Digital signal processing (DSP) hearing instruments are no longer a novelty. Second-generation digital hearing instrument chips are emerging, and there are now 30-40 different digital instrument lines offered by over a dozen manufacturers. Once considered a “special product” by dispensing professionals, the fitting of digital instruments is now considered “routine” in many clinics and offices.
As time passes, the focus on DSP hardware issues such as dynamic range, number of bits or sampling rates is giving way to more focus on the practical benefits that digital technology offers to the hearing-impaired consumer. Simply “being digital” is not good enough anymore. This technical report discusses the latest digital instrument technology, using the Siemens Hearing Instruments Signia as its example, and specifically addresses how DSP features can relate to patient benefit.
Channel Selection and Compression Characteristics
While there does not appear to be a clear distinction between “bands” and “channels” when discussing hearing instrument processing, there is a general agreement that bands relate to adjustment of gain, whereas channels describe a region of adjustable automatic signal processing.1 Channels were formerly associated only with regions of compression. With today’s products, however, channels also are used for expansion and as regions of frequency-specific noise reduction or speech enhancement. The optimum number of channels for this type of signal alteration might not be the same as the number of channels that are appropriate for optimizing compression characteristics. Therefore, it’s important to discuss these categories separately.
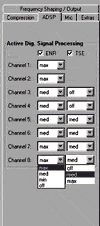
Temporal and Spectral Processing: To appropriately analyze an incoming broadband signal, especially for making decisions on whether the signal is primarily speech or noise, it is necessary to divide this signal into several channels. For example, the Siemens Signia utilizes up to eight channels for two different types of signal analysis. Environmental Noise Reduction (ENR) is a channel-specific gain reduction employed when the primary input signal is judged to be noise. This analysis is conducted independently in all eight channels. When speech is the primary signal in a given channel, another type of processing occurs, referred to as Transitory Signal Enhancement (TSE). This algorithm identifies the low-intensity consonants of the speech signal, and provides a temporary gain boost to these speech components. The processing strength of these two features is based on the client’s hearing loss and is automatically adjusted in the CONNEXX “First Fit” program or can be manually adjusted in each channel (Fig. 1).
WDRC: There are no clear-cut rules regarding the optimum number of channels that are required for hearing instrument compression. We know that one channel of compression can be insufficient, but how many are enough? Or too many? At some point, adding additional channels of compression provides little or no benefit, and possibly could be detrimental by creating a “spectral smearing” of the speech signal. Moreover, power, space and processing time are always critical design factors for a digital instrument; resources saved by using fewer channels of compression possibly can be used for other types of signal processing.
The primary goals of WDRC processing are to maximize intelligibility for a wide range of input intensities, and to restore loudness perception for individuals who have hearing losses of varying degrees and configurations.2 The selection of four channels of compression in the Signia is consistent with the recent research of Rickert et al.3 The eight channels of signal processing are automatically placed within the four channels of compression; the distribution is based on the patient’s audiometric configuration and dynamic range (the automatic categorization can be modified by the dispenser).
The benefits of WDRC to the user are directly tied to the channel-specific preciseness of the fit—in other words, the appropriate settings of the compression kneepoint, ratio and time constants. These three compression features automatically are adjusted for each patient in the software using the DSL First Fit algorithm. Post-fitting adjustment also can be made by the dispensing professional via the four-level acclimatization software feature.
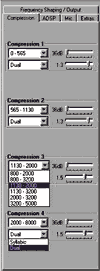
More direct modifications of the compression features can be made using the Parameter Assistant or the Fitting Assistant. A final approach is to utilize the Global Access feature of the software (Fig. 2) in which both compression kneepoints and ratios can be adjusted. Compression kneepoint adjustments are especially important for those patients who need to be “eased into” WDRC processing or who show a definite preference for higher compression kneepoints.4 Likewise, depending upon the patient’s hearing loss in the high frequencies, the release time of the WDRC will be set to be adaptive in the “dual compression” mode for all four channels, or set to syllabic compression (80 msec release time) for Channels 3 and/or 4. These features also can be controlled by the dispenser to meet the requirements of a given fitting philosophy or the needs of a specific listening situation (Fig. 2).
AGCo: As with WDRC, it is also advantageous to employ AGCo processing in multiple channels. With broad-band AGCo, whenever an input signal exceeds the compression threshold, a “ceiling effect” is imposed on signals across the entire frequency range. In many cases, this unnecessarily reduces the output at frequency regions where the patient’s LDL has not been reached, thus reducing headroom. The patient may report a lack of fullness of the signal or a lack of loudness growth for situations when greater loudness would be expected (e.g., listening to an individual “talking over” party noise). When multichannel AGCo is implemented (even when the compression kneepoint has been reached for one channel), the hearing instrument output will continue to increase for other channels until the kneepoint has been reached. In this way, headroom can be maximized across the entire frequency range.
The instrument utilizes four-channel AGCo with a compression ratio of 10:1 (attack time <2 ms; release time = 80 ms). The compression kneepoints are automatically set in each channel based on the patient’s measured or predicted LDLs for that frequency range. Research has shown that this four-channel AGCo compression strategy improves loudness differentiation for the patient without causing loudness discomfort.5
Expansion: A fourth area related to channel selection and patient benefit is audio expansion. If loudness restoration is the fitting goal, and low kneepoints are employed (e.g., 30-40 dB SPL), it is common that about 40 dB of gain is present for inputs that are at or near the compression kneepoint. For many patients, this amplification strategy results in too much gain for inputs that occur below the kneepoint (common inputs below the kneepoint include low-level room noise and microphone noise).
Dispensing professionals frequently treat this problem by raising the kneepoint and/or reducing gain. Unfortunately, both methods have the negative consequence of reducing the audibility of important soft speech inputs. An alternative method to reduce the gain for these low-level sounds is to use expansion. In the case of Signia, expansion is employed in four independent channels (labeled “microphone noise reduction” in the fitting software).
While some products have a single expansion kneepoint, it can be advantageous to use multichannel expansion, as it may be desirable to have different expansion kneepoints for different frequency ranges. For example, if slightly more microphone noise is present when the “equalized response” of the directional microphone is employed, the low-frequency expansion kneepoints can be raised, while the high-frequency kneepoints can be retained at a level that will optimize the reception of soft speech.
It is possible that, in a unique listening situation (i.e., both speech and noise below the expansion kneepoint), the expansion feature will improve the signal-to-noise ratio for the hearing instrument user. In general, however, the primary benefit of hearing instrument expansion is the reduction of low-level noises that can be annoying or fatiguing to the user. There are some isolated cases, however, where the user prefers to hear these noises (e.g., sometimes as a masker of tinnitus or as reassurance that the aid is turned on). In these instances, the dispensing professional can disable the expansion circuit.
Noise Reduction/Speech Enhancement Processing
Environmental Noise Reduction (ENR): ENR is an enhancement of the Voice Activity Detection (VAD) system of the Siemens Prisma, which was reviewed in an earlier publication.6 As oreviously mentioned, the ENR is designed to detect whether the primary signal in a given channel is speech or noise. The average talker will formulate 12 phonemes, 5 syllables and 2.5 words per second, which creates a speech envelope. This envelope of speech shows a temporal characteristic, which can be referred to as the signal modulation.
Modulation frequency, intensity and the depth (speech has a large modulation depth) can be analyzed, and a channel-specific gain reduction can be applied when the primary signal is determined not to be speech. The system is most effective when the “noise” is broad band; the system is least effective when the noise is speech-like, as in “cocktail-party” babble. A typical example might be listening to speech while riding in a car. The primary signal in Channels 1, 2, 7 and 8 might be noise (thus, gain is reduced) and the primary signal in Channels 3, 4, 5 and 6 might be speech (no gain reduction). The overall effect can be a reduction in the signal-to-noise ratio, although in any given channel, the signal-to-noise ratio remains the same.
The ENR in Signia is automatically adjusted in all channels during the First Fit procedure based on the patient’s hearing loss. The strength of ENR is also dispenser adjustable, with gain reductions of 12 dB (min.), 18 dB (med.) or 24 dB (max.) available in each channel. ENR can also be deactivated. This is useful for setting up a program for special listening (e.g., music) or as a temporary setting for conducting 2cc coupler, functional gain or probe-microphone measurements. It is also useful for demonstrating the effects of ENR to the patient.
It is tempting to think of ENR as a method of improving speech intelligibility in noise for the hearing instrument user. In fact, there are some listening conditions when this benefit is indeed present. Unfortunately, what many patients refer to as “noise” is not noise, but speech—speech they do not want to hear. When speech signals comprise the competing stimulus, it is unlikely that the patient will experience significant improvement in speech intelligibility using the ENR processing; the algorithm cannot separate speech we want to hear from speech we don’t want to hear.
As mentioned, one benefit of the ENR is to reduce the “annoyance” of various non-speech sounds. As part of the instrument’s clinical trials (Cleveland Clinic and Univ. of Louisville), this aspect of the ENR feature was evaluated. Hearing-impaired listeners (n = 53), using a 10-point categorical scale, rated the annoyance level of traffic noise for “ENR off” compared to “ENR on.” The results showed a significant reduction in noise annoyance for the “ENR on” condition.7 This finding was especially encouraging, as traffic noise has many modulations that could be interpreted as speech-like.
The benefits of the ENR feature can be demonstrated to the patient at the time of the fitting. For example, even when sitting in a typical office, most patients will notice a reduction of room noise. It is also possible to generate a broadband noise (e.g., fan, hair dryer) that will create a more noticeable effect. Perhaps the best way to illustrate the effect is through the use of probe-microphone testing. While delivering a continuous broadband signal to the ear, the effects of the ENR can be observed by both the examiner and the patient via the monitor; the curve showing the hearing instrument output will drop relative to the programmed gain reduction. The attack and release times also become obvious when test conditions are altered between speech and noise (that is, by talking to the patient while the noise is present, the ENR will turn off, assuming that the input of the speech is greater than the input level of the noise).
Transitory Signal Enhancement (TSE): As mentioned in the preceding section, one method that can be used to improve speech intelligibility is to attempt to remove the “noise” in the input signal. Another approach, which can be used simultaneously, is to enhance components of the speech signal. In particular, it can be beneficial to enhance low-intensity consonants, increasing the consonant-to-vowel ratio—a technique that has been shown to improve consonant recognition.8 This feature is implemented in Signia’s Transitory Signal Enhancement (TSE).
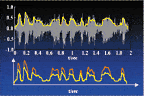
The TSE feature operates by analyzing and reacting to very fast changes in the signal which may indicated the presence of high frequency consonants (e.g., “sh”, “s” and “f”). TSE provides frequency-specific gain enhancement of 3 dB or 6 dB (corresponding to minimum or maximum setting). The feature was designed to enhance the high-frequency consonants and works quickly, spanning a time frame of a few milliseconds. An example of the enhancement that is possible is shown in Fig. 3. For portions of the signal which have the greatest fluctuation (peaks), there is a corresponding gain enhancement (bottom of Fig. 3), emphasizing the high frequency consonant and plosive signals. The strength of the speech enhancement of the TSE is automatically set for each patient, but also can be altered by the dispensing professional.

Spectral & Temporal Settings: The dispensing professional can also control both the spectral and the temporal components of inputs to Signia using the Contrast software feature (Fig. 4). Contrast combines four key features that interact and are related to speech intelligibility: ENR, TSE, Channel Coupling and Compression Time Constants (e.g., syllabic versus dual compression). Using the patient’s audiogram and measured/predicted LDLs, the software automatically adjusts the four parameters to settings that are designed to maximize speech intelligibility for the majority of listening environments.
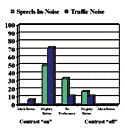
This feature has been evaluated in clinical trial research.7,9 An example of the benefit provided to the user, taken from Wesselkamp9, is shown in Fig. 5. In this study, hearing-impaired listeners were asked to make judgments while they were listening to different inputs with the Contrast feature turned “off” and “on” (“on” was the First Fit setting, which for most subject’s was an “average strength” setting). For both speech-in-noise and traffic noise, there was a strong preference for the “on” setting.
Feedback Control
Another feature of several DSP instruments is the use of digital feedback control algorithms. Two different types of approaches are used in Signia. The first of these, a passive feedback suppression system referred to as the Optimize mode, allows the hearing instrument to be tested at the time of the fitting for potential feedback. An open-loop gain measurement is performed at 27 different frequencies, and suggested changes are made to the channel-specific gain to limit the occurrence of feedback. Where an excessive feedback loop is detected that would otherwise compromise user benefits, the fitting system prompts the dispenser to investigate and correct any earmold or shell issues (e.g., loose fit, excessive venting for gain, etc.).
The second anti-feedback mode in the instrument is referred to as the Adaptive Feedback Suppression System. This system can be engaged in one or all memories to prevent feedback from occurring under conditions of normal use, such as chewing, yawning or positional changes. The system continuously monitors the incoming signals and uses real-time sound data to control and suppress feedback by employing a narrow-band rejection filter in the area of the feedback until it is no longer present. The filter is designed to reduce the gain of the feedback spike, without significantly affecting the original gain available in that frequency area.
Directional Processing
It is well documented that directional microphone hearing aids provide an advantage for understanding speech in background noise, including situations when the background noise is speech—assuming that the desired speech signal is spatially separated from the unwanted “noise”.10-12 While the primary purpose of the present article is to review digital features (i.e., directional microphones also work well in analog hearing instruments), it is important to point out that directional microphone technology is part of the overall signal processing strategy of several DSP instruments. Signia utilizes the dual-omnidirectional microphone approach, and has a directivity index (AI-DI) of over 5.0 dB for custom models. As would be predicted from an AI-DI of this magnitude, clinical trial results showed a significant improvement in speech-in-noise thresholds (Hearing In Noise Test) for the directional microphone setting when it was compared to the omnidirectional mode for people fitted with custom Signia instruments.7 Importantly, the directional microphone advantages are additive to the Contrast processing features discussed earlier.
Summary
Many DSP features may result in increased benefit for the hearing instrument user. In one way or another, these features all focus on speech intelligibility, sound quality and/or listening comfort.
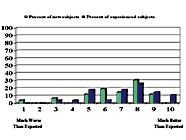
In the day-to-day fitting of hearing instruments, it is important that a product creates a good initial impression as well as longterm performance results. As part of the clinical trial protocol of Signia, the initial impression of the instrument (programmed using the "First Fit" algorithm) was gauged. Based on a brief listening experience in three different listening environments, both new (n=26) and experienced (n=27) hearing instrument users rated their initial impression of the instrument on a 10-point continuum ranging from Rating #1: “Much worse than expected,” to Rating #10: “Much better than expected.” The results of these ratings, taken from Mueller7, are shown in Fig. 6. For both groups of listeners, the instrument met or exceeded expectations for approximately 90% of the subjects, with several subjects rating performance at #8 or above. Given that the patients knew they were being fitted with “new technology,” and many of the previous users were currently using digital products, we would assume that their expectations were quite high, making these positive findings even more significant.
The time has come when simply “being digital” is not good enough for a DSP hearing instrument. The evidence strongly suggests that digital hearing instruments have the ability to provide benefits to the user that are superior to their analog counterparts.
This article was submitted to HR by Thomas A. Powers, PhD, director of audiology, and Pamela L. Burton, MA, director of product management at Siemens Hearing Instruments, Piscataway, NJ. Correspondence can be addressed to HR or Thomas Powers, PhD, Siemens Hearing Instruments, 10 Constitution Ave., Piscataway, NJ 08855; email: [email protected].
References
1. Mueller HG: What’s the digital difference when it comes to patient benefit? Hear Jour 2000; 53 (3): 23-32.
2. Mueller HG: Just make it audible, comfortable and loud but okay. Hear Jour 1999; 52 (1): 10-17.
3. Rickert R, Van Tasell D & Woods W: Compression Bands: How many are needed? Paper Presented at the Annual Meeting of the American Auditory Society, Phoenix. 2000 (April).
4. Barker C & Dillon H: Client preferences for compression threshold in single-channel wide dynamic range compression hearing aids. Ear Hear 1999; 20 (2):127-139.
5. Powers T & Burton P: Combining 4-channel WDRC with 4-channel AGC-O: A new solution to an old problem. Paper Presented at the Annual Meeting of the American Academy of Audiology, Chicago 2000 (March).
6. Powers T, Holube I & Wesselkamp M: The use of digital features to combat background noise. Hearing Review (Suppl) 1999; 3: 36-40.
7. Mueller HG: Siemens Signia: Preliminary finding of clinical trial studies. Paper presented at the Siemens International Symposium, Paris. 2000 (July).
8. Smith L & Levitt H: Consonant enhancement effects on speech recognition of hearing-impaired children. J Amer Acad Audiol 1999; 10 (8): 411-421.
9. Wesselkamp M: Clinical research with the Siemens Signia. Unpublished manuscript. 2000.
10. Mueller HG & Ricketts TA: Directional microphone hearing aids: An Update. Hear Jour 2000; 53, 5: 10-19.
11. Ricketts TA & Mueller HG: Evaluating directional hearing aid performance. Amer Jour Audiol 1999 8 (2):117-127.
12. Wolf R, Hohn W, Martin R & Powers T: Directional microphone hearing instruments: How and why they work. Hearing Review (Suppl) 1999; 3: 14-25.