Hearing Aid Fitting | February 2001 Hearing Review
The hearing industry is constantly striving to develop hearing instruments that improve listening for people with hearing impairment. The technological advances confronting dispensing professionals and consumers are mind-boggling: digital signal processing hearing instruments, hearing instruments with multiple microphones, FM receivers integrated into hearing instruments, disposable hearing aids and much more. The dispensing professional finds him/herself in the middle of a complex debate: “What technology is best for my client’s hearing loss? What technology is best for my client’s lifestyle? How will I measure benefit? Will my client hear better in noise? Is digital really better than analog? And most importantly, will speech be easier for my client to understand?”
Though patient comfort has definitely been enhanced with some of the techniques listed above, the jury is still out on whether speech understanding is consistently improved across all listening conditions with these techniques (FM being the exception). With all the sophisticated technology being introduced, why is improving speech understanding still such a challenge and why is measuring client benefit so difficult?
Hearing instruments manipulate the amplitude of a signal, making sound louder across frequencies. This strategy meets the needs of some, but research is suggesting that when a hearing loss is greater than 60 dB in the high frequencies, amplification to these frequency regions may not improve speech recognition, but may actually have negative effects.1-5 This finding adds a new element for consideration: even if the hearing instrument could deliver the desired amount of gain and output to the high frequencies, if the client’s auditory system is unable to benefit from the amplified signal, and more than 35% of critical speech information is located above 2 kHz, how can a hearing care professional successfully address the number-one reason a person wears a hearing aid—namely, to improve speech understanding? And, given the time constraints of a busy practice, how can one quickly assess the benefits of hearing instruments in light of the diverse populations served?
One signal processing strategy that addresses the limitations of amplification, and unusable hearing, is proportional frequency compression. Proportional frequency compression allows dispensing professionals to “move” critical high-frequency speech information into lower frequencies where clients typically have better hearing. With this technique, it is possible to “match the bandwidth of the incoming speech signal to the damaged ear’s limited band of greatest sensitivity, rather than attempting to force the damaged high frequency sensory units to respond.”6
The use of proportional frequency compression as a method to tap into useable hearing has been mentioned in several publications over the past few years.7-8 Though various proportional frequency compression algorithms exist7-9, to date, AVR Communications is the only company producing ear-level proportional frequency compression hearing instruments with their ImpaCt and Logicom-20 hearing instruments.
How Proportional Frequency Compression Works

|

|
| Fig. 1a-b. Top: Typical spectrum of the sounds /sh/ and /s/ (shaded area is the frequency response of a hearing instrument). Bottom: Same sounds with Frequency Compression for Voiceless Sounds (FCVL) applied at a factor of 2.25, proportionally compressing the original signal 2.25 times lower in frequency. Note preservation of the peak-to-peak relationships within the sounds. |
In Fig. 1a, the two curves illustrate the typical spectrum of the sounds /sh/ and /s/. The shaded area is the frequency response of the hearing instrument. In Fig. 1b, proportional Frequency Compression for Voiceless Sounds (FCVL) is applied at a factor of 2.25. The /sh/ and /s/ are proportionally compressed into frequencies 2.25 times lower than the original signal. Audibility and discrimination of high frequency voiceless sounds are made possible because relationships of the energy peaks within a sound and between sounds has been maintained. It is the relationship of these energy peaks—not the absolute frequency of the peaks—that gives a sound its identity and enables discrimination. The amplified signal is compressed to the frequency band where the acoustic response of the hearing instrument (shaded area) provides effective gain and the client has better residual hearing.
The proportional frequency compression technology described above functions in a selective manner. A process called Dynamic Speech Re-Coding first identifies specific characteristics in speech to determine if that speech sound needs to be frequency compressed. The selective proportional frequency compression process is designed to ensure that only desired sounds are moved lower in frequency while other sounds are not modified. A spectrogram of the sentence, “She sinks instead of swimming,” demonstrates the selective nature of AVR’s proportional frequency compression (Fig. 2a & 2b).

|

|
| Fig. 2a-b. Spectrogram of the original recording “She sinks instead of swimming” (left) compared to the same sentence after being processed with the proportional frequency compression hearing instrument (right). |
In the spectrogram (Fig. 2a), the original recording “She sinks instead of swimming” is shown on the horizontal axis. The sentence is approximately 1.8 seconds in duration. Note that:
- The /sh/ in the word “she” has energy spread from approximately 2-8 kHz, with the majority of energy being concentrated above 2 kHz.
- At approximately 150 msec, the “e” in the word “she” begins. The first formant of “e” occurs at approximately 400 Hz and the second formant in the 2600-2800 Hz region.
- The formant transition of the “e” is apparent. Located at approximately 250 msec is the beginning of the initial “s” in the word “sinks.”
- The first energy band of “s” is present between 2–3 kHz and the second, more significant energy band is spread well above 5 kHz.
Now let’s consider a patient who has no useable hearing above 2 kHz. If we draw a line at 2 kHz, the information below this line is what the patient hears to discriminate the sentence. Therefore, the sentence “She sinks instead of swimming” becomes:
“ _e _ in (k) i_ _ ead o_ _wimmin_.”
(The parenthesis around the “k” indicates that the first energy band might be audible to the client but the second would not.)
The spectrogram in Fig. 2b shows the original recording played through a hearing instrument with proportional frequency compression enabled. In contrast to Fig. 2a, critical high-frequency speech information is now available below 2 kHz. Additionally:
- The energy of /sh/ is now concentrated between 500-3500 Hz.
- The “e” in the word “she” appears as it did in the original recording. The first and second formants and formant transitions are unaffected. This occurs because the Dynamic Speech Re-Coding process is selective.
- The energy of the initial “s” in the word “sinks’ is now concentrated from approximately 1000–3700 Hz.
The example above specifically addresses frequency compression when applied to “sh” and “s” sounds, but if high-frequency voiceless sounds, such as “t,” “f,” “th,” etc., are present in a sentence, they will also be frequency compressed. This can be observed in Fig. 2a at 899 msec, where the “t” sound in the word “instead” begins. The energy spread of “t” is from 2-8 kHz. When proportional frequency compression is applied, the energy of the “t” is moved to the 1000-3500 Hz region (Fig. 2b). Because the degree of useable hearing will vary from patient to patient, the prescribed amount of frequency compression will vary accordingly.
For this reason, the frequency compression component in ImpaCt and Logicom-20 hearing instruments is programmable. Once enabled, the frequency compression for voiceless control (FCVL) ranges from a factor of 1.50 to 5.0 in 15 steps of 0.25.
Measurement of Benefit
Two case studies demonstrate how the Ling Five Sound Test1 (/a/, /u/, /i/, /sh/, /s/) can be used as a quick, accurate assessment tool to determine what sounds a client can detect and discriminate across the speech spectrum. In both cases, the Ling Five Sound Test plus the “t” sound was administered live-voice at normal conversational level with no visual cues. The test results associated with each case were obtained during the same session a frequency compression hearing aid was fit.
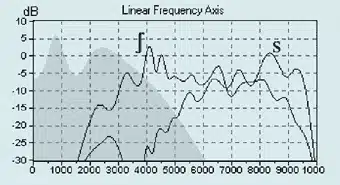
Case 1: A five-year-old with a bilateral severe-to-profound hearing loss. The child is being mainstreamed in an oral program and receives auditory-oral therapy weekly. Three hearing instruments were considered: a power programmable hearing aid, a power digital hearing aid, and the ImpaCt DSR675 power hearing aid (Fig. 3).

Fig. 3. Audiogram for Case 1. |
Aided thresholds from 250-2000 Hz were within 5 dB for all three hearing instruments. ImpaCt thresholds were slightly better at all frequencies except 2 kHz. At 4 kHz, a significant separation in performance between the hearing instruments can be observed. The proportional frequency compression aid provided 15 dB better thresholds (sound is approximately five times louder) than the programmable and the digital hearing instruments. The Ling Test results were as follows:
- Power programmable instrument: The child could detect all sounds except /s/ and could discriminate: /a/, /u/, /i/, /sh/.
- Power DSP instrument: The child could detect all Ling sounds plus “t” but could only discriminate: /a/, /u/ and /sh/.
- ImpaCt DSR675: The child could detect and discriminate all Ling sounds plus “t.”
| Case #1 WIPI | ||
| Aid | Score | Test Level |
| Programmable Digital Impact |
64% 52% 80% |
55dB HL 55dB HL 55dB HL |
| Table 1a. Case 1 speech discrimination. | ||

The programmable and digital hearing instrument provided detection, but the proportional frequency compression instrument provided the high frequency cues required for discrimination. The client’s inability to discriminate “t” and “s” wearing the programmable hearing instrument can be attributed to the aided threshold at 4 kHz being outside the speech banana. Though the digital hearing instrument provided detection of all sounds, aided thresholds at 500 Hz, 2000 Hz and 4000 Hz support the inability to discriminate the /i/, /s/ and /t/ sounds. Speech discrimination testing was performed at 55 dB HL using the WIPI. The client achieved 64% wearing the programmable hearing instrument, 52% with the DSP instrument and 80% wearing the frequency compression instrument. The correlation between the aided thresholds, Ling Test and WIPI results support the use of the Ling Test to predict speech discrimination ability.
Case 2: 24-year-old with moderately severe to profound bilateral sensorineural hearing loss. The right ear presented with a flat, profound hearing loss that has never been aided.

|
| Fig. 4. Audiogram for Case 2. |
| Case #2 WIPI | ||
| Aid | Score | Test Level |
| WDRC ImpaCt |
68% 92% |
45dB HL 45dB HL |
| Table 2b. Case 2 speech discrimination. | ||

Though the aided thresholds with the WDRC instrument were good, aided thresholds with the proportional frequency compression aid were significantly better from 1-6 kHz. The Ling Five sound test results were as follows:
- WDRC: The client could detect all sounds but /s/ and could discriminate: /a/, /u/, /i/ and /sh/.
- ImpaCt DSR675: The client could detect and discriminate all Ling sounds plus “t.”
Speech discrimination testing was performed at 45 dB HL using NU-6 word lists. The client achieved 68% discrimination with the WDRC hearing instrument and 92% with the frequency compression hearing instrument. The correlation between the aided thresholds, Ling Test and NU-6 results once again support the use of the Ling Test to predict speech discrimination ability.
Conclusion
The above case studies underline the need for hearing care professionals to consider carefully all available options when treating high frequency hearing loss. The results of these cases support changing conventional amplification to amplification with proportional frequency compression. This change is warranted if the significance of high frequency voiceless sounds are considered, particularly the “s” which carries more grammatical information than any other sound in the English language. The clients will now be able to hear plurals, possessives, third person singular, contractions, etc. The addition of this single phoneme is significant for speech and language development, speech understanding and speech production.
When fitting hearing instruments, hearing care professionals might be seen as playing the game “The Wheel of Fortune” with clients. If we only provide access to voiced sounds, it will be much more difficult for them to “solve” the speech understanding “puzzle.” As voiceless consonants are added, the ability to “solve the puzzle” increases. As dispensing professionals search for technology that provides their clients with the most complete “picture” of speech, they may need to rethink how hearing instruments amplify speech, how the amplified signal is delivered to the impaired ear and how to assess benefit. Proportional frequency compression is designed to provide dispensing professionals with a tool to tap into the high frequency speech cues clients need to improve speech recognition, and the Ling Test can serve as a quick, accurate test to assess hearing instrument benefit.
Acknowledgements
The author thanks Danelle Knowlton, MA, Oakland Children’s Hospital, Oakland, CA, and Claudia Hawley, MA, West Metro Audiological Services, Minnetonka, MN, for providing the case studies in this article, and Barak Dar, Victoria Miskowiec and Joel Skoog for their input.
This article was submitted to HR by Wendy E. Davis, MS, director of professional services at AVR Sonovation, Eden Prairie, MN. Correspondence can be addressed to HR or Wendy Davis, MS, AVR Sonovation, 7636 Executive Drive, Eden Prairie, MN 55344; email: [email protected].
References
1. Ching T, Dillon H & Byrne D: Speech recognition of hearing-impaired listeners: Predictions from audibility and the limited role of high-frequency amplification. J Acoust Soc Amer (JASA) 1998; 103: 1128-1140.
2. Skinner M: Speech intelligibility in noise-induced hearing loss: Effects of high-frequency compensation. JASA 1980; 67: 306-317.
3. Turner C: The limits of high frequency amplification. Hear Jour 1999; 52 (2): 10-14.
4. Hogan CA & Turner CW: High-frequency audibility: Benefits for hearing-impaired listeners. JASA 1998; 104: 432-441.
5. Goldbaum S, Halpin C: Exploring the Damaged Ear: The NIDCD National Temporal Bone Registry. ASHA 1999; Jan/Feb: 29-33.
6. Bennett DN & Byers VW: Increased intelligibility in the hypacusic by slow-play frequency transposition. J Auditory Res 1967; 7: 107-118.
7. Turner CW: New technology compresses sound frequency. Advance for Speech-Lang Path & Audiol 1999; 9 (51): 5.
8. Turner CW & Hurtig RR: Proportional frequency compression of speech for listeners with sensorineural hearing loss, JASA 1999; 106, 877-886.
9. Hurtig RR: Perception of spectrally compressed speech. Proceedings of the XIIth International Congress of Phonetic Sciences, 1991: 2, 98-101.
10. Ling D: Speech and the Hearing-Impaired Child: Theory and Practice. Washington, D.C: A.G. Bell Assn for the Deaf, 1976.


