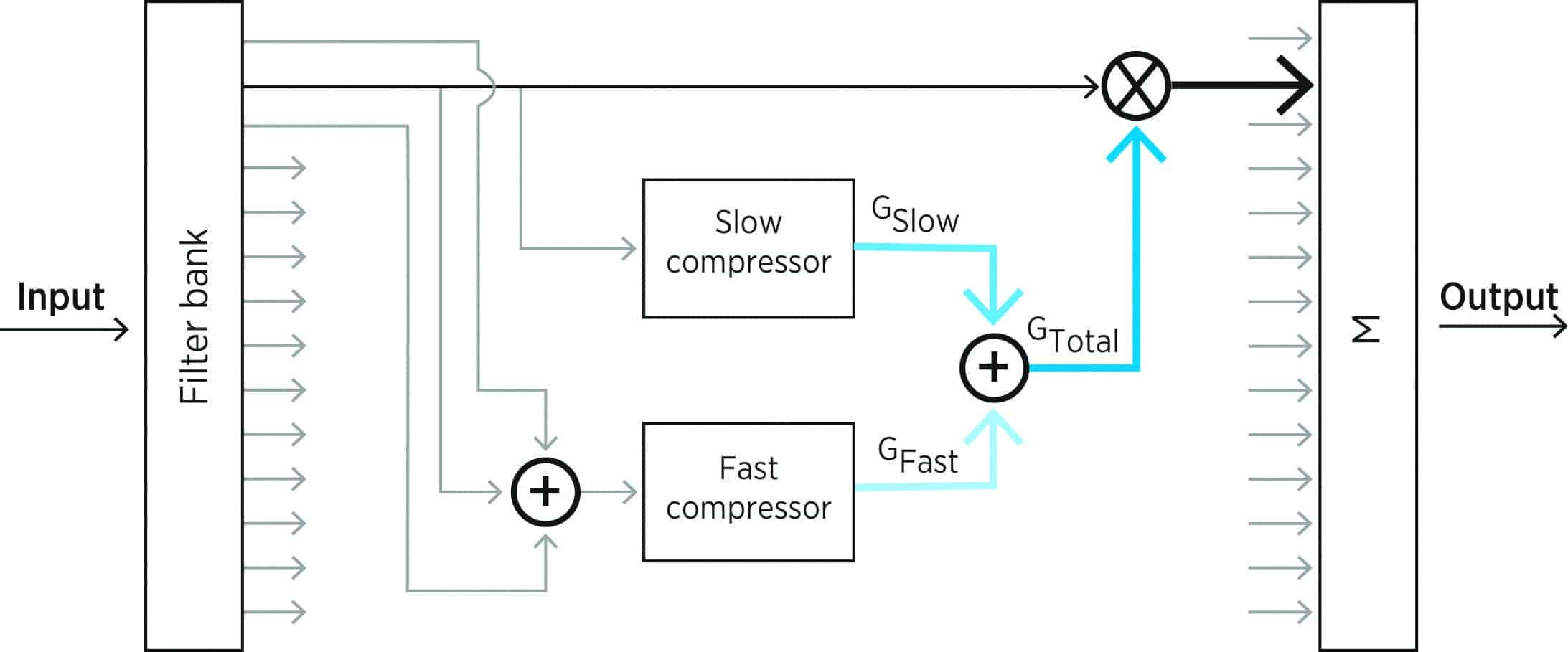
Figure 6: Schematic of the BEYOND variable speed compressor.
The advantage of a dual compressor with variable speeds is that it is more responsive to sudden input level changes than a single compressor, even one with an adaptive speed, in dynamic situations. Such responsiveness would ensure the audibility of a soft sound when it follows a loud sound. This allows more consistent audibility and requires less listener effort to identify the sounds. The opposite is true when the compressors are presented with a soft sound (50 dB SPL) followed by a loud sound (80 dB SPL). This provides more comfort to the listener and promotes greater acceptance as well.
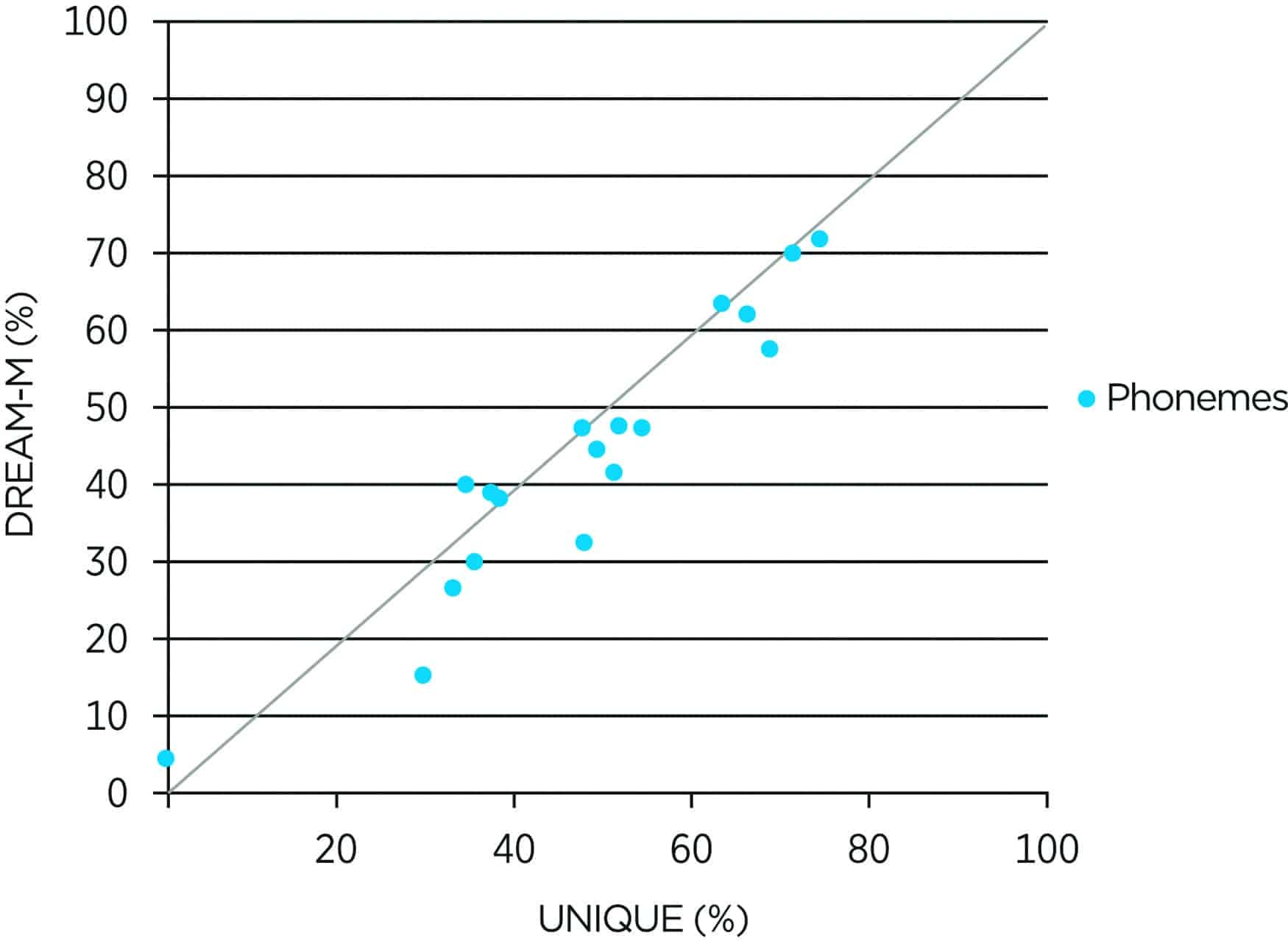
Figure 7: Scatterplot comparing the performance of the UNIQUE and the DREAM (matched gain) for soft speech following loud speech.
A study was conducted at ORCA-USA to examine if the increased responsiveness from the use of the Variable Speed Compressor may surpass the performance of the adaptive compression (Sound Stabilizer) used in the DREAM. Nonsense syllables in the ORCA-NST list were used. The carrier phrase “Please say the word…” was presented at 80 dB SPL followed by the target syllable at 50 dB SPL in quiet. Figure 7 shows, for most of the subjects, performance with the UNIQUE was better than the DREAM by an average of 5% points.
The BEYOND includes several controls to minimize the potential negative impact of using fast compression. First, fast-acting compression is applied only in the “quiet” or high SNR situations where high modulation is expected. This results in minimal impact on the temporal envelope. Secondly, the BEYOND compressor integrates the action of the adjacent bands in its fast-acting compression action. This minimizes any potential smearing, and ensures good sound quality and consistent speech audibility. Thirdly, because people with a more severe hearing loss rely more on the temporal envelope cues than people with a milder loss, fast-acting compression is not utilized for those with hearing losses greater than 75 dB HL and at high compression ratios.
The Variable Speed Compressor used in the BEYOND preserves the temporal envelopes without sacrificing audibility. For people with good working memory who would benefit from the extra audibility cues, they will receive the same audibility as in a fixed fast compression, but the sound quality could be improved from the preservation of the temporal envelope. For people with a poor working memory, the preserved temporal envelope helps in their speech understanding. The extra audibility cues may even provide extra benefit to these individuals. Thus, the use of a dual compressor system is a potentially good solution to the varying cognitive constraints of hearing-impaired listeners.
The BEYOND uses algorithms such as the Digital Pinna to preserve the front/back localization cues. The use of inter-ear compression allows two hearing aids of a bilateral pair to exchange input information (at 21 times per second in each of the 15 channels) and preserve the inter-aural level difference (ILD) cues.
Preservation of inter-aural cues. The central auditory system uses input from both ears to form spatial judgment, such as spatial awareness, localization, distance estimation, etc. The use of independent fast-acting compression in each ear could disrupt the loudness relationship of sounds between ears (IID cues). This could alter the spatial relationship of sounds and lead to poorer spatial performance. The BEYOND uses algorithms such as the Digital Pinna (introduced since the CLEAR) to preserve the front/back localization cues.43 The use of inter-ear compression since the CLEAR allows two hearing aids of a bilateral pair to exchange input information (at 21 times per second in each of the 15 channels) and preserve the inter-aural level difference (ILD) cues.55
Minimizing the Impact of Noise
Noises that are not spatially and/or spectrally separated from desirable sounds cannot be removed at the input stage. These situations would require separate post-input processing based on certain assumptions of “speech” and “noise” characteristics. The BEYOND manages noise differently based on their input levels.
Soft Level Noise Reduction (SLNR). The internal noise from a hearing aid originates from its analog input stage and the ADC. Soft noises from the environment—such as fan noise, refrigerator, etc—also become more noticeable from the amplification provided by hearing aids. While greater gain for soft sounds is desirable for consistent speech intelligibility48 and for patients with tinnitus,56 it may not be appreciated by people who have a milder hearing loss or new hearing aid wearers because of their relatively good hearing thresholds in the low frequencies. The soft level noise reduction (SLNR) algorithm is designed so BEYOND wearers may hear less soft noises (ie, increased comfort and reduced distractions) without affecting soft speech.
The design rationale behind the SLNR is that speech and non-speech (noise) signals have different temporal characteristics. By utilizing a new speech detector in the BEYOND hearing aid, sounds below 62 dB SPL are classified into speech sounds and non-speech sounds. Gain for speech sounds is maintained, whereas gain for non-speech sounds is reduced.
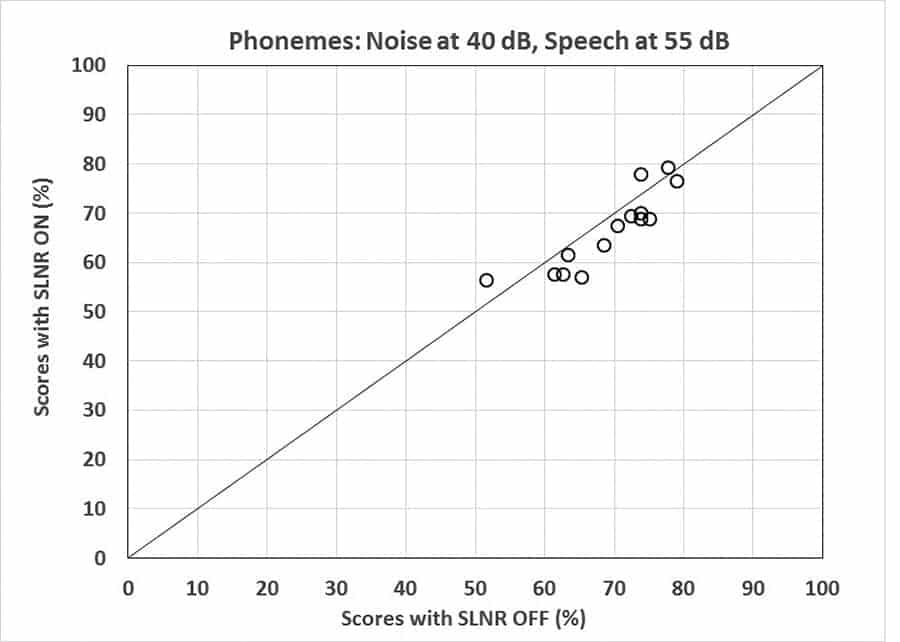
Figure 8. Scatter plot comparing speech intelligibility between the SLNR ON and OFF for soft speech presented in low level noise.
A study conducted at ORCA-USA using the ORCA-NST word list confirms that the feature maintains intelligibility of soft speech presented in the presence of fan noise (40 dB SPL) while minimizing the perception of the fan noise (Figure 8). This suggests consistent speech audibility without the burden of soft noises. This could be especially beneficial for people with a mild hearing loss or first time wearers.
Real-Time Speech Enhancer (RTSE). Noises that are at or above a conversational level are managed by noise reduction algorithms. Special considerations are needed in designing these noise reduction algorithms so that useful speech cues are preserved (if not enhanced) and the sound quality would not experience artifacts like musical noise (which occurs when the speed of noise reduction is too fast).57,58
The classic noise reduction algorithm introduced since the SENSO uses the difference in percentile distribution to distinguish between speech and noise in each frequency channel, and applies Wiener filtering to reduce gain in the specific channels where noise is detected. While this improves listening comfort, it ignores the individual’s hearing loss configuration and has the potential to reduce important speech cues.
Widex introduced the patented Speech Enhancer (SE) in 2006 to optimize and individualize speech audibility in noise for all hearing loss configurations. The SE optimizes speech intelligibility index (SII) by considering the configuration of the wearer’s hearing loss and the spectra of the noise environments during its gain adjustment.59 In addition, it provides gain increases in the mid-frequency regions when desirable and permitted. The SE has demonstrated a SNR improvement of 2 dB and an improvement in Acceptable Noise Level (ANL) by 3 dB in an omnidirectional mode.60 This benefit was confirmed in a subsequent study.61 Auriemmo et al42 also reported benefit of the SE in school-age children.
The use of wireless connectivity in the CLEAR enables the use of the inter-ear speech enhancer. In this mode, the hearing aid to the side of a speaker receives gain increases in mid-frequencies and gain reduction in noise frequencies, while the hearing aid to the side of the noise undergoes gain decreases only. This action enhances the audibility of speech in a noisy situation where speech is located on one side.
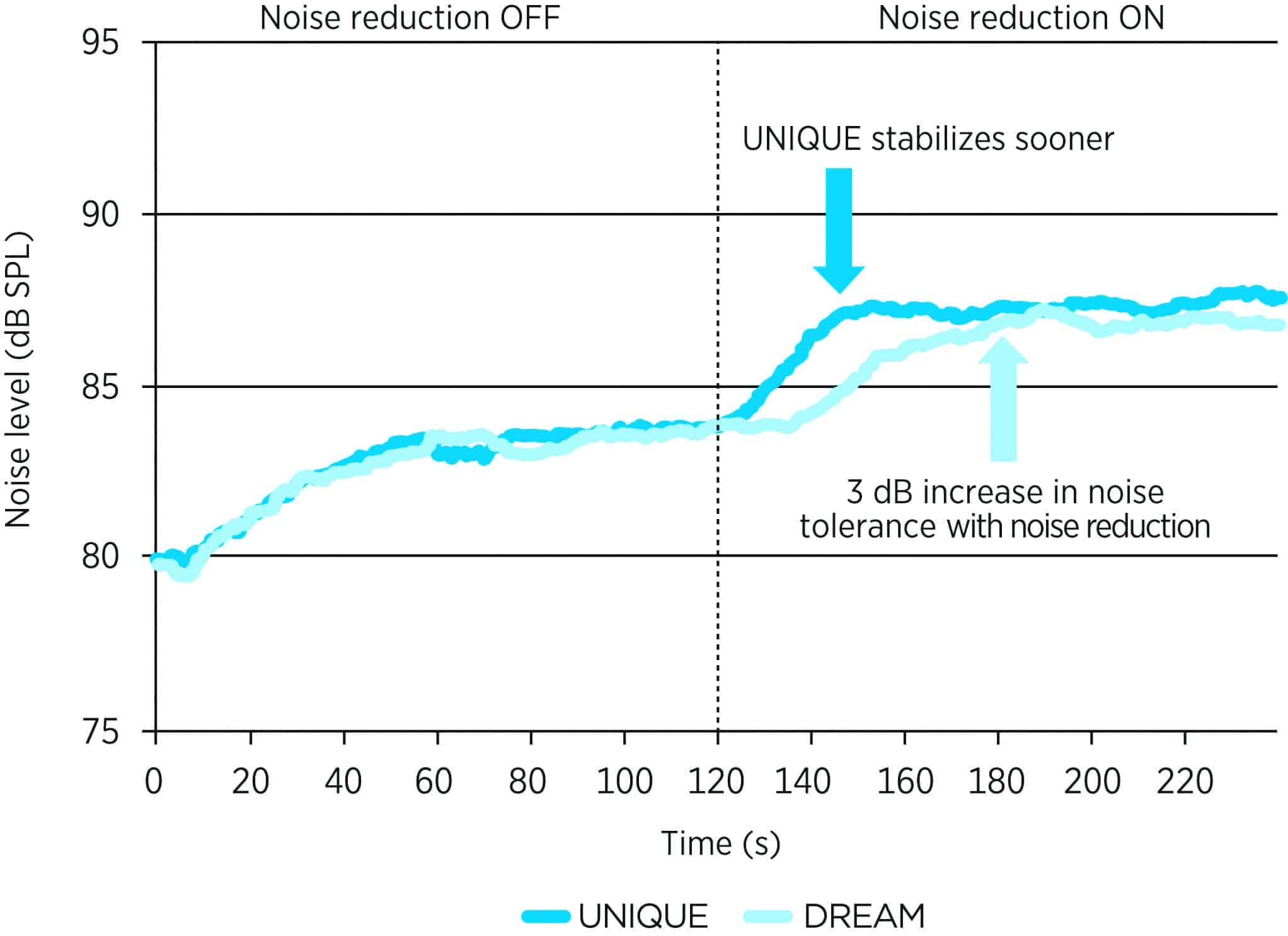
Figure 9: Comparison of tracking of tolerable noise between the UNIQUE (dark blue) and the DREAM (light blue) hearing aids. The first 120s was completed with SE Off; while the remaining 120s was completed with SE (or RTSE) On.
The RTSE system in the BEYOND advances the SE in two ways. First is the use of a much quicker speech detection and gain algorithm without artifacts (< 5 s). In a test where subjects at ORCA-USA tracked the level of a tolerable noise while maintaining speech intelligibility, Kuk et al62 showed that the RTSE provided about 3 dB improvement in noise tolerance over the no-RTSE condition. More importantly, subjects with the RTSE were able to reach the increased noise level sooner (25 s vs 50 s) than the SE used in the DREAM hearing aid (Figure 9). This improved responsiveness is especially advantageous over other NR systems in environments where the noise characteristics change rapidly and unpredictably. When the SE is used as part of the BEYOND Sound Class system (SCT), it would also change its objective from maximizing speech intelligibility in noise when speech is dominant to maximizing comfort as the noise intensity increases above the speech signal.
A second enhancement of the BEYOND RTSE is that the effect of vent diameter, as assessed through the AISA evaluation during the feedback test (Assessment of In-Situ Acoustics or AISA)63 is integrated into the noise reduction algorithm. In this process, the individual vent effect on the output of the hearing aid is considered, and adjustment is made on the amount of gain reduction. An internal study at ORCA-USA demonstrated that, in an open-fitting, subjects showed a 2 dB SNR advantage with the UNIQUE hearing aid over the DREAM hearing aid on a speech-in-noise task under a matched gain condition.
Enhancing Audibility of High Frequency Cues
Widex recognizes that hearing aids with a broad bandwidth result in better sound quality64 and speech intelligibility in noise.60 However, such an outcome is likely dependent on the severity of the high frequency hearing loss. People with less than a moderately severe hearing loss in the high frequencies (<70 dB HL) would likely benefit from the direct amplification of high frequency sounds65 when such sounds can be provided by the hearing aids. On the other hand, those with greater than a severe hearing loss in the high frequencies may receive less benefit from direct amplification because of potential dead regions.66 Widex BEYOND provides unique solutions for listeners falling into each of these two categories. Both solutions increase audibility and comfort of high frequency sounds while minimizing listening effort.

Figure 10: Comparison of the input-output curves at 6000 Hz between the BEYOND high-frequency boost feature On (dark blue) and Off (light blue).
High Frequency Boost (HFB). The HFB feature in the BEYOND offers extra audibility and more comfort for sounds above 4000 Hz to people with less than a severe loss in the high frequencies. Figure 10 shows the in-situ input-output curves at 6000 Hz between the HFB On (dark blue) and Off (light blue) for a 60 dB hearing loss. One can see that the I-O for the HFB On provides more output than the HFB Off below an input level of 80 dB HL. The predicted aided threshold is 25 dB HL for the HFB On and 45 dB HL for the HFB Off. The lower and relatively constant output from the HFB On compared to Off above the 80 dB HL input means that the more intense high frequency sounds remain comfortably loud even when the input increases. This ensures consistent audibility for speech understanding and music appreciation at a comfortable level.
Enhanced Audibility Extender (AE). Amplification for hearing losses that result from a complete loss of inner hair cells or “dead” regions can result in a distorted perception and a decrease in speech understanding.66 In those cases, the use of frequency transposition may be beneficial. Widex introduced the Audibility Extender (AE) in 2006 as a means to provide the information embedded in the high frequencies to the lower frequencies.67 In the AE, high frequency sounds above an individual-specific start frequency are transposed one octave lower and mixed with the original signals. Efficacy studies of the AE feature were reported in children68 and adults.69 Over a dozen publications covering the topics from how to verify AE fitting70 to the importance of training71 are available.
The AE on the BEYOND is designed to improve wearer acceptance by requiring even less listening effort from its wearers. It is reasoned that the transposed sounds may be unnatural to some wearers such that additional explicit processing is needed. While the additional processing may not be problematic for individuals with a good working memory, those with a poorer working memory may need to spend extra effort to decode the transposed sounds. To increase the success of frequency transposition, one may preserve as much of the original input as possible, and allow individualization of the settings so all wearers are more likely to accept the new sound and improve their hearing aid satisfaction.
To achieve these two objectives, a new rationale for selecting the start frequency (or transposition region) is used. The new speech detector is also utilized in the AE to distinguish between voiced and unvoiced sounds in the source region. Voiced speech sounds are attenuated before transposition so they are audible but not distracting. Voiceless speech sounds, such as voiceless fricatives (like /s/), are transposed without attenuation to add saliency. Additionally, a new harmonic tracking system is used in the enhanced AE to ensure proper alignment of the harmonics between the source and target signals. These additions are designed to result in a transposed sound that is more naturally perceived.
While the original AE only transposes the source region to the target region (and leaving the source region not amplified), the new AE allows clinicians to also amplify the source region during transposition. In contrast to approaches where the whole source region is amplified, the BEYOND allows the clinician to vary the bandwidth of the amplified source region so that dead regions are not amplified. This individualizes the amplification/transposition characteristics more closely to the etiology of the person’s hearing loss. The feature also ensures the naturalness of the transposed sounds, and increases acceptance and reduces listening effort.
Finally, a new acclimatization program, whereby gain provided by the AE is gradually increased over a 12-day period is also available. This allows the wearers to acclimate to the transposed sounds instead of forcing them to accept the transposed sounds at once. These new features are designed to ensure more immediate acceptance and satisfactory use of the AE.
Towards Full Automaticity
While adaptive features on a hearing aid, such as directional microphones, compressors, and noise reduction algorithms adapt their processing to the acoustics of the environments (eg, levels, SNR), the adaptation may not be sufficient to result in the best sound quality.
Some prime examples may be listening to music and in noisy conditions. Traditionally, these acoustic situations have been satisfied using dedicated listening programs (such as music and party) to enhance sound appreciation and listening comfort in these special situations. While wearers can select and use these programs manually, it can be effortful for two reasons. First, the wearers need to know the nature of their listening environments so they can select the right listening program. Secondly, the wearers have to switch to the right program. It is desirable that hearing aids can analyze the acoustic environments and automatically adjust the parameters to the most appropriate settings without the need of wearer manipulation. An automatic sound classification and processing system could meet this need.
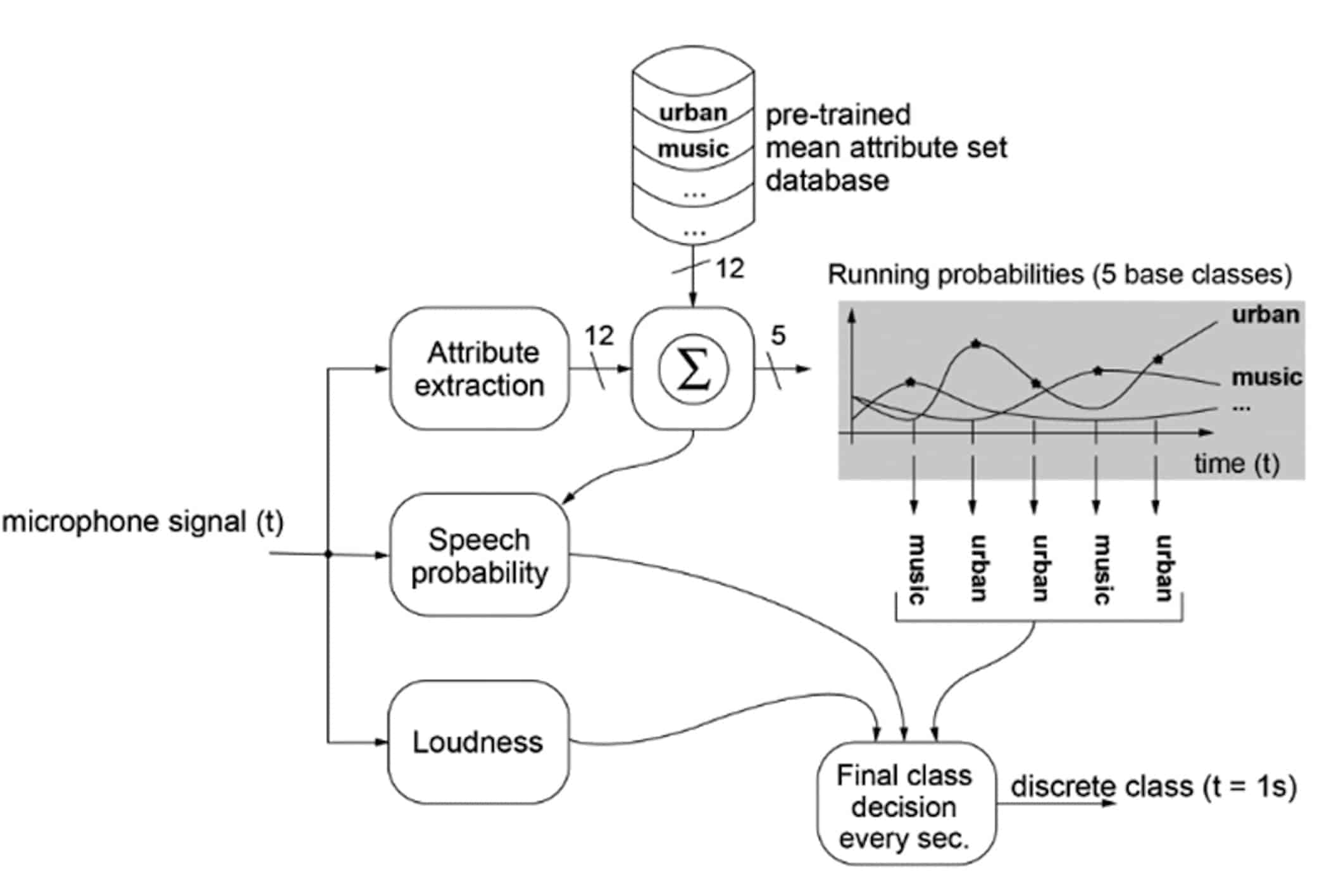
Figure 11. The classification process. A probability estimate is used to determine the current class.
New Sound Class Technology. The new Sound Class Technology (SCT) used in the BEYOND is intended to provide automatically more optimal settings based on the acoustic characteristics of the listening environments (Figure 11).
The SCT has two components: a classifier and a controller. In the classifier, the input signal is analyzed on 12 attributes (eg, envelope modulation, amplitude modulation, etc). These attributes are compared to a class library (or database) consisting of a discrete number of sound-base classes. These classes are derived based on machine training (and subsequent real-life validation) of real-life bilateral recordings of over a hundred different situations that hearing aid users typically encounter.
A running estimate of the correlation between each of the pre-trained base-class and the current set of attributes is performed. A separate speech detector is also available to estimate the presence of speech. The sound class that shows the highest probability of explaining the sound attributes is chosen as the current base-class.
Nine different sound classes are defined through this training process. They include 5 where speech is absent:
1) Quiet;
2) Urban noise;
3) Transportation noise;
4) Party noise and
5) Music
There are also 4 sound classes where speech is present:
6) Quiet speech;
7) Urban with speech;
8) Party with speech, and
9) Transportation with speech.
The classifier provides output in the form of a discrete class every second. When the hearing aids are turned on, they start in the “quiet” class. The classifier requires the identification of a new class 3 seconds in a row for a shift to be implemented. Once a decision is made on a sound class, the range of parameter settings from the previous sound class is updated automatically to optimize for the new environment. This is achieved via the controller of the SCT. This could include the various parameters, such as the amount of impulse sound reduction (sound softener), the amount of soft-level noise reduction, the speed of the Speech Enhancer, etc. Such changes can be individualized for quick or gradual implementation, and the types of parametric changes are illustrated in Figure 12.
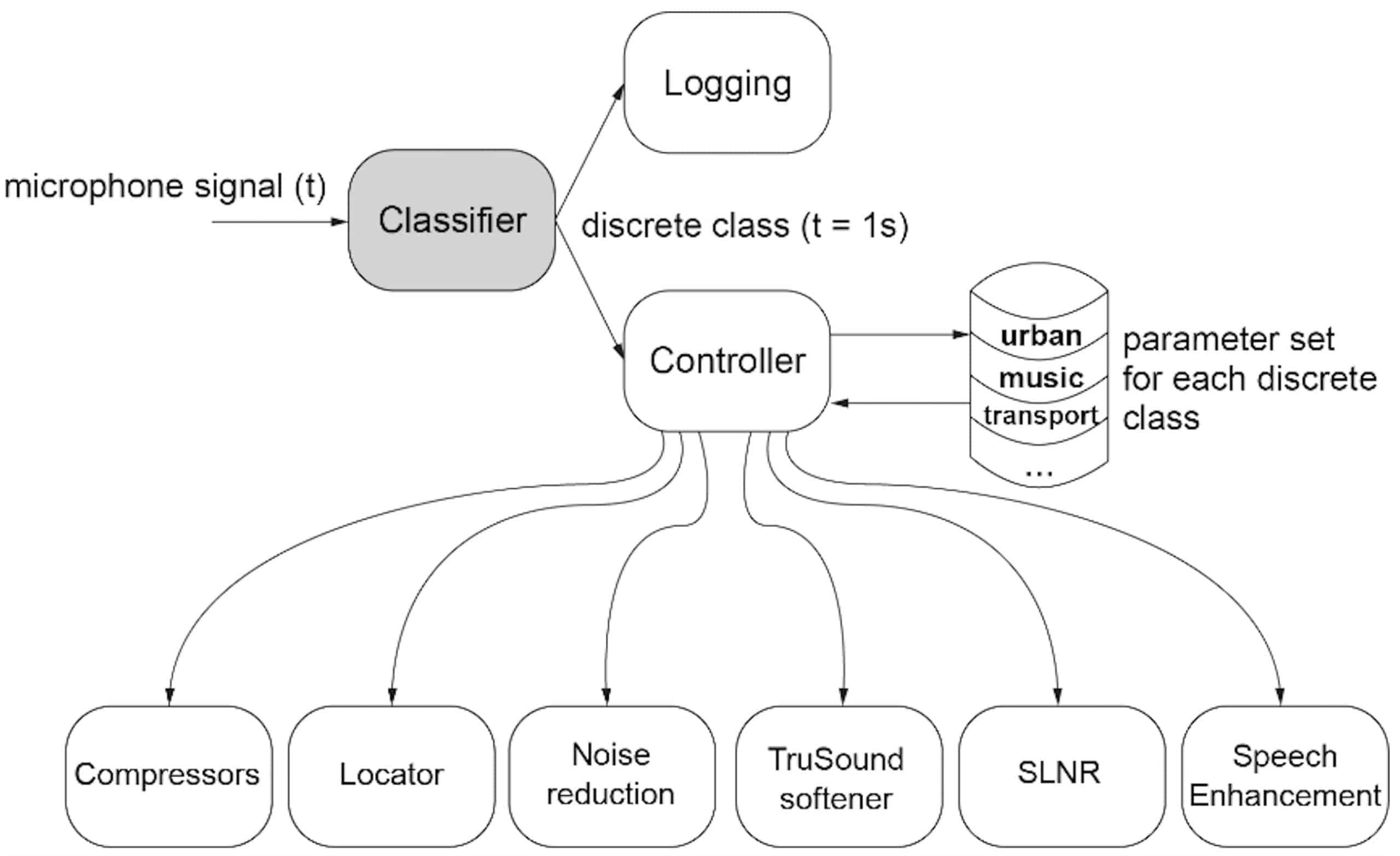
Figure 12: The controller adjusts parameters of the various features on the BEYOND hearing aid to optimize the settings for the specific environment (or sound class).
While the SCT allows automatic treatment of sounds in various acoustic environments, some hearing aid users may desire more audibility in a party noise situation, while others may prefer more listening comfort in the same environment. To allow for individual preferences, the fitting software (Compass GPS) offers individual tailoring of audibility vs comfort for the overall program and for each sound class. That is, for the same listening environment, the processing may be tailored to be more audibility-oriented or more comfort-oriented.
In addition, a Preference Control (PC)—accessible via a toggle switch on the hearing aid, the remote control (RC-DEX), or a smartphone app with the COM-DEX—is made available for wearers to adjust for more audibility or more comfort on demand. The PC individualizes each feature settings (such as directional microphone and noise reduction settings) for optimal satisfaction across situations. A study at ORCA-USA shows improved wearer performance on speech intelligibility and listening comfort with the use of the PC. This highlights the importance of allowance for individualization in the design of Effortless Hearing.
BEYOND SATISFACTION

Figure 13: Comparison in satisfaction ratings between the UNIQUE and wearers’ own aids on various aspects of sound quality.
Wearer satisfaction for the BEYOND may be predicted from the satisfaction listeners reported for the UNIQUE hearing aids since both hearing aids are based on the same U-platform. The main advantage of the BEYOND over the UNIQUE is the availability of the Pure-link 2.4 GHz wireless streaming platform.
In an international field study,50 101 experienced hearing aid wearers compared the UNIQUE hearing aids to their own hearing aids using a modified version of the MarkeTrak questionnaire. The results shown in Figure 13, which compares the median user preference between the UNIQUE and their own hearing aids across various listening scenarios, demonstrate overwhelming preference for the UNIQUE. Participants gave a median rating of “6” (satisfied) for the UNIQUE and “5” (relatively satisfied) for their own hearing aids.
Likewise, Figure 14 shows that satisfaction with the UNIQUE is higher than the listeners’ own hearing aids in almost all categories on sound quality, sound processing features, and multiple listening environments. The benefit of the UNIQUE was especially noted in the following situations, where a difference of 2 or more intervals were noted (out of a 7-point scale):
- Soft sounds;
- Children;
- Restaurants;
- Windy outdoors, and
- Walking outdoors.
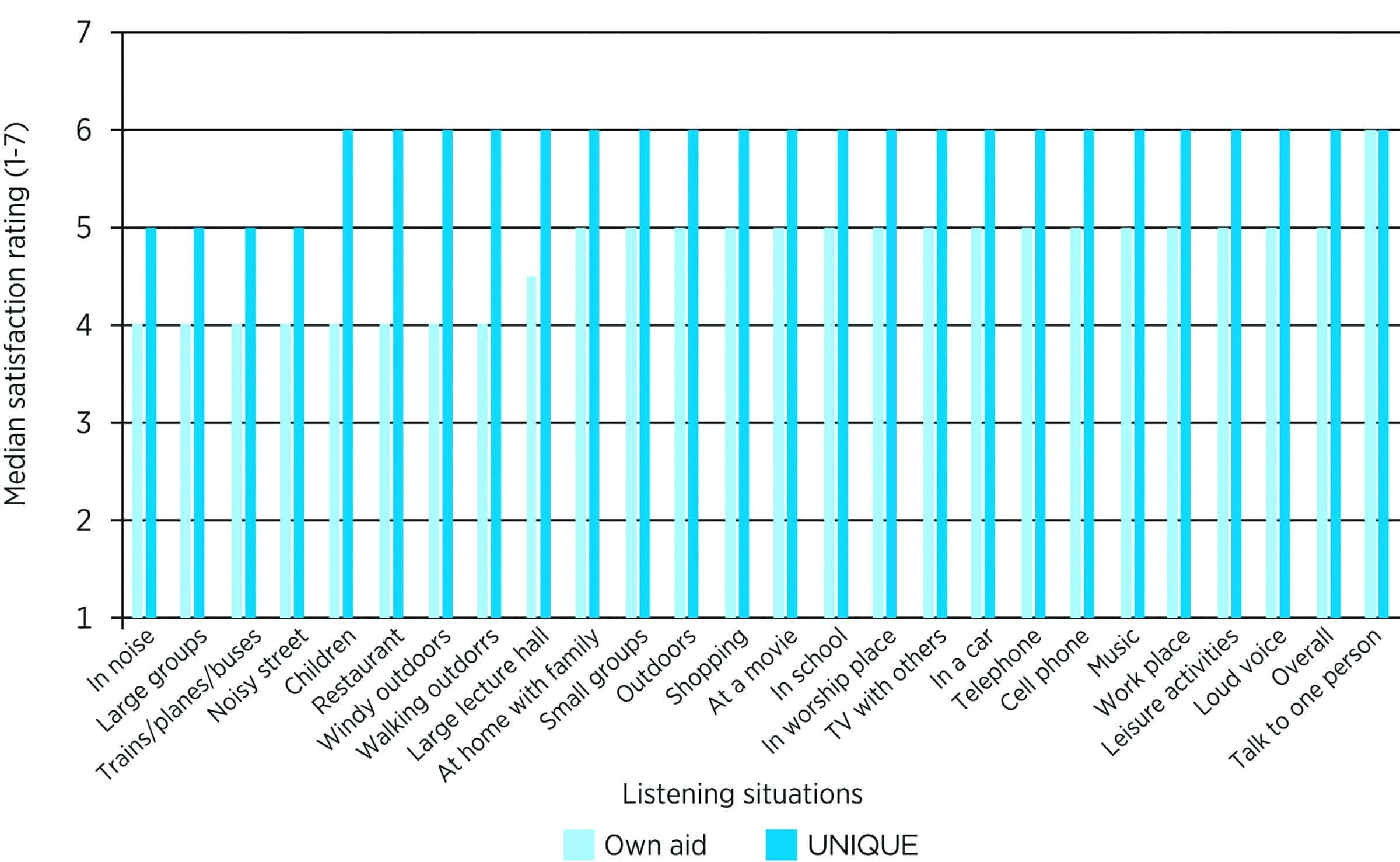
Figure 14: Comparison in satisfaction ratings between the UNIQUE and wearers’ own aids in various listening environments.
The ability to hear “soft sounds” and “children” better is likely related to the low compression threshold that is used in all Widex aids. In the UNIQUE/BEYOND, this is enhanced with the Soft Level Noise Reduction algorithm and the High Frequency Boost feature. The former distinguishes between soft speech and soft noise so only soft speech is amplified. The latter provides additional amplification to low and medium sounds in the high frequency region so better intelligibility can be expected.
An additional feature that provides consistent audibility to soft speech is the Variable Speed Compressor. This algorithm preserves the temporal structures of the input sounds while maintaining consistent audibility even with large changes in the input intensities (ie, from loud to soft and vice versa). Consistent audibility and natural temporal structures are important for all listeners, but especially those with poor cognition.
The ability to function better in “restaurants” is likely due to the real-time Speech Enhancer, the HD Locator, and the True Input Technology. In addition to these proven features, the UNIQUE/BEYOND also uses the automatic Sound Class Technology system to detect the identity of each listening environment to further augment and coordinate the actions of each individual feature in all listening environments. The result is an ever-changing set of hearing aid parameters that is optimized to provide the best available signal-to-noise ratio of the input sounds for speech understanding.
The Wind Noise Attenuation algorithm is undoubtedly the main reason for the improved satisfaction in the “windy outdoors” and “walking/running outdoors” situations. The effective use of hearing aids is extended from just the indoors to both indoors and outdoors with the UNIQUE. We expect the BEYOND to go beyond those and include situations that involve wireless transmission through the 2.4 GHz carrier frequency.
Under this rationale, Widex strives to reduce the input demands on the listeners by providing the most natural, useful, and audible sounds in both indoor and outdoor listening environments. Widex believes this encourages successful communication for people of all cognitive backgrounds in diverse listening situations. In keeping with Widex’s tradition, our current success motivates us to be even more innovative in our future solutions while following the Effortless Hearing design rationale.
The remarkable satisfaction seen in the UNIQUE over the subjects’ own hearing aids is a testament to the efficacy of the Effortless Hearing design rationale. Under this rationale, Widex strives to reduce the input demands on the listeners by providing the most natural, useful, and audible sounds in both indoor and outdoor listening environments. Widex believes this encourages successful communication for people of all cognitive backgrounds in diverse listening situations. In keeping with Widex’s tradition, our current success motivates us to be even more innovative in our future solutions while following the Effortless Hearing design rationale.
References
-
Winn M. Rapid reduction of listening effort resulting from predictive speech processing and delays associated with cochlear implantation. Poster presented at the American Auditory Society, Scottsdale, AZ; March 3, 2016.
-
Kuk F, Schmidt E, Jessen A, Sonne M. New technology for effortless hearing: A “Unique” perspective. Hearing Review. 2015;22(11): 32-36.
-
Bregman A. Auditory Scene Analysis: The Perceptual Organization of Sound. Cambridge, Mass: MIT Press;1990.
-
Tremblay K, Backer K. Listening and learning: cognitive contributions to the rehabilitation of older adults with and without audiometrically defined hearing loss. Ear Hear. 2016;37[Suppl 1]:155S-162S.
-
Harada C, Natelson Love M, Triebel K. Normal cognitive aging. Clin Geriatr Med. 2013;29(4):737-752.
-
Raz N, Gunning F, Head D, et al. Selective aging of the human cerebral cortex observed in vivo: differential vulnerability of the prefrontal gray matter. Cereb Cortex. 1997;7(3):268-282.
-
Salat D, Kaye J, Janowsky J. Prefrontal gray and white matter volumes in healthy aging and Alzheimer disease. Arch Neurol. 1999;56(3):338-344.
-
Resnick S, Pham D, Kraut M, et al. Longitudinal magnetic resonance imaging studies of older adults: a shrinking brain. J Neurosci. 2003;23, 3295-3301.
-
Terry R, Katzman R. Life span and synapses: will there be a primary senile dementia? Neurobiol Aging. 2001;22(3):347-354.
-
Salthouse T. Selective review of cognitive aging. J Int Neuropsychol Soc. 2010;16(5):754-760.
-
Vaden K. Jr, Kuchinsky S, Cute S, et al. The cingulo-opercular network provides word recognition benefit. J Neurosci. 2013;33:18979-18986.
-
Davis S, Dennis N, Daselaar S, et al. Que PASA? The posterior-anterior shift in aging. Cereb Cortex. 2008;18:1201-1209.
-
Kujawa S, Liberman M. Adding insult to injury: cochlear nerve degeneration after “temporary” noise-induced hearing loss. J Neurosc. 2009;29(45):14077-14085.
-
Willott J. Aging and the Auditory System: Anatomy, Physiology, and Psychophysics. San Diego: Singular Publishing;1991.
-
Eckert M, Cute S, Vaden K, Jr, et al. Auditory cortex signs of age-related hearing loss. J Assoc Res Otolaryngolol. 2012;13:703-713.
-
Bharadwaj H, Verhulst S, Shaheen L, et al. Cochlear neuropathy and the coding of supra-threshold sound. Front Syst Neurosci. 2014;8:26.
-
Moore B. The role of temporal fine structure processing in pitch perception, masking, and speech perception for normal hearing and hearing impaired people. J Assoc Res Otolaryngol. 2008;9:399-406.
-
Besser J, Koelewijin T, Zekveld A, et al. How linguistic closure and verbal working memory relate to speech recognition in noise. A review. Trend Amplif. 2013;17:75-93.
-
Rudner M, Lunner T. Cognitive spare capacity as a window on hearing aid benefit. Sem Hear. 2013;34:298-307.
-
Daneman M, Carpenter P. Individual differences in working memory and reading. J Verbal Learning Verbal Behavior. 1980;19:450-466.
-
Ronnberg J, Lunner T, Zekveld A, et al. The Ease of Language Understanding (EDU) model: Theoretical, empirical, and clinical advances. Front Syst Neurosci. 2013;7:31.
-
Edwards B. A model of auditory-cognitive processing and relevance to clinical applicability. Ear Hear. 2016;37[Suppl 1]:85S-91S.
-
Kuk F, Korhonen P, Crose B, Kyhn T, Mørkebjerg M, Rank M, Kidmose P, Jensen M, Larsen S, Ungstrup M. Digital wireless hearing aids: Part II: Considerations in developing a new wireless platform. Hearing Review. 2011;18(6):46-53.
-
Chasin M. Music and hearing aids. Hearing Review. 2003;56(7):36-41.
-
Kuk F, Lau C, Korhonen P, Crose B. Evaluating hearing aid processing at high and very high input levels. Hearing Review. 2014;21(3): 32-37.
-
Kuk F, Lau C, Korhonen P, Crose B. Speech intelligibility benefits of hearing aids at various input levels. J Am Acad Audiol. 2015;26(3):275-288.
-
Oeding K, Valente M. The effect of a high upper input limiting level on word recognition in noise, sound quality preferences, and subjective ratings of real-world performance. J Am Acad Audiol. 2015;26(6):547-562.
-
Chasin M. A hearing aid solution for music. Hearing Review. 2014;21(1): 28-32.
-
Blauert J. Spatial Hearing: The Psychophysics of Human Sound Localization. Cambridge, Mass:The MIT Press;1997.
-
Kuk F, Crose B, Kyhn T, Mørkebjerg M, Rank M, Nørgaard M, Föh H Digital Wireless Hearing Aids III: Audiological Benefits. Hearing Review. 2011;18(8):48-56.
-
Ramsgaard J, Korhonen P, Kuk F. Beyond streaming: Sound quality comparison among WFi hearing aids. Hearing Review. 2016;23(12):36-39.
-
Kochkin S. MarkeTrak VIII: Consumer satisfaction with hearing aids is slowly increasing. Hear Jour. 2010;63(1):19-32.
-
Kuk F, Baekgaard L, Ludvigsen C. Design considerations in directional microphones. Hearing Review. 2000;7(9):68-73.
-
Korhonen P, Kuk F, Seper E, Morkebjerg M, Roikjer M. Evaluation of a wind noise attenuation algorithm on subjective annoyance and speech in wind performance. J Am Acad Audiol. 2016;In press.
-
Lee L. Efficacy of a wind noise attenuation algorithm. Hearing Review. 2016;23(6):22-26.
-
Kuk F, Keenan D, Lau C. Preserving audibility in directional microphones: Implications for adults and children. Hearing Review. 2005;12(11):62-68.
-
Ludvigsen C, Baekgaard L, Kuk F. Using digital signal processing to enhance the performance of dual microphones. Hear Jour. 2002;55(1):35-45.
-
Kuk F, Keenan D, Lau C, Ludvigsen C. Performance of a fully adaptive directional microphone to signals presented from various azimuths. J Am Acad Audiol. 2005;16(6):335-349.
-
Kuk F, et al. Integrated signal processing–A new standard in hearing aid processing. Hearing Review. 2006; 13(4)[Supp 1]:3-22.
-
Pedersen A, Kuk F, Peeters H, Lau C, Crose B. Performance of a fully adaptive multiband directional microphone in a low- pass noise. Unpublished data, 2010. Available from the author.
-
Peeters H, Kuk F, Lau C, Keenan D. Subjective and objective measures of noise management algorithms. J Am Acad Audiol. 2009;20(2):89-98.
-
Auriemmo J, Kuk F, Lau C, Dornan B, Marshall S, Pikora M, Quick D, Thiele N, Stenger P, Sweeton S. Efficacy of an adaptive directional microphone and a noise reduction system for school-aged children. J Edu Audiol. 2009;15:16-28.
-
Kuk F, Korhonen P, Lau C, Keenan D, Norgaard M. Evaluation of a pinna compensation algorithm for sound localization and speech perception in noise. Am J Audiol. 2013;22(6):84-93.
-
Kuk F, Keenan D. Efficacy of a reverse cardioid directional microphone. J Am Acad Audiol. 2012;23(1):64-73.
-
Ludvigsen C, Topholm J. Fitting a wide range compression hearing instrument using real ear threshold data: a new strategy. Hearing Review. 2(11):37-39.
-
Kuk F, Ludvigsen C, Kaulberg T. Understanding feedback and digital feedback cancellation strategies. Hearing Review. 2002;9(2):36-43.
-
Ludvigsen C. Basic amplification rationale of a DSP instrument. Hearing Review. 1997;4(3): 58-70.
-
Kuk F. Optimizing compression: The advantages of a low compression threshold. In: Kochkin S, Strom KE, eds. High Performance Hearing Solutions III: Marketing and Technology. Hearing Review. 1997;6(11)[Suppl]:44-47.
-
Chasin M. Setting hearing aids differently for different languages. Sem Hear. 2011;32:182-188.
-
Kuk F, Lau C, Seper E, Sonne M. Real world satisfaction of a hearing aid that enhances effortless hearing. Hearing Review. 2016;23(4):40-48.
-
Kuk F. Rationale and requirements for a slow acting compression hearing aid. Hear Jour. 1998;51(6):45-53, 79.
-
Souza P. Effects of compression on speech acoustics, intelligibility, and sound quality. Trends Amplif. 2002;(4):131-165.
-
Lunner T. (2003). Cognitive function in relation to hearing aid use. Int J Audiol. 2003;42:S49-S58.
-
Korhonen P, Kuk F, Lau C, Keenan D, Schumacher J, Nielsen J. Effects of a transient noise reduction algorithm on speech understanding, subjective preference, and preferred gain. J Am Acad Audiol. 2013;24:845-858.
-
Korhonen P, Lau C, Kuk F, Keenan D, Schumacher J. Effects of coordinated compression and pinna compensation features on horizontal localization performance in hearing-aid users. J Am Acad Audiol. 2015;26:80-92.
-
Sweetow R, Jeppesen AM. A new integrated program for tinnitus patient management: Widex Zen therapy. Hearing Review. 2012;19(7): 20-27.
-
Kuk F, Ludvigsen C, Paludan-Muller C. Improving hearing aid performance in noise: Challenges and strategies. Hear Jour. 2002;55(4): 34-46.
-
Kuk F, Peeters H. Speech preservation in noise management strategies. Hearing Review. 2007; 14(12):28-40.
-
Kuk F, Paludan-Muller. Noise management algorithm may improve speech intelligibility in noise. Hear Jour. 2006;59(4): 62-65.
-
Peeters H, Lau C, Kuk F. Speech in noise potential of hearing aids with extended bandwidth. Hearing Review. 2011;18(3):28-36.
-
Kuk F, Peeters H, Korhonen P, Lau C. Effect of MPO and noise reduction on speech recognition in noise. J Am Acad Audiol. 2011;22(5):265-273.
-
Kuk F, Seper E, Lau C, Korhonen P. Tracking of noise tolerance to measure hearing aid benefit. J Am Acad Audiol. 2017; In press.
-
Kuk F, Nordahn M. Where an accurate fitting begins: Assessment of In-situ acoustics (AISA). Hearing Review. 2006;13(7):60-68.
-
Kuk F, Baekgaard L. Considerations in fitting hearing aids with extended bandwidth. Hearing Review. 2009;16(10):32-39.
-
Lau C, Kuk F, Keenan D, Schumacher J. Amplification for listeners with a moderately severe high-frequency hearing loss. J Am Acad Audiol. 2014;25:562-575.
-
Moore B, Malicka A. Cochlear dead regions in adults and children: Diagnosis and clinical implications. Sem Hear. 2013;34(1):37-50.
-
Kuk F, Korhonen P, Peeters H, Keenan D, Jessen A, Andersen H. Linear frequency transposition: Extending the audibility of high frequency information. Hearing Review. 2006;13(10):42-48.
-
Auriemmo J, Kuk F, Lau C, Marshall S, Thiele N, Pikora M, Quick D, Stenger P. Effect of linear frequency transposition on speech recognition and production in school-age children. J Am Acad Audiol. 2009;20(5):289-305.
-
Kuk F, Keenan D, Korhonen P, Lau C. Efficacy of linear frequency transposition on consonant identification in quiet and in noise. J Am Acad Audiol. 2009;20(8):465-479.
-
Kuk F. (2013). Considerations in verifying frequency lowering. Hearing Review. 2013;20(1):12-17.
-
Kuk F, Keenan D. Frequency transposition: Training is only half the story. Hearing Review. 2010;17(11): 38-46.
CORRESPONDENCE can be addressed to Dr Francis Kuk at: [email protected]
FOR MORE INFORMATION about the BEYOND from Widex visit: www.widexpro.com
Citation for this article: Kuk F. Going Beyond: A testament of progressive innovation. Hearing Review. 2017;24(1)[Suppl]:3-21.
Image: © Linda Bucklin | Dreamstime.com