Hearing aid benefit and satisfaction is nearly always related to the amount of gain and output that is provided. The fitting goal, therefore, is to provide the user with the “best” starting point for gain and output, so that benefit and satisfaction can be optimized in a relatively short period of time. To some extent, the starting point for setting the gain of hearing aids can be predicted from the patient’s hearing loss. This has led to generic prescriptive fitting approaches such as those developed by NAL, with NAL-NL2 as the latest version, or manufacturer-specific algorithms (usually a slight modification of a generic formula), such as Siemens ConnexxFit.


Thomas A. Powers, PhD (top), is vice president of audiology and compliance at Siemens Hearing Instruments, Piscataway, NJ, and Josef Chalupper, PhD (bottom), is director of audiology at Siemens Audiologische Technik (SAT), GmbH, Erlangen, Germany.
In general, it is unreasonable to expect that even the most carefully designed prescriptive fitting method would be appropriate (within ±3 dB) for more than two-thirds of all patients.1 There are several reasons for this. For example, individuals with the same hearing loss have different loudness growth functions. Everyday listening situations also can influence preferred gain.
Additionally, in many cases, better hearing (audibility) compromises sound comfort and vice versa. In some cases, the prescribed high frequency gain may improve speech intelligibility, but the patients perceive the sound quality as too shrill and unacceptable. As a result, they will turn down overall gain, resulting in reduced overall audibility.
The fitting challenge, therefore, is to find the right balance among desired loudness, good audibility, and sound comfort for every patient. As mentioned, this goal is further complicated by the fact that the prescribed gain and output is only appropriate for the “average” patient, and it too needs to be individualized.
All these challenges can be overcome by a learning hearing instrument that the patient can adjust to achieve the optimum settings. Individual preferences, however, also vary across listening situations.
A trainable hearing aid, therefore, is needed that not only learns individual preferred gain, frequency response, and compression, but accomplishes this separately for different everyday listening situations. This article reports on a new Siemens learning algorithm, which is designed to maximize patient listening comfort for a variety of listening situations without reducing the intelligibility and quality of speech.
Automatic Fine-tuning in Daily Life
There has been basic research with trainable hearing aids for many years. For a review of the history of this technology, see Dillon et al2 and Keidser et al.3 Commercial hearing instruments with this capability, however, have been made available only recently. Since 2006, when Siemens introduced the first learning hearing instrument in Centra, learning technology has become recognized as the ideal method for accounting for individual patients’ gain preferences. A learning hearing instrument provides several benefits for both the patient and the dispenser:
- The parameters of the hearing aids can be customized to the user’s preference in their actual listening environment;
- Fewer post-fitting visits for reprogramming are needed, especially for problem fittings;
- Patients can easily retrain their hearing aids if their listening needs or their required gain changes over time;
- The multiple parameters that can be trained exceed what could be accomplished in a typical clinical visit;
- Because the training occurs in the real world (eg, in the presence of reverberation, etc), the results usually will be more satisfactory than what would be obtained in the more “sterile” clinical environment; andn Because the patients are directly involved in the final fitting, they have more “ownership” of the overall hearing aid fitting.

Figure 1. Situation-specific listening goals require different gain and compression settings.
The first generation of trainable hearing aids only trained overall gain. While this was typically successful for training preferred gain for average inputs, the trained setting was not always ideal for soft and/or loud inputs. For example, if a patient has an unusually low UCL, they might train the gain to be lowered whenever they are in loud sounds. If they spend considerable time exposed to loud sounds, this could have an influence on overall trained gain, and as a result, soft inputs might become inaudible. Consistent with this, Mueller et al4 found that while after real-world training, satisfaction was improved and quite high for average-level speech inputs, gain was lower for both soft and loud inputs. Clearly, to be successful—especially for individuals with a narrow dynamic range—trainable hearing aids must learn compression.
For this reason, Siemens introduced SoundLearning in 2008, the first hearing aid algorithm capable of learning compression. This algorithm also included trainable frequency shape. Real-world research using this algorithm has been encouraging. For example, Mueller5 reported on experienced bilateral hearing aid users who for at least 2 years had been using hearing aids programmed on average to: ~10 dB below the prescribed NAL-NL1 for soft inputs, ~5 dB below the NAL-NL1 for average inputs, and gain approximating the NAL-NL1 for loud inputs. Following 2 weeks of real-world training, the participants were using gain within 1-2 dB of NAL-NL1 on average for all three input levels. Satisfaction ratings were also improved.
While the SoundLearning algorithm solved one problem—different training for different input levels—one other problem still remained: it is common for patients to prefer different gain for different types of inputs (eg, speech versus noise versus music).
With even the second generation of trainable instruments, there was no differentiation for the type of input, only the overall level. For patients who spend most of their time in one listening environment (eg, speech in quiet), this is not a major concern. However, if a patient spends considerable time in “loud noise,” and doesn’t prefer much gain for loud noise, the trained gain for loud noise inputs might make gain for loud speech or loud music too soft. The solution, then, is not only a trainable hearing aid that is level-dependent, but one that is also situation-dependent. This prompted the development of the SoundLearning 2.0 algorithm, which offers compression and frequency shape learning for three different listening situations: speech, noise, and music.
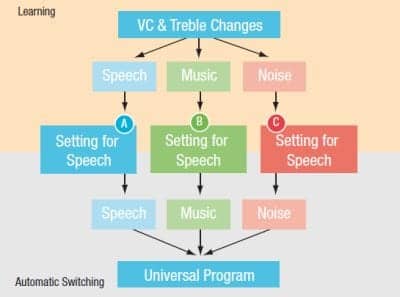
Figure 2. SoundLearning 2.0 learns and automatically applies situation-specific gain and compression settings.
Implementation
The rationale behind situation-specific learning is that, depending on the acoustical environments, users have dedicated priorities with regard to the sound impression. These situation-specific listening goals are illustrated in Figure 1. In situations where speech is present—whether it is speech in quiet or speech in noise—the priority typically will be speech intelligibility. In noisy environments, the noise should be heard, but only at a comfortable level. For music, the sound quality is most likely the priority. Thus, depending on if the current listening situation is speech, noise, or music, the user would prefer different gain and compression settings.
In SoundLearning 2.0, every time the user adjusts the volume or SoundBalance (ie, the adjustment of the frequency response), the adjustment is recorded along with the current input level and detected acoustic environment. This leads to a dedicated frequency response, as well as compression setting for speech, noise, and music. The new learned settings are then selected when the system detects these situations again. The end results are separate settings for each of these listening situations—tailored to individual preferences.
To achieve the same effect with the earlier algorithm, SoundLearning, three separate learning programs were needed, one for each acoustic situation. Additionally, the user had to change the program manually each time the acoustic situation changed. With SoundLearning 2.0, this all occurs automatically and intuitively within one single program.
When the listening situations are mixed situations (eg, “music” and “speech”), the activated setting is a mixture of the “music” and “speech” setting. That is, SoundLearning 2.0 is able to apply a continuum of settings rather than three single settings.
In any trainable hearing instrument, learning can occur in two ways: time-based or event-based. There are some advantages of each, depending on the technology employed:
- Time-Based: The hearing instrument records a data point after a specific interval (eg, every 1 or 5 minutes). In the SoundLearning, these data points are paired with the input level, which is simultaneously recorded.
- Event-Based: A data point is recorded every time a specific event occurs, such as when the user adjusts the volume control. With SoundLearning 2.0, these volume (and frequency response) changes are then paired with the input level and the listening situation.

Figure 3. Percent-correct identification of four different signal classes for the Siemens BestSound technology compared to three competitors.

Figure 4. Percent of situations with “comfortable loudness” for the NAL-NL1 and for four different learning algorithms.
In general, event-based learning is better if many different settings must be trained simultaneously (eg, for different situations and levels). For DataLearning (1st Generation), time-based learning is best, as there is no situation-specific learning. With SoundLearning (2nd Generation), which learns level-specific preferences, there is no significant difference between these two approaches. SoundLearning 2.0 learns specific preferences for both different levels and situations, and thus, event-based learning is most appropriate here.
The Siemens trainable hearing aids have been developed and advanced over the past several years. Numerous research studies have been conducted to support this technology, three of which are described below.
Study 1: Accuracy of Situation Detection
In order to learn gain settings reliably for different listening situations, reliable situation detection is essential. Situation detection algorithms are not new to hearing aids. Siemens introduced the first situation detection system in 2002. The detected acoustic situation determined the appropriate directional microphone and noise reduction settings so the hearing instrument was always automatically adjusted to the optimal setting for each acoustic situation. In 2004, this technology was refined to become the first binaural situation detection that allowed for synchronous steering of both hearing instruments in a bilateral fitting.
Given the complexities of different sounds, and the inherent limitations of hearing aid acoustic situation detection systems, it cannot be expected that the detection is 100% accurate for all different input types. Typically, the most difficult signal to classify is speech in noise, especially when the “noise” is speech babble.
Flores6 reported on a recent study that compared the Siemens BestSound situation detection system (implemented with SoundLearning 2.0) to similar algorithms in three other premier products from other major manufacturers. Four different sound samples were delivered to each product:
- Speech in quiet;
- Speech in noise;
- Noise; and
- Music.
The speech signals consisted of single male and female talkers; the noise signals consisted of a variety of noises, such as a lawn mower, speech babble, a train, clanging dishes, etc; the speech-in-noise signals were composites of the above two signals; and the music signal consisted of various music genres including classical, jazz, and pop. The experiment setup consisted of hearing instruments mounted on a KEMAR, with four speakers placed equidistant in front, behind, and on the sides in a sound-treated room. Each test signal was continuously played for 8 to 14 hours before data logging information displaying the detected acoustic situation was read out and evaluated.
The results of the study are shown in Figure 3, which displays the “percent correct” for the BestSound processing and the three competitive technologies. These results indicate that different systems seem to be better or worse at detecting certain signals. Competitor 3, for example, was quite good at detecting “noise,” but was poor at detecting “speech-in-noise.” Overall, across the four different sound samples, the Siemens BestSound offered the best acoustic situation detection. Note that BestSound technology in particular is outstanding in music detection—an important prerequisite for effective situation-specific learning.
Study 2: Satisfaction with Loudness for Different Listening Situations
As discussed earlier, one of the goals of a hearing aid fitting is to provide satisfactory aided loudness levels across frequencies for different inputs and listening situations. This often necessitates a compromise with maximizing audibility, and prescriptive fitting methods (eg, NAL-NL1, etc) attempt to take this into account. It would seem, however, that satisfaction with loudness could be enhanced if it could be individualized for each patient through hearing instrument training.
To examine the effects of trainable hearing instruments on improving loudness perceptions, a series of studies was conducted at the National Acoustic Laboratories (NAL). Four different types of training were used:
- DataLearning (overall gain learning),
- Classifier Control Learning (overall gain learning based on acoustic situation),
- SoundLearning (gain, compression, and frequency response learning), and
- SoundLearning 2.0 (gain, compression, and frequency response learning for different listening environments).
Based on the data from these studies, it was possible to estimate the percent of situations with comfortable loudness, and these findings are shown in Figure 4.
As expected, the “average” NAL-NL1 fitting without any training provided satisfactory loudness for about 50% of situations. Prior research has shown that earlier learning algorithms, like DataLearning and SoundLearning, are quite successful in increasing the percentage of situations with comfortable loudness,4,5 and that improvement was also reflected here (Figure 4). The best results, however, were obtained with SoundLearning 2.0, which has the potential to achieve optimum loudness levels for the patients in almost all listening situations (91% satisfaction rate).
Study 3: Real-world Validation
To evaluate the real-world effectiveness of SoundLearning 2.0, a clinical study was recently conducted at the University of Giessen in Germany. The participants (n=14) all had mild-to-moderate downward-sloping hearing losses and were experienced hearing aid users. They were fitted bilaterally with Pure 701 hearing aids, which employed SoundLearning 2.0 via the Siemens ConnexxFit, and they used the hearing aids for 2 weeks in their everyday listening environments. After 2 weeks, trained gain was measured for the three listening situations, and speech intelligibility for quiet and in noise was measured for the trained setting versus the initial ConnexxFit.

Figure 5. Learned gain (deviation for Siemens FirstFit) after 2 weeks for both speech and noise listening conditions. Average results are shown for both 40 and 90 dBSPL input levels.

Figure 6. Speech intelligibility in quiet after initial fitting and after 2 weeks of learning. Medians (x), interquartile ranges (boxes), and minimum and maximum values (solid lines) are shown for both conditions.

Figure 7. SoundLearning 2.0 screen under the Learning/Logging dialog.

Figure 8. Gain Preferences tab in the dialog screen. Learning has occurred for the situations of noise (1b) and music (1c), as indicated by the exclamation point (!).
Datalogging results show that, on average, the participants were in speech 59% of the time, noise 38%, and music only 3%. Because the time spent in music was minimal, training was minimal, so we’ll focus only on the speech and noise findings here. Figure 5 shows the gain training for speech and noise for the four different frequency bands, for soft, average, and loud inputs. Observe that gain was increased for most inputs for all bands, with the greatest increase for soft inputs in the lower frequencies.
An interesting finding is that gain was also trained “up” for soft noise inputs. While we usually do not think of hearing aid users wanting noise to be louder, we speculate that the effective digital noise reduction algorithms of the hearing aids simply made soft environmental noise “too soft”; increasing it slightly made it seem more “normal,” or perhaps made it sound more similar to what the participants were used to with their own instruments.
Speech recognition testing was conducted before and after training. As shown in Figure 6, the optimization of the fitting provided through SoundLearning 2.0 significantly improved speech intelligibility by about 20% (p < 0.001). This is consistent with, and due at least in part to, the overall increase in gain for soft speech following training. This improvement in speech recognition was observed for all subjects who trained their hearing aids more than 3 dB.
Subjective measures also revealed greater satisfaction with the trained setting in 1) Loudness for speech in quiet, and 2) Sound quality for both noisy environments and speech in quiet. For speech quality, there were some participants who preferred the original ConnexxFit; however, 75% to 85% of the participants either preferred the trained setting, or did not notice a significant difference.
Using the System
SoundLearning 2.0 (Figure 7) is accessible under the Learning/Logging dialog in the Universal Program. Programs 2 and 3 support SoundLearning 1.0. When “activate SoundLearning 2.0” is checked, the Universal Program automatically learns independent setting preferences for Speech, Noise, and Music.
After the patient has worn the instruments for a certain time, the SoundLearning 2.0 dialog shows logged information, such as wearing time, microphone, and Speech and Noise Management usage for each selected Program. More interestingly, the Acoustical Environment section shows the percentage of times the patient has been hearing speech, noise, and music. This percentage is also reflected in the Usage Analysis pie chart.
It is then possible to click on the Gain Preferences tab to see learned gain settings for each of the three situations or classes under the Universal Program. When learning has occurred for one of the three situations, an exclamation point (!) will be displayed in the respective situation on the pie chart (Figure 8). Learned values can be displayed as gain curves or as channel gain. The dispensing professional has the option to apply learned settings automatically. If learned settings are not automatically applied, there is the option to apply the learned gain to all classes, or to reset one or all three classes back to the original settings prior to the learning period. Optimal learned settings for all three classes should be arrived after approximately 2 weeks.
How to Demonstrate the System to Your Patients
Because the “learning period” for the hearing aid occurs over a relatively long period (eg, >2 weeks), it is not a concept that can be easily demonstrated to the patient during the traditional counseling and fitting/orientation sessions. It is possible, however, to demonstrate to patients the benefit of having three separate settings for different acoustic situations.
To do this, we recommend using the Audibility page of the Real Time Display to demonstrate the advantage of SoundLearning 2.0. This can be easily accomplished by setting up two programs in the hearing instrument: one Universal and one Music. Have the patient wear the instrument, and first show the Audibility page for the Music program. Play a series of sound files with speech, music, and noise. Explain that, in Program 2, there is only one gain setting. Therefore, regardless of the sounds played, the hearing aid responds the same way, and the speech and noise sounds may be sub-optimal.
Next, switch to the Universal Program and show the Audibility page again. Play the same sound file. Unlike the other programs, in the Universal Program, gain settings change according to the detected acoustic situation. Explain to the patient that, depending on the sounds being played, the Universal Program adjusts its settings accordingly so that the speech is intelligible, the music is pleasant, and the noise is not uncomfortable. These adjustments are also reflected in the gain channels on the Audibility page. Alternatively, Select “Use Presets” in the SoundLearning 2.0 dialog. This allows the hearing instrument to automatically apply some predetermined presets for the three different sound classes (as if some learning has already taken place).
Once the patient understands the advantages of having different settings for different acoustic situations, explain that the settings currently in the instrument are presets or starting points. When the patient uses the hearing instruments on a daily basis, the instruments will automatically adapt these presets to match individual preferences for these different listening situations.
Summary
It is well documented that prescribed fitting approaches—both generic and manufacturer specific—usually have to be adjusted for individual users. There is no better way to do this than through the use of trainable hearing aids in the patient’s real-world listening conditions.
We have observed many advances in trainable hearing aids over the past few years, and some of the early limitations of this technology have been overcome. Today, we have products that not only adjust for frequency response and gain for different input levels, but also can make these adjustments independently for specific listening situations. Through training, the patient has automatic adaptation to the preferred gain. It then follows that, when the optimum adjustment is obtained for these different listening conditions, improved hearing aid satisfaction will result.
Correspondence can be addressed to HR at [email protected] or Thomas Powers, PhD, at .
References
- Keidser G, Dillon H. What’s new in prescriptive fittings down under? In: Palmer C, Seewald R, eds. Hearing Care for Adults 2006. Staefa, Switzerland: Phonak AG; 2007:133-142.
- Dillon H, Zakis JA, McDermott H, Keidser G, Dreschler W, Convery E. The trainable hearing aid: what will it do for clients and clinicians? Hear Jour. 2006;59(4):30.
- Keidser G, Convery E, Dillon H. Potential users and perception of a self-adjustable and trainable hearing aid: a consumer survey. Hearing Review. 2007;14(4):18-31.
- Mueller HG, Hornsby BY, Weber J. Using trainable hearing aids to examine real-world preferred gain. J Am Acad Audiol. 2008;19:758-73.
- Mueller HG. Selection and verification of hearing aid gain and output. Paper presented at: Modern Developments in Audiology; May 16, 2009; Nashville, Tenn.
- Flores A. A new generation of trainable hearing aids. Presented at: Annual Convention of the American Academy of Audiology; April 2010; San Diego .