
How next-generation on-device sensing and compute can overcome power, latency, and noise challenges in hearing aids.
By Mohamed Sabry, PhD
Summary:
Real-time artificial intelligence (AI) inference is driving advances in sensor technology and ultra-low power processing architectures that can be used to address hearing aid issues, including noise, latency, and power consumption.
Key Takeaways:
- Adding better, energy-efficient, on-board processing to hearing aids could reduce audio lag and energy usage, prolonging battery life.
- With fast AI-powered learning, hearing aid sensor ‘wake’ modes can adapt more quickly to different listening situations.
- Smaller, more efficient systems-on-chips (SoCs) could help manufacturers create more efficient, cost-effective hearing aids.
Introduction
In a world increasingly full of noise from traffic, leaf blowers, crowds, Bluetooth speakers, and a growing list of other sources, hearing aid manufacturers are challenged to create high-quality products for their users. And as users have to deal with more and more noise pollution, they’re expecting hearing aids to deliver more natural sound and seamless performance in these complex aural environments, filtering out noises and enhancing the targeted sources to be focused on.
The hope is that improving technology can guide both parties to a future where better hearing in any environment is not only possible, but easier and more affordable. With new advances in sensor technology and ultra-low power processing architectures, that goal is within reach. This article delves into how this technology works and how it could be used to cause reductions in noise, latency, and power consumption in hearing aids.

The Limitations of Traditional DSP Approaches
Modern hearing aids already perform all real-time audio processing on the device, because sending sound to the cloud would introduce unacceptable latency, drain the battery, and raise privacy concerns. This long-standing dependence on local processing means that hearing aids rely heavily on highly optimized digital signal processing (DSP) architectures to deliver features such as beamforming, noise reduction, compression, and feedback management.
Traditional DSP cores are reaching their practical limits, however, as manufacturers push toward more advanced capabilities, including environment classification (the ability to automatically distinguish between acoustic scenes such as quiet rooms, traffic, or crowded restaurants), adaptive noise suppression, and increasingly personalized sound profiles. The computational load required to support these AI-driven features continues to rise, relentlessly demanding increased performance and memory resources, yet hearing aids must maintain extremely low power budgets and compact form factors. This creates a growing tension between the desire for more intelligent, adaptive listening experiences and the constraints of existing hardware.
These pressures are driving the industry toward new processing architectures capable of supporting on-device neural inference at far lower energy levels, making always-on, context-aware functionality possible without compromising battery life or comfort.
Edge AI Works at the Speed of Sound
On-board processing avoids the network latency associated with cloud computing, but latency remains an issue. It is vital to minimize the latency associated with on-board processing itself, because any delays delivering sound are particularly disruptive in hearing technology, where even small lags can affect speech clarity and a user’s sense of naturalness.
Traditional DSP architectures are optimized for fixed algorithms, but they struggle to keep pace with the growing complexity of modern audio environments. They are simply not tailored for efficiently executing complex AI workloads.
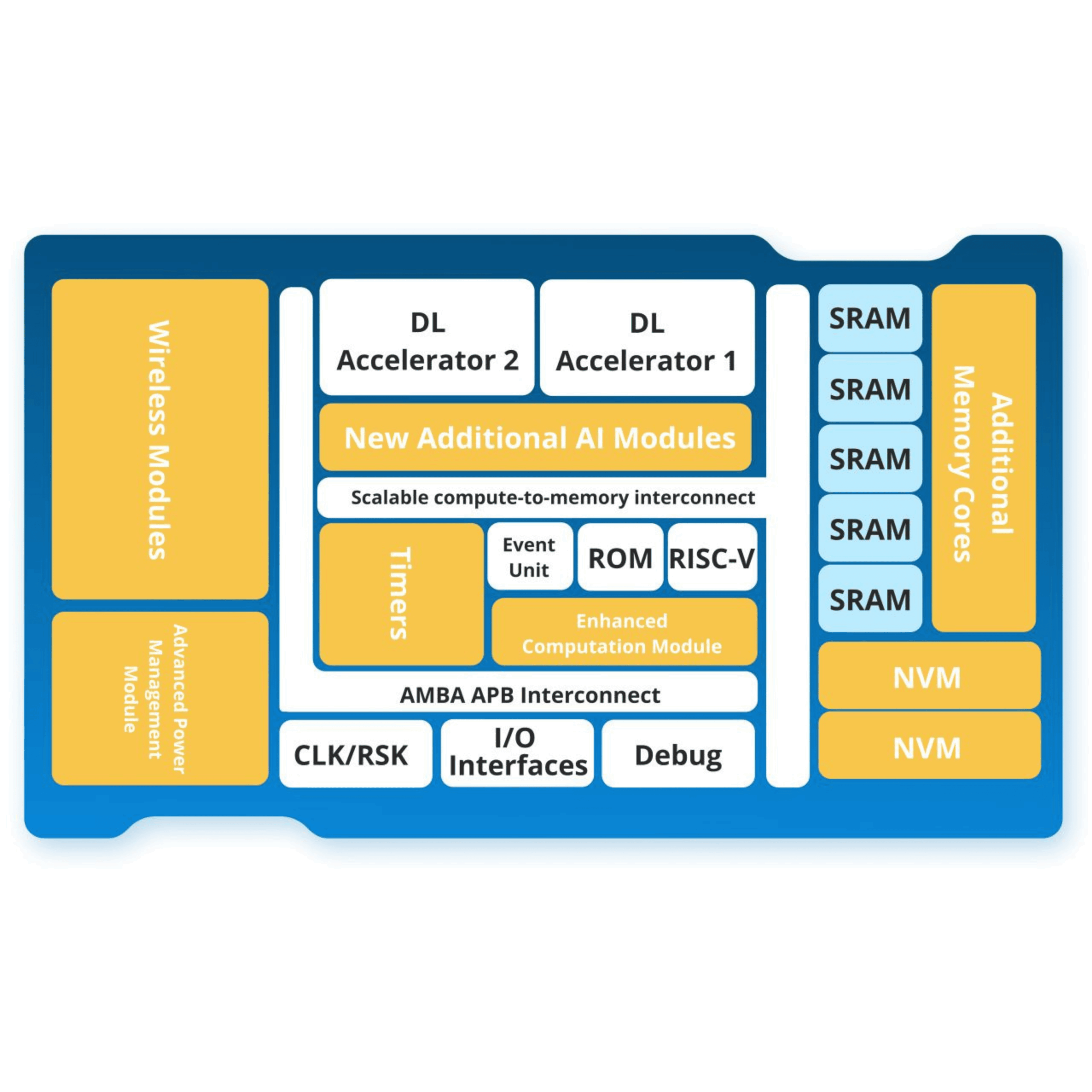
Edge AI offers a path forward by enabling more sophisticated processing directly on the hearing aid itself. Instead of relying on static rules or simplified models, edge AI allows devices to run compact neural networks that adapt to changing acoustic conditions in real time. This shift brings far more nuanced noise suppression, faster environment recognition, and more personalized amplification—without adding noticeable delay.
As semiconductor advances make on-device AI both smaller and dramatically more energy efficient, it becomes possible to deliver these capabilities within the tight power and size constraints of hearing aids, hearables, and emerging consumer hearing technologies.
When Every Milliwatt Counts
When it comes to hearing aids, size and the corresponding comfort are essential concerns for users. You can’t simply add bulky batteries to incorporate on-chip processing to bypass cloud connectivity issues. Achieving this requires both highly efficient sensors and optimized on-device processing architectures. Here’s how:
Latency Reduction
The key to reducing on-board latency—the key to more efficient processing—is to optimize hardware and software so that they operate together as well as possible.
Generally, AI inference involves a processor performing intensely iterative operations on stored and incoming data. This has naturally led to an approach where microprocessors or microcontrollers used to run AI workloads are coupled as tightly as possible with separate memory ICs.
Improving performance with this approach relies on using ever faster processors and ever faster memory devices. As noted above, doing so is problematic for end-products with strict requirements for size, weight, heat dissipation, and cost—devices such as hearing aids.

The better, though perhaps more difficult option for such edge products is to integrate processing with memory. The distances signals must travel in this configuration may be shortened by mere micrometers, but given the extraordinary frequency of data transfers involved when running AI workloads, the cumulative result is a significant reduction in processing latency.
Deep-learning accelerators can achieve sub-millisecond response times for noise suppression and environment adaptation—in this particular instance, less than 10 milliseconds, compared to some chips that operate in the 10- to 100-millisecond range.
It is then possible to optimize AI performance (including minimizing processing latency) by designing algorithms that take specific advantage of this architecture.
Power Conservation
More efficient power usage is an important consideration in almost any design, but it is critical in small edge devices. This class of device is often battery powered, so efficient battery usage—in other words, lower power consumption—translates directly into longer battery life.
Knowing that each sound represents a sizable amount of data that needs to be processed, the metric becomes ‘how many sounds can this chip process on a single charge?’ Compared to some current technology standards, whose power per inference ranges from 5–100 mW to 30–150 mW, it’s easy to see how the advancement of ultra-low-power compute cores that use less than 1 mW per inference is a massive improvement.
More efficient power usage can also lead to lower power dissipation. In small, battery-powered devices, the amounts of heat generated are usually small, but a failure to take the issue into consideration when selecting an AI processor risks allowing excess heat to turn into a comfort/usability issue.
Using power only when it’s needed helps drive down power consumption. With “wake-on-sound” operation, dynamic power gating works to keep inactive subsystems asleep until they’re needed. Intelligent waking improves responsiveness while lowering energy consumption, which enables full-day or multi-day operation even in compact form factors. Add to this innovations such as adaptive on-device learning—which allows hearing aids to adapt dynamically to different listening situations—and you’ll conserve even more power.
From a hearing aid user’s perspective, the creation of efficient, low-power neural inference greatly improves noise suppression and reduces audio lag, enabling clearer, more natural conversations without perceptible lag. For those who may not understand the gravity of such value-add, imagine a split-second delay with everything you hear, and you’ll agree that such timeliness of audio transfer is a critical point.
Flexibility
Advances in technology are more impressive if their ability to be used reaches a larger audience. This is clearly exemplified when they become part of popular devices like Apple’s AirPods, which can act as a sound amplification for those with mild hearing loss. While it may seem limited, mild hearing loss is an issue that affects 5.5% of Americans under 40; and 19% among those between 40 and 69 years old. That’s tens of millions of Americans, and it’s why supporting various hearing devices—with platform flexibility—is so important.
From over-the-counter hearables to medical-grade hearing aids, an SoC with cleverly integrated logic and memory, running algorithms optimized for that architecture, can help make scalable neural inference across multiple sensors (acoustic, motion, biometric) possible without any external processing overhead, enabling neural inference without external memory components, reducing board complexity and cost. Additionally, technology improvements that bring an ease of integration with existing DSP or Bluetooth architectures could greatly accelerate design cycles to continue pushing hearing aid technology to new levels.
By reducing this overall complexity, and component acquisition challenges, creating such publicly available hearing technology opens the door for a greater swath of people with hearing loss to access the necessary support.
Prepared for the Evolution of Better Hearing
As AI continues to expand what’s possible in many industries, I’d contend it’s essential to design Edge AI architectures that are built to adapt. From firmware upgrades to new algorithms, the right SoC will support compressed or quantized models to ensure compatibility with future audio and health sensing applications. Embedded AI makes context-aware features like automatic volume control, adaptive EQ, and personalized sound profiles possible.
This is why we at EMASS use an “Atoms-to-Apps” philosophy. We begin with real-world requirements for applications and co-design hardware and firmware to work together seamlessly. In doing so, our goal is to push the frontier of device physics. We integrate emerging nanotechnologies, while creating architectures that address the practical limitations of both new materials and conventional approaches. By starting at the device level and flowing through circuit design, micro-architecture, sensor interfaces, system architecture, compilers, runtimes, and application optimization, we aim to unlock a new era of always-on—an era with many benefits for hearable technology that helps humans.
Enhanced User Experience is the Bottom Line
Advancing SoC technology drives industry progress, but the ultimate goal is improving real human listening experiences. It’s about building a future where more natural and effortless hearing experiences in dynamic environments are possible for users—a future where secure, on-device processing enhances privacy for users and regulatory compliance for manufacturers, and much more. Together, the aforementioned advances point toward a new generation of hearing technology that is smarter, more efficient, and more responsive to real-world needs, ushering in hearing technology that is more personalized, adaptive, and human-centered.
About the Author:
Mohamed Sabry, PhD, is the founder and CTO of EMASS, a semiconductor manufacturer specializing in ultra-low-power Edge AI chips. He is also an associate professor in the School of Computer Science and Engineering at Nanyang Technological University in Singapore.
Featured image: Devices including hearables and hearing aids can benefit from advanced AI processing. Photo: EMASS



